Intel Announces Skylake-X: Bringing 18-Core HCC Silicon to Consumers for $1999
by Ian Cutress on May 30, 2017 3:03 AM ESTAnnouncement Three: Skylake-X's New L3 Cache Architecture
(AKA I Like Big Cache and I Cannot Lie)
SKU madness aside, there's more to this launch than just the number of cores at what price. Deviating somewhat from their usual pattern, Intel has made some interesting changes to several elements of Skylake-X that are worth discussing. Next is how Intel is implementing the per-core cache.
In previous generations of HEDT processors (as well as the Xeon processors), Intel implemented an three stage cache before hitting main memory. The L1 and L2 caches were private to each core and inclusive, while the L3 cache was a last-level cache covering all cores and that also being inclusive. This, at a high level, means that any data in L2 is duplicated in L3, such that if a cache line is evicted into L2 it will still be present in the L3 if it is needed, rather than requiring a trip all the way out to DRAM. The sizes of the memory are important as well: with an inclusive L2 to L3 the L3 cache is usually several multiplies of the L2 in order to store all the L2 data plus some more for an L3. Intel typically had 256 kilobytes of L2 cache per core, and anywhere between 1.5MB to 3.75MB of L3 per core, which gave both caches plenty of room and performance. It is worth noting at this point that L2 cache is closer to the logic of the core, and space is at a premium.
With Skylake-X, this cache arrangement changes. When Skylake-S was originally launched, we noted that the L2 cache had a lower associativity as it allowed for more modularity, and this is that principle in action. Skylake-X processors will have their private L2 cache increased from 256 KB to 1 MB, a four-fold increase. This comes at the expense of the L3 cache, which is reduced from ~2.5MB/core to 1.375MB/core.
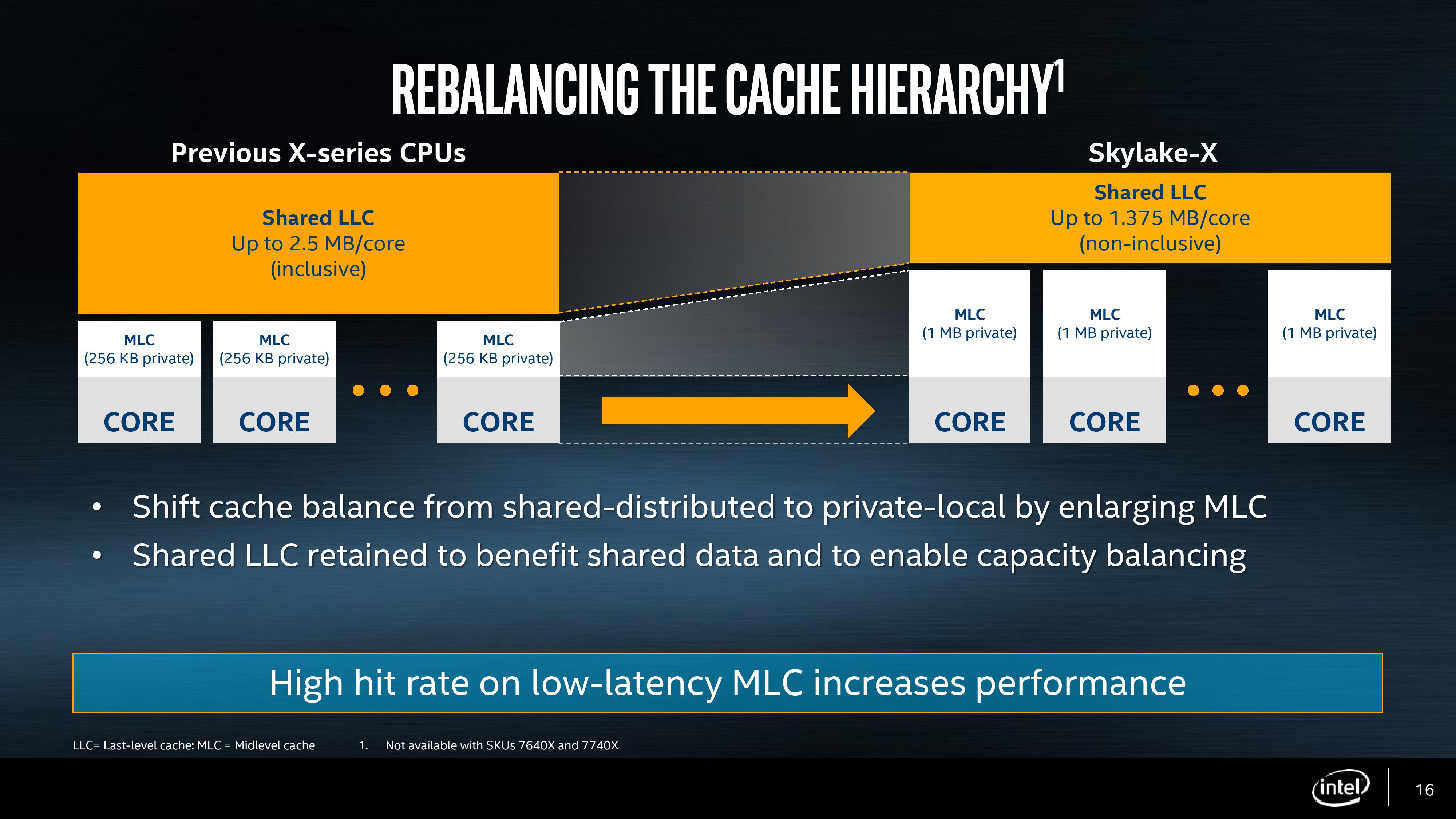
With such a large L2 cache, the L2 to L3 connection is no longer inclusive and now ‘non-inclusive’. Intel is using this terminology rather than ‘exclusive’ or ‘fully-exclusive’, as the L3 will still have some of the L3 features that aren’t present in a victim cache, such as prefetching. What this will mean however is more work for snooping, and keeping track of where cache lines are. Cores will snoop other cores’ L2 to find updated data with the DRAM as a backup (which may be out of date). In previous generations the L3 cache was always a backup, but now this changes.
The good element of this design is that a larger L2 will increase the hit-rate and decrease the miss-rate. Depending on the level of associativity (which has not been disclosed yet, at least not in the basic slide decks), a general rule I have heard is that a double of cache size decreases the miss rate by the sqrt(2), and is liable for a 3-5% IPC uplift in a regular workflow. Thus here’s a conundrum for you: if the L2 has a factor 2 better hit rate, leading to an 8-13% IPC increase, it’s not the same performance as Skylake-S. It may be the same microarchitecture outside the caches, but we get a situation where performance will differ.
Fundamental Realisation: Skylake-S IPC and Skylake-X IPC will be different.
This is something that fundamentally requires in-depth testing. Combine this with the change in the L3 cache, and it is hard to predict the outcome without being a silicon design expert. I am not one of those, but it's something I want to look into as we approach the actual Skylake-X launch.
More things to note on the cache structure. There are many ‘ways’ to do it, one of which I imagined initially is a partitioned cache strategy. The cache layout could be the same as previous generations, but partitions of the L3 were designated L2. This makes life difficult, because then you have a partition of the L2 at the same latency of the L3, and that brings a lot of headaches if the L2 latency has a wide variation. This method would be easy for silicon layout, but hard to implement. Looking at the HCC silicon representation in our slide-deck, it’s clear that there is no fundamental L3 covering all the cores – each core has its partition. That being the case, we now have an L2 at approximately the same size as the L3, at least per core. Given these two points, I fully suspect that Intel is running a physical L2 at 1MB, which will give the design the high hit-rate and consistent low-latency it needs. This will be one feather in the cap for Intel.








203 Comments
View All Comments
shady28 - Tuesday, May 30, 2017 - link
Looks like a marketing stunt to me. I welcome the 6c/12t part, but most applications can't even effectively use 4c/8t processors. It is a complete waste for 99% of buyers and even the remaining 1% are likely to rarely see a benefit.Maleorderbride - Tuesday, May 30, 2017 - link
Your statement just betrays your ignorance and your lack of imagination. Computers are tools for quite a few people, so they will pay considerable sums for better tools which in turn earn them more money.Video editing and 3D work can and will use all cores. While I am not going to claim they are a large percentage of the market, they routinely purchase 8/10 core options. I have quite a few customers running X99 boards with a single E5-2696 V4 dropped in ($1400 on ebay) and it excels in some workflows.
They are not "rarely" use these extra cores--they are using them every single day and it is the primary reason for purchase.
shady28 - Tuesday, May 30, 2017 - link
Lol! The childish insults aside, you think those thoughts you regurgitated are new? Professional video editors make a tiny fraction of a tiny fraction of the market, and if they are smart they aren't using CPUs for much. Most people who profess this 'need' to do 3D video editing are playing anyway, not working. Like I already said, a fraction of a 1% use case.
Common sense says Intel did not release these for the 0.1% of users who might be able to take advantage of it. They released it to make suckers of the other 99.9%. Your comments indicate they are once again succeeding.
Maleorderbride - Wednesday, May 31, 2017 - link
Your post made a claim about 100% of the market. Obviously you over-claimed. You can't edit posts here, so your "like I said," followed by a watered down version of your post is just a transparent attempt to save your ego. Your assumptions about whether people who claim to be video editors are really "working" is irrelevant.As for blaming video professionals for even using a CPU, you obviously are unaware that some codecs are entirely CPU bound when transcoding, and that these professionals (DITs especially) are under pressure to complete transcodes as quickly as possible on location. Every other person there is waiting for them.
Are many things GPU accelerated? Yes, but being "smart" has nothing to do with it. Sometimes one can use those 2x 1080 Ti's, but sometimes you need 18+ cores, or both. But I guess you got me, I'm a "sucker" if I buy the best tool for a job that makes money.
shady28 - Friday, June 2, 2017 - link
First sentence in your post is a lie, else you're reading comprehension is challenged. My first post is just a few lines up, it said :"It is a complete waste for 99% of buyers and even the remaining 1% are likely to rarely see a benefit."
prisonerX - Wednesday, May 31, 2017 - link
You use applications that are highly parallel everyday and you don't even know it. Maleorderbride is right: you're ignorant and unimaginative.Meteor2 - Saturday, June 3, 2017 - link
No shady28 is correct here. People who *truly* need HCC on desktop are a vanishingly small minority. This is about headlines and marketing.Namisecond - Wednesday, May 31, 2017 - link
Welcome to the 1%?helvete - Friday, September 8, 2017 - link
Have you ever tried to run more than one application at a time? /sBulat Ziganshin - Tuesday, May 30, 2017 - link
i can give you details about avx-512 - they are pretty obvious from analysis of skylake execution ports. so1) avx-512 is mainly single-issue. all the avx commands that now are supported BOTH on port 0 & port 1, will become avx-512 commands supported on joined port 0+1
2) a few commands that are supported only on port 5 (this are various bit exchanges), will be also single-issued in avx-512, which still means doubled perfromance - from single-issued avx-256 to single-issued avx-512
3) a few commands that can be issued on any of 3 ports (0,1,5), including booleans and add/sub/cmp - so-lcalled PADD group, will be double-issued in avx-512, so they will get 33% uplift
overall, ports 0&1 will join when executing 512-bit commands, while port 5 is extended to 512-bit operands. joined port 0&1 can execute almost any avx-512 command, except for a bit exchange ones, port 5 can execute bit exchanges and PADD group
when going from sse to avx, intel sacrificed easy of programming for easy of hardware implemenation, resulting in almost fuull lack of commands that can exchane data between upper&lower parts of ymm register. avx-512 was done right, but this means that bit exchange commands require a full 512-bit mesh. so, intel mobed all these commands to port 5 providing full 512 bit implementation, while most remaining commands were moved into ports 0&1 where 512-bit command can be implemented as simple pair of 256-bit ones
lloking at power budgets, it's obvious that simple doubling of execution resources (i.e. support of 512 bit commands instead of 256-bit ones) is impossible. in previous cpu generation, even avx commands increased energy usage by 40%, so it's easy to predict that extending each executed command to 512 bits will require another 80% increase
of course, m/a analysis can't say anything about commands absent in avx2 set, so my guess that predicate register manipulations will also go to port 5, just to make the m/a a bit less asymmetric
also it's easy to predict that in the next generations the first "improvement" will be to add FMAD capability to port 5, further doubling the marketing perfromance figures
finally, their existing 22-core cpus are already perfrom more than SP teraflop, but this time teraflop will go into HEDT class (while 10 broadwell cores at 3 GHz are only 0.9 tflops capable)