Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Memory Subsystem: Bandwidth
Measuring the full bandwidth potential with John McCalpin's Stream bandwidth benchmark is getting increasingly difficult on the latest CPUs, as core and memory channel counts have continued to grow. We compiled the stream 5.10 source code with the Intel compiler (icc) for linux version 17, or GCC 5.4, both 64-bit. The following compiler switches were used on icc:
icc -fast -qopenmp -parallel (-AVX) -DSTREAM_ARRAY_SIZE=800000000
Notice that we had to increase the array significantly, to a data size of around 6 GB. We compiled one version with AVX and one without.
The results are expressed in gigabytes per second.
Meanwhile the following compiler switches were used on gcc:
-Ofast -fopenmp -static -DSTREAM_ARRAY_SIZE=800000000
Notice that the DDR4 DRAM in the EPYC system ran at 2400 GT/s (8 channels), while the Intel system ran its DRAM at 2666 GT/s (6 channels). So the dual socket AMD system should theoretically get 307 GB per second (2.4 GT/s* 8 bytes per channel x 8 channels x 2 sockets). The Intel system has access to 256 GB per second (2.66 GT/s* 8 bytes per channel x 6 channels x 2 sockets).
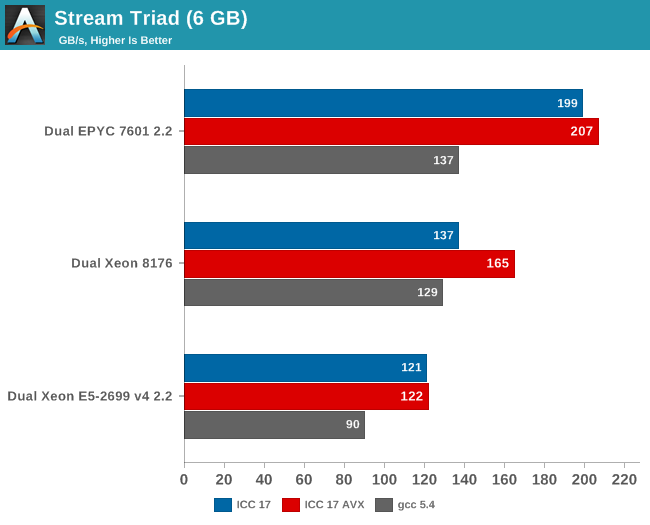
AMD told me they do not fully trust the results from the binaries compiled with ICC (and who can blame them?). Their own fully customized stream binary achieved 250 GB/s. Intel claims 199 GB/s for an AVX-512 optimized binary (Xeon E5-2699 v4: 128 GB/s with DDR-2400). Those kind of bandwidth numbers are only available to specially tuned AVX HPC binaries.
Our numbers are much more realistic, and show that given enough threads, the 8 channels of DDR4 give the AMD EPYC server a 25% to 45% bandwidth advantage. This is less relevant in most server applications, but a nice bonus in many sparse matrix HPC applications.
Maximum bandwidth is one thing, but that bandwidth must be available as soon as possible. To better understand the memory subsystem, we pinned the stream threads to different cores with numactl.
| Pinned Memory Bandwidth (in MB/sec) | |||
| Mem Hierarchy |
AMD "Naples" EPYC 7601 DDR4-2400 |
Intel "Skylake-SP" Xeon 8176 DDR4-2666 |
Intel "Broadwell-EP" Xeon E5-2699v4 DDR4-2400 |
| 1 Thread | 27490 | 12224 | 18555 |
| 2 Threads, same core same socket |
27663 | 14313 | 19043 |
| 2 Threads, different cores same socket |
29836 | 24462 | 37279 |
| 2 Threads, different socket | 54997 | 24387 | 37333 |
| 4 threads on the first 4 cores same socket |
29201 | 47986 | 53983 |
| 8 threads on the first 8 cores same socket |
32703 | 77884 | 61450 |
| 8 threads on different dies (core 0,4,8,12...) same socket |
98747 | 77880 | 61504 |
The new Skylake-SP offers mediocre bandwidth to a single thread: only 12 GB/s is available despite the use of fast DDR-4 2666. The Broadwell-EP delivers 50% more bandwidth with slower DDR4-2400. It is clear that Skylake-SP needs more threads to get the most of its available memory bandwidth.
Meanwhile a single thread on a Naples core can get 27,5 GB/s if necessary. This is very promissing, as this means that a single-threaded phase in an HPC application will get abundant bandwidth and run as fast as possible. But the total bandwidth that one whole quad core CCX can command is only 30 GB/s.
Overall, memory bandwidth on Intel's Skylake-SP Xeon behaves more linearly than on AMD's EPYC. All off the Xeon's cores have access to all the memory channels, so bandwidth more directly increases with the number of threads.








219 Comments
View All Comments
Panxa - Sunday, July 16, 2017 - link
"Competition has spoiled the naming convention Intels 14 === competetions 7 or 10"The node naming convention used to be the gate length, however that has become irrelevant. Intel 14 nm gate lenghth is about 1.5x and 10 nm about 1.8x. Companies and organizations have developed quite accurate models to asses process density with equations based on process poarameters like CPP and MPP to what they call a "standard node"
"Intel used to maintain 2 year lead now grew that to 3-4year lead"
Don't belive intel propaganda. Intel takes the lead in 2014 with their 14nm process with a standard node value of 12.1. Samsung and then TSMC take the lead in 2017 with their 10nm processes having standard node values of 11.2 and 10.3 respectively. Intel will retake the the lead back when they deliver their 10nm process with a standard node value of 8.3. However it will be a short lived lead, TSMC will retake the lead back with their 7nm with a standard node of 7.9 before GLOBALFOUNDRIES takes the lead in 2018 with their 7nm process with a standard node value of 7.8. The gap is gone !!!
"yet their revenue profits grow year over year"
Wrong. Intel revenue for the last years remained fairly constant
2011 grow
2012 decline
2013 decline
2014 grow
2015 decline
2016 grow
All in all from 2011 to 2016 revenue went from 54 billion to 59 billion. If we take into account inflation $54 billion in the year 2011 is worth $58.70 billion today.
Not to mention that Samsung has overtaken Intel to become the world No.1 semiconductor company, and that a "pure play" foundry like TSMC has surpassed intel in market CAP
johnp_ - Wednesday, July 12, 2017 - link
The Xeon Bronze Table on Page 7 seems to have an error. It lists the 4112 as having 5.50MB L3, but ark says it has 8.25MB, just like the 3104, so it looks like it has an above-average L3/Core:https://ark.intel.com/products/123551
Ian Cutress - Friday, July 14, 2017 - link
I've got Intel documents from our briefings that say it has the regular 1.375MB/core allocation, and others saying it has 8.25MB. I'm double checking.johnp_ - Friday, July 21, 2017 - link
All commercial listings and most reviews I've seen online show the processor with 8.25MB as well.Do you have any further information from Intel?
pepoluan - Wednesday, July 12, 2017 - link
What I'm dying to know: Performance when running as virtualization host. Using Xen, VMware, and Hyper-V.Threska - Saturday, July 22, 2017 - link
Virtualization itself, and more importantly virtualization security.Sparkyman215 - Wednesday, July 12, 2017 - link
Typo here: Intel will seven different versions of the chipset, varying in 10G and QAT support, but also varying in TDP:tmbm50 - Wednesday, July 12, 2017 - link
One thing to consider when considering value is the Microsoft Server 2016 core tax.....assuming your mission critical apps are still tied to MS ;-)Server 2016 now chargers per core with an 8 core socket as the base. The Window license for a 32 core server is NUTS.
I'm surprised AMD and Intel are not pushing Microsoft on this. For datacenters like ourselves its pushing us to 8 core sku's with more 2U nodes.
msroadkill612 - Wednesday, July 12, 2017 - link
Aye, its a fuuny world lad.The way the automobile panned out differently in different countries, was laargely die to fuel tax regimes, rather than technology.
i.e. what is the best way to cheat a bit on the incumbent tax rules of germany/france/uk vs a more laissez faire USA. In UK, u were taxed on horsepower, but u could cheat a bit w/ hi revs & more gears - that sort of thing.
rahvin - Wednesday, July 12, 2017 - link
Who runs any Windows service on bare metal these days? If you haven't virtulalized your windows servers running on KVM you should.