Intel Announces Skylake-X: Bringing 18-Core HCC Silicon to Consumers for $1999
by Ian Cutress on May 30, 2017 3:03 AM ESTAnnouncement Three: Skylake-X's New L3 Cache Architecture
(AKA I Like Big Cache and I Cannot Lie)
SKU madness aside, there's more to this launch than just the number of cores at what price. Deviating somewhat from their usual pattern, Intel has made some interesting changes to several elements of Skylake-X that are worth discussing. Next is how Intel is implementing the per-core cache.
In previous generations of HEDT processors (as well as the Xeon processors), Intel implemented an three stage cache before hitting main memory. The L1 and L2 caches were private to each core and inclusive, while the L3 cache was a last-level cache covering all cores and that also being inclusive. This, at a high level, means that any data in L2 is duplicated in L3, such that if a cache line is evicted into L2 it will still be present in the L3 if it is needed, rather than requiring a trip all the way out to DRAM. The sizes of the memory are important as well: with an inclusive L2 to L3 the L3 cache is usually several multiplies of the L2 in order to store all the L2 data plus some more for an L3. Intel typically had 256 kilobytes of L2 cache per core, and anywhere between 1.5MB to 3.75MB of L3 per core, which gave both caches plenty of room and performance. It is worth noting at this point that L2 cache is closer to the logic of the core, and space is at a premium.
With Skylake-X, this cache arrangement changes. When Skylake-S was originally launched, we noted that the L2 cache had a lower associativity as it allowed for more modularity, and this is that principle in action. Skylake-X processors will have their private L2 cache increased from 256 KB to 1 MB, a four-fold increase. This comes at the expense of the L3 cache, which is reduced from ~2.5MB/core to 1.375MB/core.
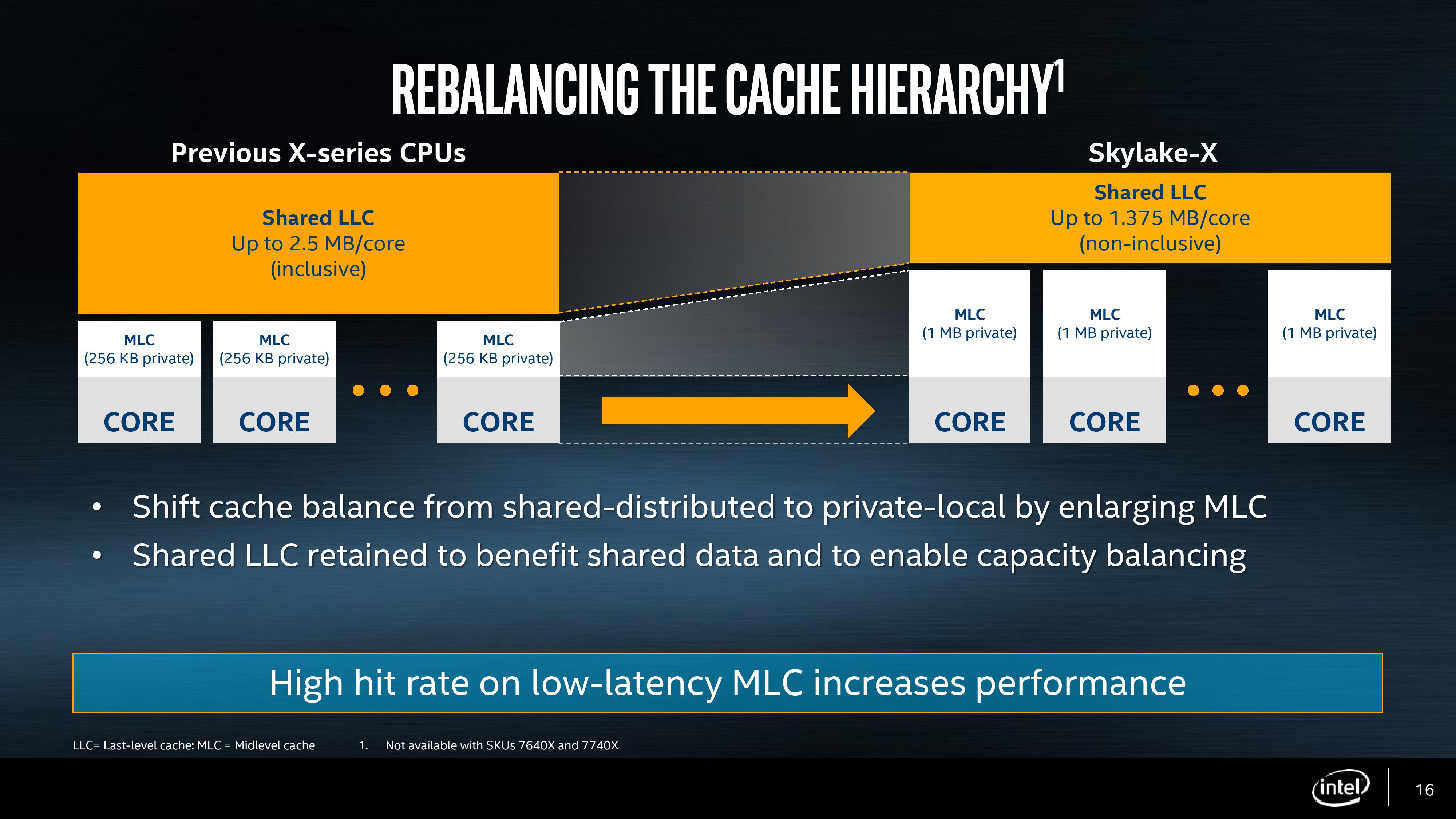
With such a large L2 cache, the L2 to L3 connection is no longer inclusive and now ‘non-inclusive’. Intel is using this terminology rather than ‘exclusive’ or ‘fully-exclusive’, as the L3 will still have some of the L3 features that aren’t present in a victim cache, such as prefetching. What this will mean however is more work for snooping, and keeping track of where cache lines are. Cores will snoop other cores’ L2 to find updated data with the DRAM as a backup (which may be out of date). In previous generations the L3 cache was always a backup, but now this changes.
The good element of this design is that a larger L2 will increase the hit-rate and decrease the miss-rate. Depending on the level of associativity (which has not been disclosed yet, at least not in the basic slide decks), a general rule I have heard is that a double of cache size decreases the miss rate by the sqrt(2), and is liable for a 3-5% IPC uplift in a regular workflow. Thus here’s a conundrum for you: if the L2 has a factor 2 better hit rate, leading to an 8-13% IPC increase, it’s not the same performance as Skylake-S. It may be the same microarchitecture outside the caches, but we get a situation where performance will differ.
Fundamental Realisation: Skylake-S IPC and Skylake-X IPC will be different.
This is something that fundamentally requires in-depth testing. Combine this with the change in the L3 cache, and it is hard to predict the outcome without being a silicon design expert. I am not one of those, but it's something I want to look into as we approach the actual Skylake-X launch.
More things to note on the cache structure. There are many ‘ways’ to do it, one of which I imagined initially is a partitioned cache strategy. The cache layout could be the same as previous generations, but partitions of the L3 were designated L2. This makes life difficult, because then you have a partition of the L2 at the same latency of the L3, and that brings a lot of headaches if the L2 latency has a wide variation. This method would be easy for silicon layout, but hard to implement. Looking at the HCC silicon representation in our slide-deck, it’s clear that there is no fundamental L3 covering all the cores – each core has its partition. That being the case, we now have an L2 at approximately the same size as the L3, at least per core. Given these two points, I fully suspect that Intel is running a physical L2 at 1MB, which will give the design the high hit-rate and consistent low-latency it needs. This will be one feather in the cap for Intel.








203 Comments
View All Comments
n31l - Sunday, June 4, 2017 - link
not sure about that.. I've just done the 'microcode' unlock of a 2695 v3 (x99 single socket system) even with such an old architecture, with all 14 cores fully stressed @3199, no core goes above 50c, they have plenty or room to move on clock rates 'if' they wanted..I think Intel is just trying to find out where 'threadripper' will fit within the market.. worst case.., all they need to do is shift 'families' left bring the E7 to E5 and stop selling E5-16xx (i7 consumer parts) with a Xeon premium (especially now v4's are locked!! How I'll miss E5-1620@4.6 with ECC memory)
Unfortunately, imho, Intel can only deal with AMD in a half-arsed manor, if they wanted they could kill AMD but then they will be broken up for being a monopoly if they do.. damned if you do, damned if you don't..
Personally I'd like to see Nvidia and Intel cross-licencing to 'officially' come to an end and for Nvidia to revive the 'Transmeta x86' IP they bought (but weren't allowed to use due to GPU licence agreement) or maybe for Microsoft to extend what's happening with windows on 'ARM' and just let NVidia lose amongst the pigeons.. or crazier still, as I believe Microsoft still has the 'golden' share option from the xbox days.. how about they buy Nvidia and make a custom 'windows CPU' and take google on head first before it's too late.. ;-)
theuglyman0war - Thursday, June 8, 2017 - link
what do u consider a hedt scenario that doesn't leverage moar cores?Workstation? A workstation creative that doesn't render interactively? Light baking complex radiosity?
If I did not scream at progress bars aLL DAY. I would have no reason to upgrade for years now. I do not see that happening in my lifetime and if I keep screaming at progress bars without relief I will eventually commit bloody criminal solutions perhaps even to my poor suffering soul. Considering 90 percent of my progress bars are wrecked everytime I advance advanced cores...
I wonder what is this hedt market that does not leverage moar cores?
3DVagabond - Monday, June 19, 2017 - link
Nah. They'll just sell their's for $999.Chaitanya - Tuesday, May 30, 2017 - link
Intel desperately scrambling for ideas.mschira - Tuesday, May 30, 2017 - link
$2000?Are they kidding? In what world do they live?
I rather get a dual socket AMD system for the same money. If I would care enough about that many thread performance.
Thank God AMD got their act back together, Intel has gone completely insane.
M.
nevcairiel - Tuesday, May 30, 2017 - link
Considering how much the 10-core BDW-E already cost before, $2000 is actually lower then I would have expected.Notmyusualid - Tuesday, May 30, 2017 - link
@nevcairielAgreed.
ddriver - Tuesday, May 30, 2017 - link
Considering it is actually a xeon they'd sell for 4000$ had there not been the desperate need to save face, 2000$ as expressive as it may be, is quite generous of intel, you know... relative to their standards for generosity...smilingcrow - Tuesday, May 30, 2017 - link
Broadwell-EP 18 Core parts start at under $2,500 so Skylake-EP or whatever it will be called will likely offer more cores per dollar and that is the comparison to be made.Intel can make as many of them as they like so selling them at 'only' $2k to prosumers hardly undermines their business model as it's not as if they will end up in true Workstations/Servers anyway.
I don't see that much financial upside or downside to Intel for HEDT parts over $1K as that's a small market.
But AMD are putting downward price pressure on the sub $1K chips which will hurt more.
Plus the 16 Core AMD part is likely usable in a Workstation/Server with it supporting ECC memory so that is another attack on Intel.
So I think you have missed the mark in giving much emphasis to these re-positioned HCC chips, the play is elsewhere.
theuglyman0war - Thursday, June 8, 2017 - link
I am hoping the $849 16 core threadripper rumor is true. As awesome as that would be it still comes down to benchmarks. A workstation u will b suffering with for 2 or 3 years because it owns now vs the hassle of upgrading the cheaper solution every year that doesn't quite own. Where that line lie with me usually depends on how impressed I am at the time saved rendering extreme complexity. Or how much those core make my pipeline more interactive/productive. The more AMD forces Intel to cannibalize the XEON line the better. Kind of bitter that AMD wasn't more hedt relevant for a while now. Kind of wonder why they did not spend the bucks on the architecture talent for all these years if that's all it took to jump start things like the current excitement. And I haven't been excited like this in a long time.