The Intel Optane SSD DC P4800X (375GB) Review: Testing 3D XPoint Performance
by Billy Tallis on April 20, 2017 12:00 PM ESTRandom Read
Random read speed is the most difficult performance metric for flash-based SSDs to improve on. There is very limited opportunity for a drive to do useful prefetching or caching, and parallelism from multiple dies and channels can only help at higher queue depths. The NVMe protocol reduces overhead slightly, but even a high-end enterprise PCIe SSD can struggle to offer random read throughput that would saturate a SATA link.
Real-world random reads are often blocking operations for an application, such as when traversing the filesystem to look up which logical blocks store the contents of a file. Opening even an non-fragmented file can require the OS to perform a chain of several random reads, and since each is dependent on the result of the last, they cannot be queued.
Our first test of random read performance looks at the dependence on transfer size. Most SSDs focus on 4kB random access as that is the most common page size for virtual memory systems and it is a common filesystem block size. Maximizing 4kB performance has gotten more difficult as NAND flash has moved to page sizes that are larger than 4kB, and some SSD vendors have started including 8kB random access specifications. It is worth noting that 3D XPoint memory, from a fundamental standpoint, does not impose any inherent block size restrictions on the Optane SSD, but for compatibility purposes the P4800X by default exposes a 512B sector size.
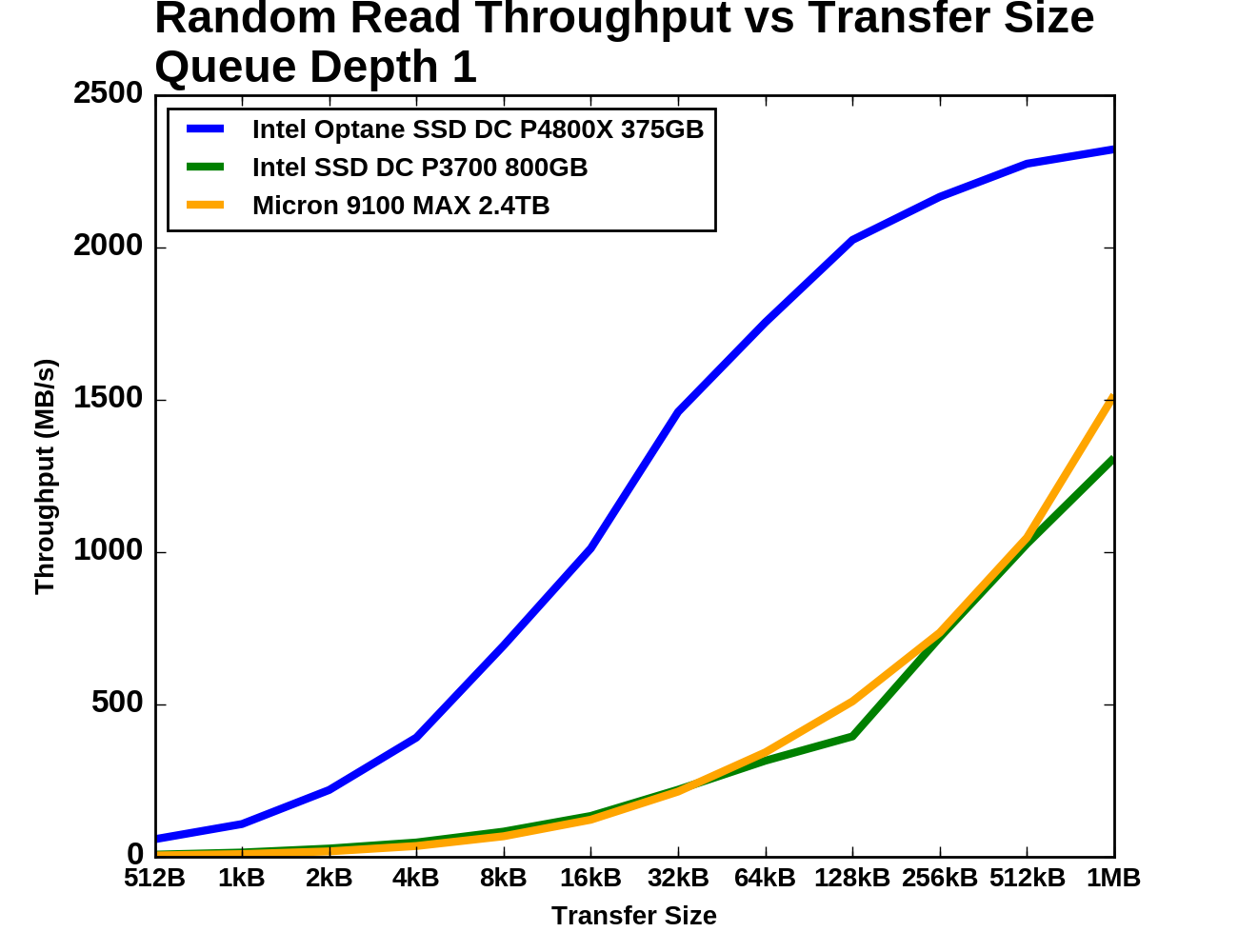
Queue Depth 1
For our test, each transfer size was tested for four minutes and the statistics exclude the first minute. The drives were preconditioned to steady state by filling them with 4kB random writes twice over.
 |
|||||||||
| Vertical Axis scale: | Linear | Logarithmic | |||||||
The Optane SSD starts off with about eight times the throughput of the other drives for small random reads. As the transfer sizes grow past 16kB the Optane SSD's performance starts to level off and the flash SSDs start to catch up, with the Micron 9100 overtaking the Intel P3700. At 1MB transfer size the Optane SSD is only providing an additional 50% higher throughput than the Micron 9100.
Queue Depth >1
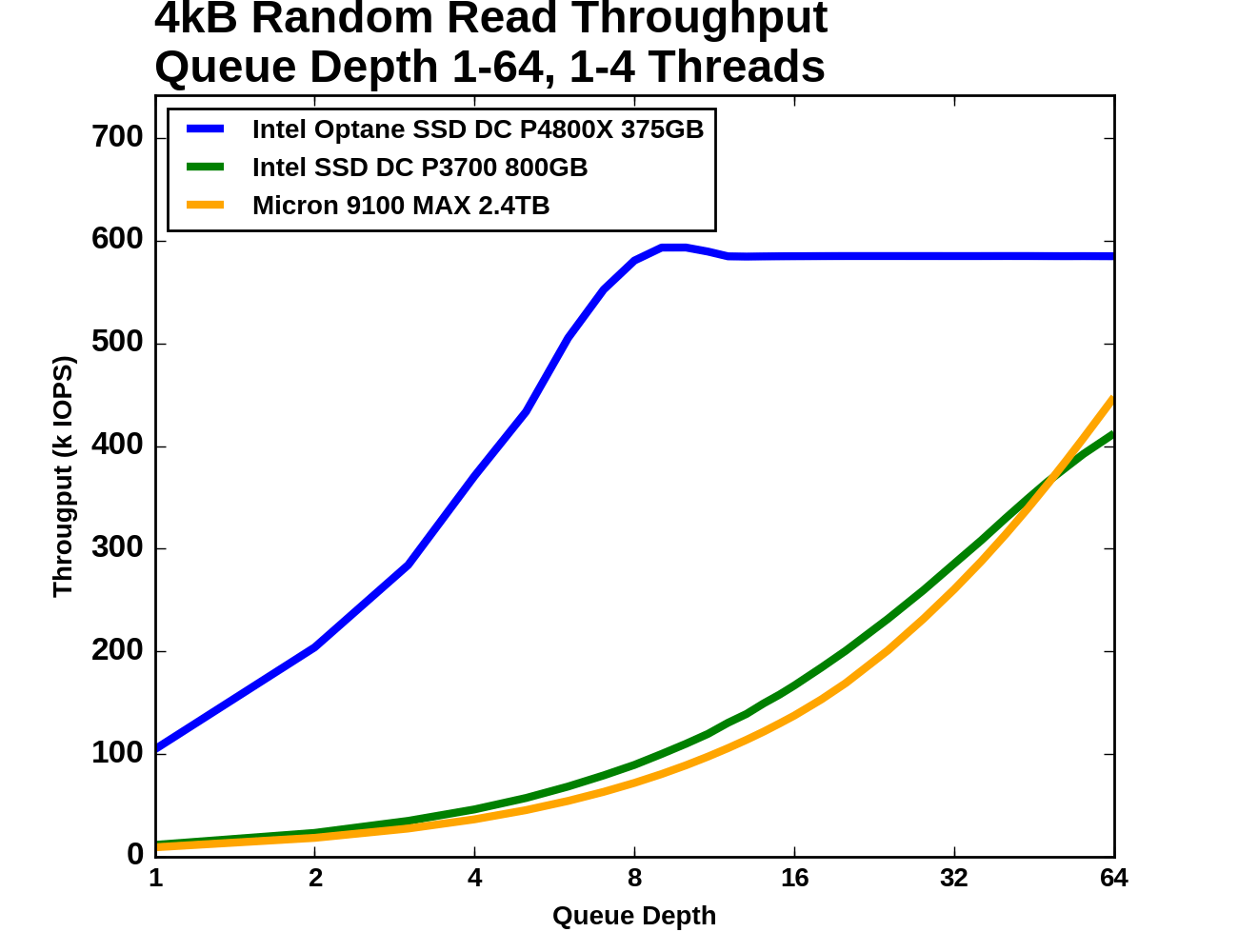
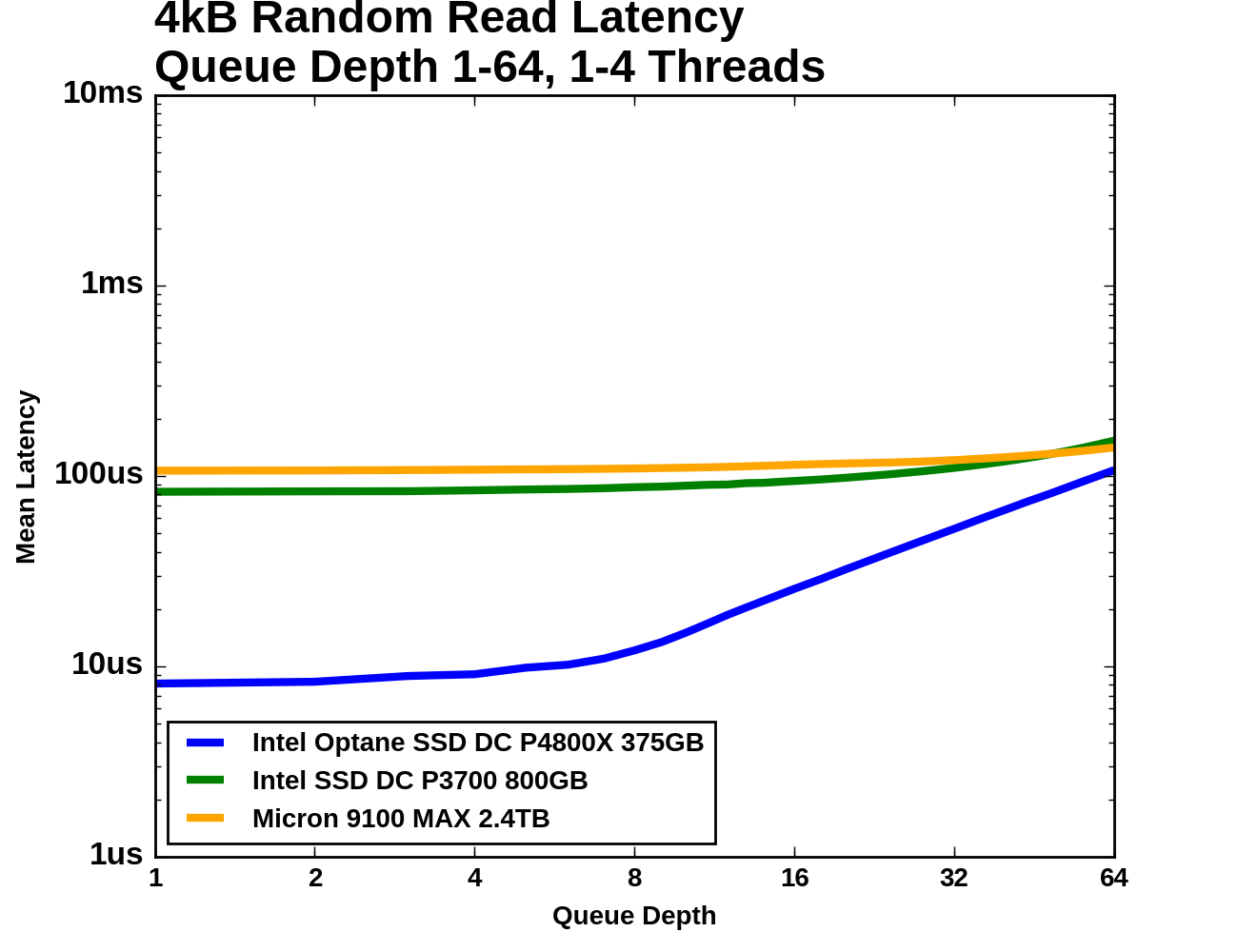
Next, we consider 4kB random read performance at queue depths greater than one. A single-threaded process is not capable of saturating the Optane SSD DC P4800X with random reads so this test is conducted with up to four threads. The queue depths of each thread are adjusted so that the queue depth seen by the SSD varies from 1 to 64, with every single queue depth from 1 through 16, then 18, 20, and factors of four up to 64 (so 24, 28, 32... to 64). The timing is the same as for the other tests: four minutes for each tested queue depth, with the first minute excluded from the statistics.
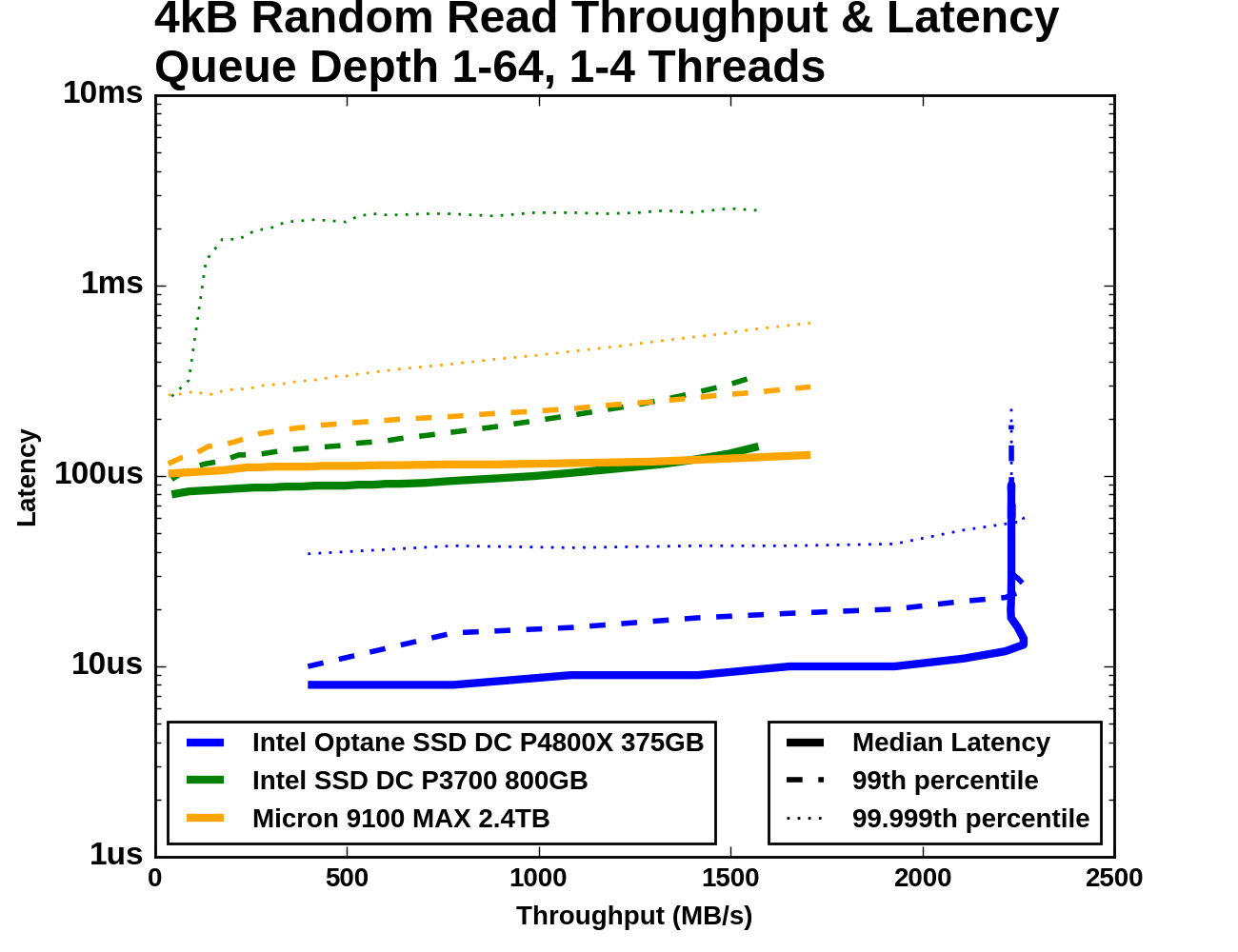
Looking just at the range of throughputs and latencies achieved, it is clear that the Optane SSD DC P4800X is in a different league entirely from the flash SSDs. The Optane SSD saturates part way through the test with a throughput +30% higher than what the Micron 9100 can deliver even at QD64, and at the same time its 99.999th percentile latency is half of the Micron 9100's median latency.
Between the two flash SSDs, the Intel P3700 has better performance on average through most of the test, but its maximum achieved throughput is slightly lower than the Micron 9100's peak and the 9100 offers lower latency at the high end. The Micron 9100 also has much better 99.999th percentile latency across almost the entire range of queue depths.
 |
|||||||||
| Vertical Axis units: | IOPS | MB/s | |||||||
In absolute terms, the Optane SSD's performance is uncontested. Even though the Optane SSD's random read throughput is saturating at QD8, by QD6 it's outperforming what either flash SSD can deliver at any reasonable queue depth. Beyond QD8 the Optane SSD does not deliver even incremental improvement in throughput and increasing queue depth just adds latency. This test stops at QD64, which isn't enough to saturate either flash SSD. The Micron 9100 MAX is rated for a maximum of 750k random read IOPS, but clearly the Optane SSD delivers far better performance at the kinds of queue depths that are reasonably attainable.
 |
|||||||||
| Mean | Median | 99th Percentile | 99.999th Percentile | ||||||
All three SSDs show median latency growing slowly across a wide range of queue depths. At QD1 the 99th percentile curves are very close to the median latency curves, but at high queue depths the 99th percentile latency is around twice the median. For the Optane SSD and the Micron 9100 MAX, the 99.999th percentile latency is higher by another factor of two or so, but the Intel P3700 cannot deliver such tight regulation and its worst-case latencies are well over a millisecond.
Random Write
Flash memory write operations are far slower than read operations. This is not always reflected in the performance specifications of SSDs because writes can be deferred and combined, allowing the SSD to signal completion before the data has actually moved from the drive's cache to the flash memory. The 3D XPoint memory used by the Optane SSD DC P4800X does have slower writes than reads, and it was commented that Intel did not specificy read latency when Optane was initially announced, but our results show that the disparity is not as large. With inherently fast writes and no page size and erase block limitations, the Optane SSD should be far less reliant on write combining and large spare areas to offer high throughput random writes. The drive's translation layer is probably far simpler than what flash SSDs require, potentially giving a latency advantage.
Queue Depth 1
As with random reads, we first examine QD1 random write performance of different transfer sizes. 4kB is usually the most important size, but some applications will make smaller writes when the drive has a 512B sector size. Larger transfer sizes make the workload somewhat less random, reducing the amount of bookkeeping the SSD controller needs to do and generally allowing for increased performance.
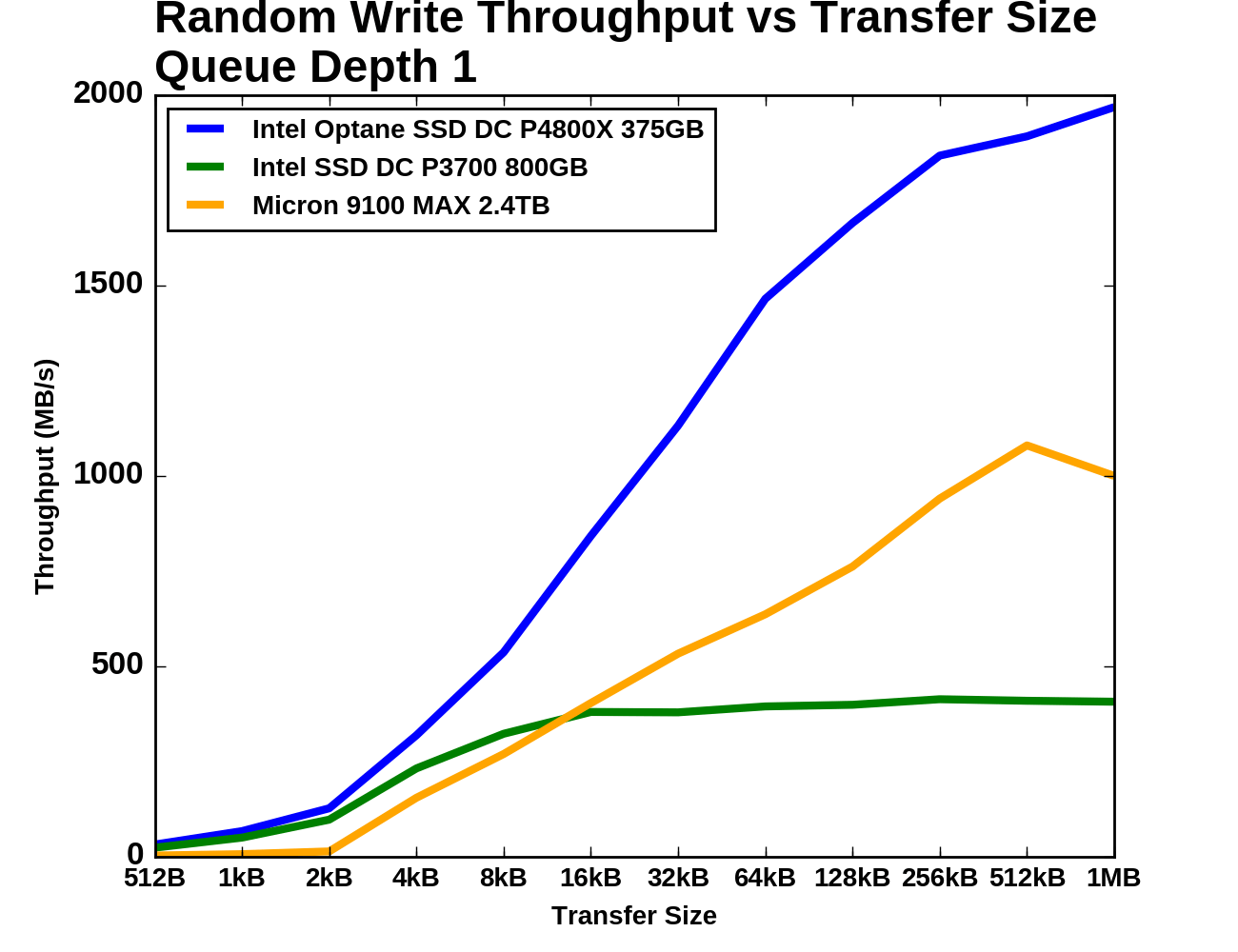 |
|||||||||
| Vertical Axis scale: | Linear | Logarithmic | |||||||
The Micron 9100 really doesn't like random writes smaller than 4kB, but both Intel drives handle it relatively well. The Optane SSD DC P4800X has only a 30% higher throughput result than the P3700 for transfer sizes of 4kB and smaller. The Intel P3700 (owing mainly to its relatively low capacity) doesn't benefit very much as transfer sizes grow beyond 4kB, as it saturates soon after. The Optane SSD maintains a clear lead for transfers of 8kB and larger, averaging about twice the throughput of the Micron 9100 as both show diminishing returns from increased transfer sizes.
Queue Depth >1
The test of 4kB random write throughput at different queue depths is structured identically to its counterpart random write test above. Queue depths from 1 to 64 are tested, with up to four threads used to generate this workload. Each tested queue depth is run for four minutes and the first minute is ignored when computing the statistics.
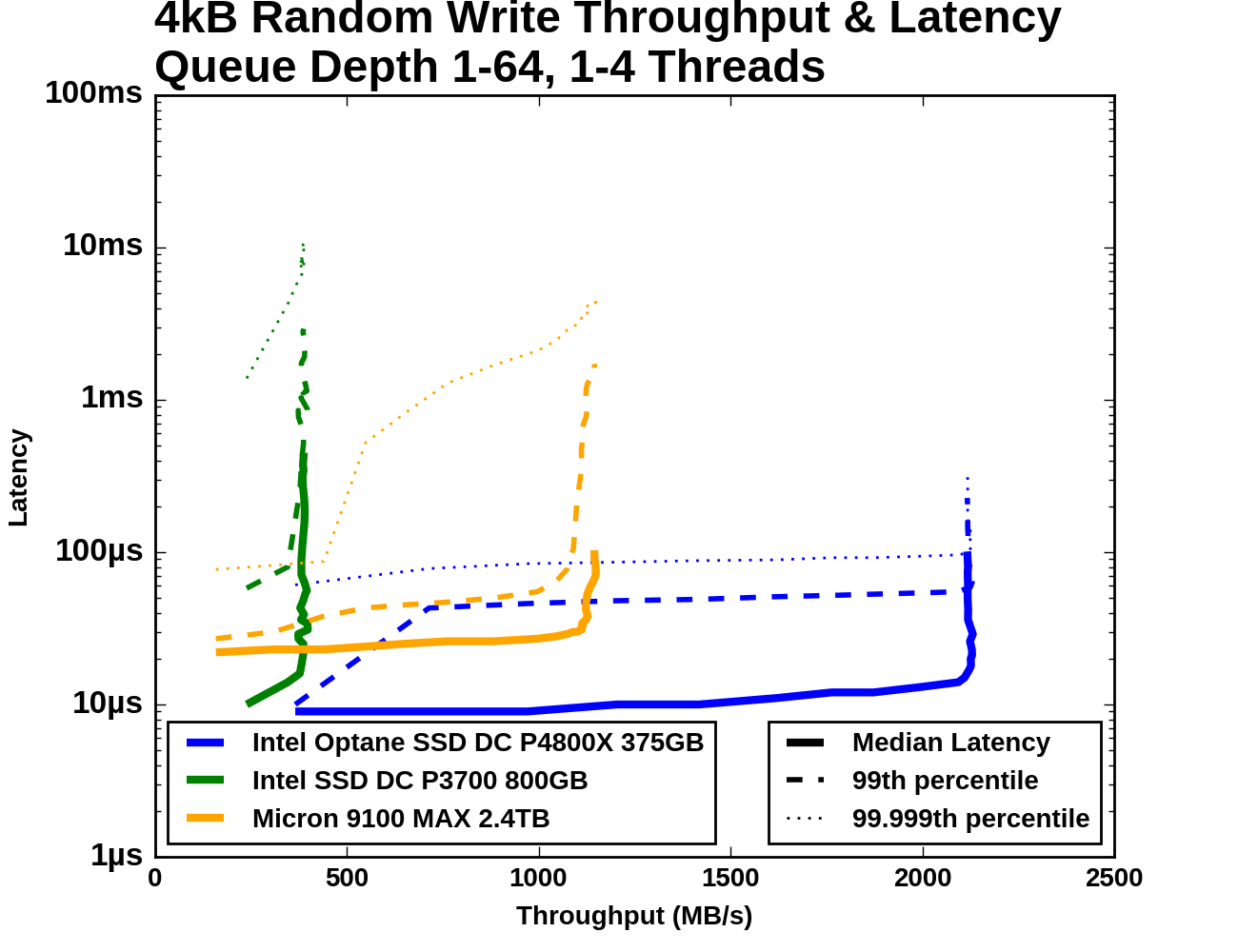
The QD1 starting points for all three drives are somewhat close together, with the fastest drive (the Optane SSD, of course) only offering about twice the random write throughput than the Micron 9100, with less than half the average latency. From there, the gaps widen quickly. The Intel P3700 reaches its maximum throughput very quickly and then the latency just piles up. The Micron 9100 keeps its median and 99th percentile latency reasonably well controlled until reaching its maximum throughput, which is half of what the Optane SSD can deliver.
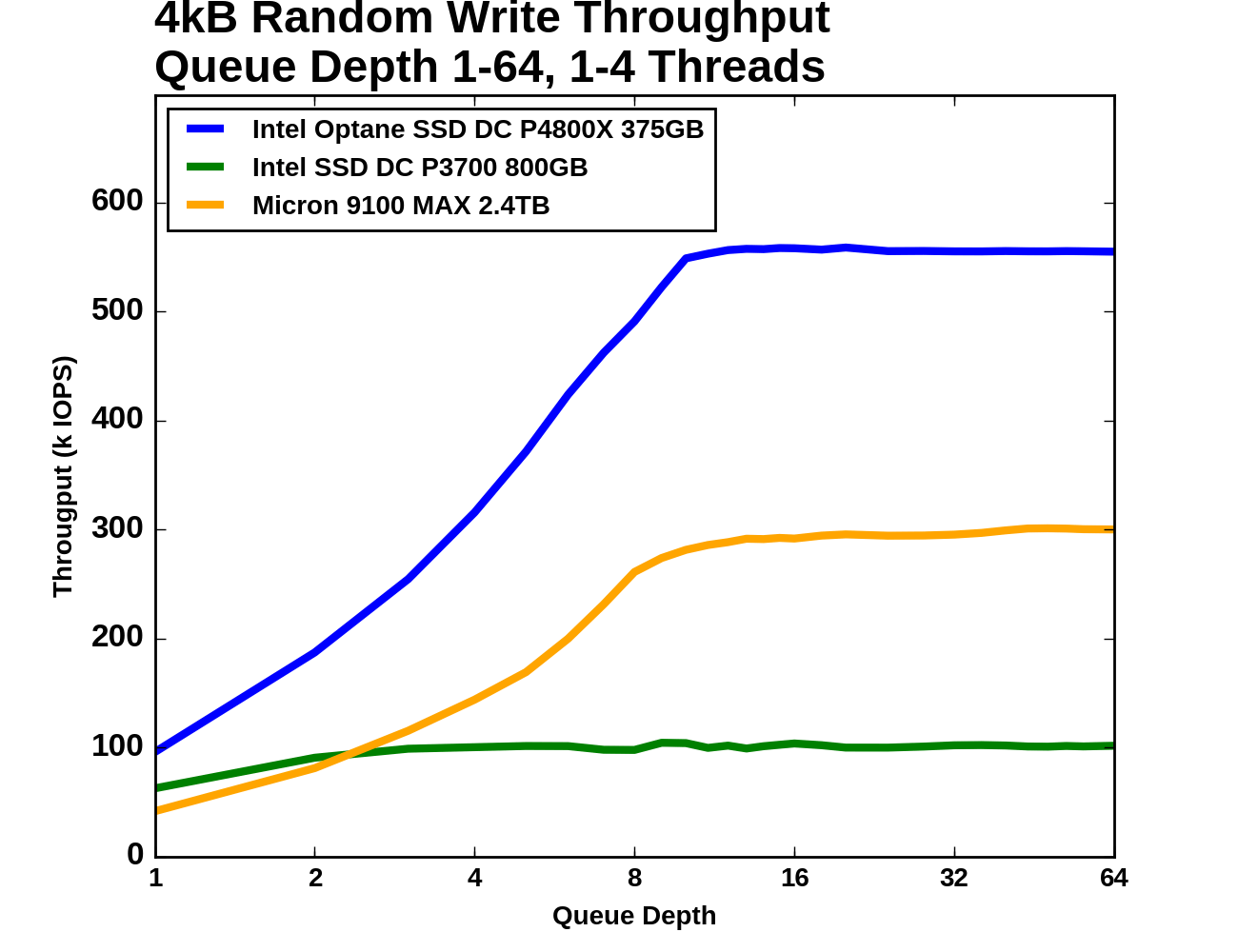 |
|||||||||
| Vertical Axis units: | IOPS | MB/s | |||||||
While QD64 wasn't enough to completely saturate the flash SSDs with random reads, here with random writes, QD8 is enough for any of the drives, and the P3700 is done around QD2. The Micron 9100 starts out as the slowest of the three but soon overtakes the Intel P3700.
When examining the latency statistics, we should keep in mind that all three drives reached their full throughput by QD8. At queue depths higher than that, latency increases with no improvement to throughput. A well-tuned server will generally not be operating the drives in that regime, so the right half of these graphs can be mostly ignored.
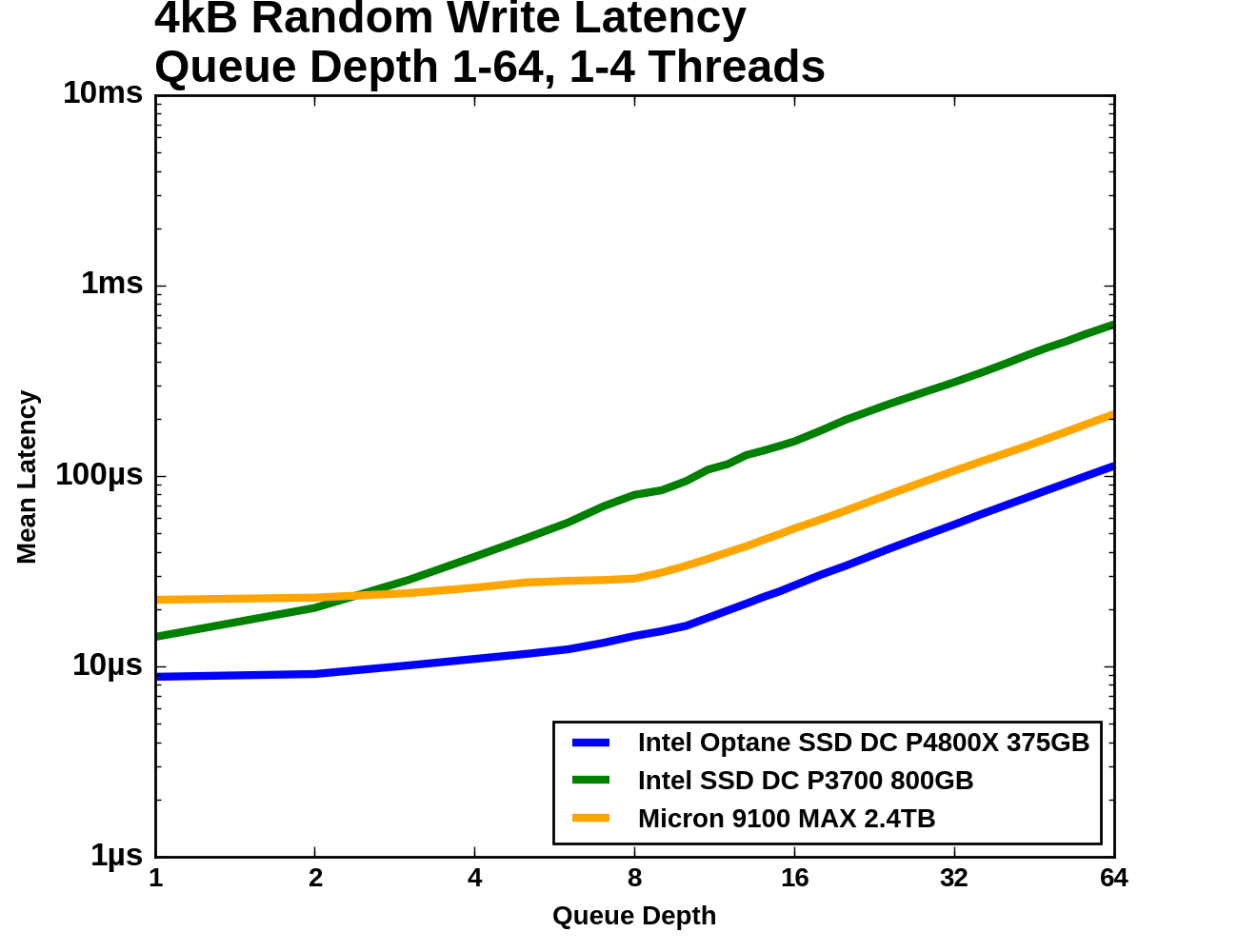 |
|||||||||
| Mean | Median | 99th Percentile | 99.999th Percentile | ||||||
Median latency for these drives is quite flat until they reach saturation. 99th percentile latency for the flash SSDs shoots up when they're operated at unnecessarily high queue depths. The 99.999th percentile latency of the Intel P3700 is never less than 1ms and actually exceeds 10ms at the end of the test. The Micron 9100's 99.999th percentile latency is fairly close to that of the Optane SSD until the 9100 hits QD4, where it spikes and surpasses 1ms shortly before the drive reaches full throughput. Meanwhile, the Optane SSD's 99.999th percentile latency only climbs up to a third of a millisecond even at QD64.








117 Comments
View All Comments
ddriver - Friday, April 21, 2017 - link
*450 ns, by which I mean lower by 450 ns. And the current xpoint controller is nowhere near hitting the bottleneck of PCIE. It would take a controller that is at least 20 times faster than the current one to even get to the point where PCIE is a bottleneck. And even faster to see any tangible benefit from connecting xpoint directly to the memory controller.I'd rather have some nice 3D SLC (better than xpoint in literally every aspect) on PCIE for persistent storage RAM in the dimm slots. Hyped as superior, xpoint is actually nothing but a big compromise. Peak bandwidth is too low even compared to NVME NAND, latency is way too high and endurance is way too low for working memory. Low queue depths performance is good, but credit there goes to the controller, such a controller will hit even better performance with SLC nand. Smarter block management could also double the endurance advantage SLC already has over xpoint.
mdriftmeyer - Saturday, April 22, 2017 - link
ddriver is spot on. just to clarify an early comment. He's correct and the IntelUser2000 is out of his league.mdriftmeyer - Saturday, April 22, 2017 - link
Spot on.tuxRoller - Friday, April 21, 2017 - link
We don't know how much slower the media is than dram right now.We know than using dram over nvme has similar (though much better worst case) perf to this.
See my other post regarding polling and latency.
bcronce - Saturday, April 22, 2017 - link
Re-reading, I see it says "typical" latency is under 10us, placing it in spitting distance of DDR3/4. It's the 99.9999th percentile that is 60us for Q1. At Q16, 99.999th percentile is 140us. That means it takes only 140us to service 16 requests. That's pretty much the same as 10us.Read Q1 4KiB bandwidth is only about 500MiB/s, but at Q8, it's about 2GiB which puts it on par with DDR4-2400.
ddriver - Saturday, April 22, 2017 - link
"placing it in spitting distance of DDR3/4"I hope you do realize that dram latency is like 50 NANOseconds, and 1 MICROsecond is 1000 NANOseconds.
So 10 us is actually 200 times as much as 50 ns. Thus making hypetane about 200 times slower in access latency. Not 200%, 200X.
tuxRoller - Saturday, April 22, 2017 - link
Yes, the dram media is that fast but when it's exposed through nvme it has the latency characteristics that bcronce described.wumpus - Sunday, April 23, 2017 - link
That's only on a page hit. For the type of operations that 3dxpoint is looking at (4k or so) you won't find it on an open page and thus take 2-3 times as long till it is ready.That still leaves you with ~100x latency. And we are still wondering if losing the PCIe controller will make any significant difference to this number (one problem is that if Intel/Micron magically fixed this, the endurance is only slightly better than SLC and would quickly die if used as main memory).
ddriver - Sunday, April 23, 2017 - link
Endurance for the initial batch postulated from intel's warranty would be around 30k PE cycles, and 50k for the upcoming generation. That's not "only slightly better than SLC" as SCL has 100k PE cycles endurance. But the 100k figure is somewhat old, and endurance goes down with process node. So at a comparable process, SLC might be going down, approaching 50k.It remains to be seen, the lousy industry is penny pinching and producing artificial NAND shortages to milk people as much as possible, and pretty much all the wafers are going into TLC, some MLC and why oh why, QLC trash.
I guess they are saving the best for last. 3D SLC will address the lower density, samsung currently has 2 TB MLC M2, so 1 TB is perfectly doable via 3D SLC. I am guessing samsung's z-nand will be exactly that - SLC making a long overdue comeback.
tuxRoller - Sunday, April 23, 2017 - link
The endurance issue is, imho, the biggest concern right now.