The AMD Zen and Ryzen 7 Review: A Deep Dive on 1800X, 1700X and 1700
by Ian Cutress on March 2, 2017 9:00 AM ESTBenchmarking Performance: CPU Web Tests
One of the issues when running web-based tests is the nature of modern browsers to automatically install updates. This means any sustained period of benchmarking will invariably fall foul of the 'it's updated beyond the state of comparison' rule, especially when browsers will update if you give them half a second to think about it. Despite this, we were able to find a series of commands to create an un-updatable version of Chrome 56 for our 2017 test suite. While this means we might not be on the bleeding edge of the latest browser, it makes the scores between CPUs comparable.
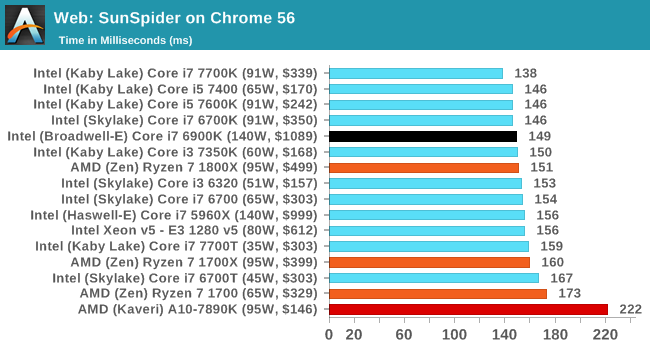
SunSpider 1.0.2 [link]
The oldest web-based benchmark in this portion of our test is SunSpider. This is a very basic javascript algorithm tool, and ends up being more a measure of IPC and latency than anything else, with most high performance CPUs scoring around about the same. The basic test is looped 10 times and the average taken. We run the basic test 4 times.
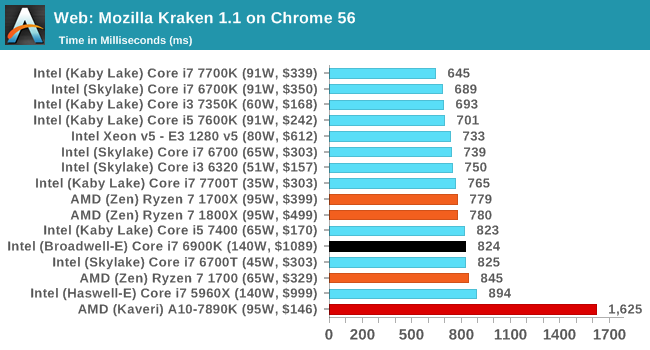
Mozilla Kraken 1.1 [link]
Kraken is another Javascript based benchmark, using the same test harness as SunSpider, but focusing on more stringent real-world use cases and libraries, such as audio processing and image filters. Again, the basic test is looped ten times, and we run the basic test four times.
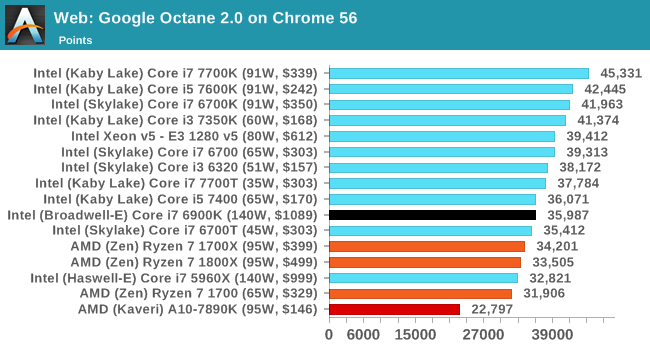
Google Octane 2.0 [link]
Along with Mozilla, as Google is a major browser developer, having peak JS performance is typically a critical asset when comparing against the other OS developers. In the same way that SunSpider is a very early JS benchmark, and Kraken is a bit newer, Octane aims to be more relevant to real workloads, especially in power constrained devices such as smartphones and tablets.
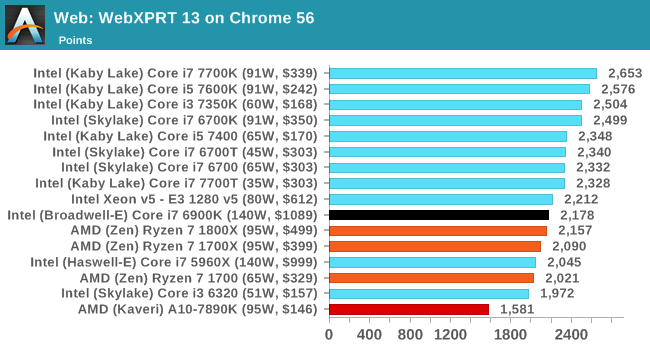
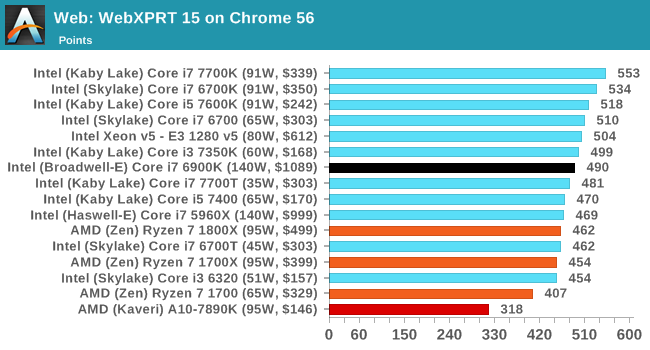
WebXPRT 2013 and 2015 [link]
While the previous three benchmarks do calculations in the background and represent a score, WebXPRT is designed to be a better interpretation of visual workloads that a professional user might have, such as browser based applications, graphing, image editing, sort/analysis, scientific analysis and financial tools. Web2013 is the older tool, superceded by Web2015, however both still are highly relevant for high-performance web applications today.








574 Comments
View All Comments
nt300 - Saturday, March 11, 2017 - link
If AMD hadn't gone with GF's 14nm process, ZEN would probably have been delayed. I think as soon as Ryzen Optimizations come out, these chips will further outperform.MongGrel - Thursday, March 9, 2017 - link
For some reason making a casual comment about anything bad about the chip will get you banned at the drop of a hat on the tech forums, and then if you call him out they will ban you more.
https://arstechnica.com/gadgets/2017/03/amds-momen...
MongGrel - Thursday, March 9, 2017 - link
For some reason, MarkFW seems to thinks he is the reincarnation of Kyle Bennet, and whines a lot before retreating to his safe space.nt300 - Saturday, March 11, 2017 - link
I've noticed in the past that AMD has an issue with increasing L3 cache speed and/or Latencies. Hopefully they start tightening the L3 as much as possible. Can Anandtech do a comparison between Ryzen before Optimizations and after Optimizations. Tyalpha754293 - Friday, March 17, 2017 - link
Looks like that for a lot of the compute-intensive benchmarks, the new Ryzen isn't that much better than say a Core i5-7700K.That's quite a bit disappointing.
AMD needs to up their FLOPS/cycle game in order to be able to compete in that space.
Such a pity because the original Opterons were a great value proposition vs. the Intels. Now, it doesn't even come close.
deltaFx2 - Saturday, March 25, 2017 - link
@Ian Cutress: When you do test gaming, if you can, I'd love to have the hypothesis behind the 'generally accepted methodology' tested out. The methodology being, to test it at lowest resolution. The hypothesis is that this stresses the CPU, and that a future, higher performance GPU will be bottlenecked by the slower CPU. Sounds logical, but is it?Here's the thing: Typically, when given more computing resources, people scale up their problem to utilize those resources. In other words, if I give you a more powerful GPU, games will scale up their perf requirements to match it, by doing stuff that were not possible/practical in earlier GPUs. Today's games are far more 'realistic' and are played at much higher resolutions than say 5 years ago. In which case, the GPU is always the limiting factor no matter what (unless one insists on playing 5 year old games on the biggest, baddest GPU). And I fully expect that the games of today are built to max out current GPUs, so hardware lags software.
This has parallels with what happens in HPC: when you get more compute nodes for HPC problems, people scale up the complexity of their simulations rather than running the old, simplified simulations. Amdahl's law is still not a limiting factor for HPC, and we seem to be talking about Exascale machines now. Clearly, there's life in HPC beyond what a myopic view through the Amdahl law lens would indicate.
Just a thought :) Clearly, core count requirements have gone up over the last decade, but is it true that a 4c/8t sandy bridge paired up with Nvidia's latest and greatest is CPU-bottlenecked at likely resolutions?
wavelength - Friday, March 31, 2017 - link
I would love to see Anand test against AdoredTV's most recent findings on Ryzen https://www.youtube.com/watch?v=0tfTZjugDegLawJikal - Friday, April 21, 2017 - link
What I'm surprised to see missing... in virtually all reviews across the web... is any discussion (by a publication or its readers) on the AM4 platform's longevity and upgradability (in addition to its cost, which is readily discussed).Any Intel Platform - is almost guaranteed to not accommodate a new or significantly revised microarchitecture... beyond the mere "tick". In order to enjoy a "tock", one MUST purchase a new motherboard (if historical precedent is maintained).
AMD AM4 Platform - is almost guaranteed to, AT LEAST, accommodate Ryzen "II" and quite possibly Ryzen "III" processors. And, in such cases, only a new processor and BIOS update will be necessary to do so.
This is not an insignificant point of differentiation.
PeterCordes - Monday, June 5, 2017 - link
The uArch comparison table has some errors for the Intel columns. Dispatch/cycle: Skylake can read 6 uops per clock from the uop cache into the issue queue, but the issue stage itself is still only 4 uops wide. You've labelled Even running from the loop buffer (LSD), it can only sustain a throughput of 4 uops per clock, same 4-wide pipeline width it has been since Core2. (pre-Haswell it has to be a mix of ALU and some store or load to sustain that throughput without bottlenecking on the execution ports.) Skylake's improved decode and uop-cache bandwidth lets it refill the uop queue (IDQ) after bubbles in earlier stages, keeping the issue stage fed (since the back-end is often able to actually keep up).Ryzen is 6-wide, but I think I've read that it can only issue 6 uops per clock if some of them are from "double instructions". e.g. 256-bit AVX like VADDPS ymm0, ymm1, ymm2 that decodes to two separate 128-bit uops. Running code with only single-uop instructions, the Ryzen's front-end throughput is 5 uops per clock.
In Intel terminology, "dispatch" is when the scheduler (aka Reservation Station) sends uops to the execution units. The row you've labelled "dispatch / cycle" is clearly the throughput for issuing uops from the front-end into the out-of-order core, though. (Putting them into the ROB and Reservation Station). Some computer-architecture people call that "dispatch", but it's probably not a good idea in an x86 context. (Unless AMD uses that terminology; I'm mostly familiar with Intel).
----
You list the uop queue size at 128 for Skylake. This is bogus. It's always 64 per thread, with or without hyperthreading. Intel has alternated in SnB/IvB/HSW/SKL between this and letting one thread use both queues as a single big queue. HSW/BDW statically partition their 56-entry queue into two 28-entry halves when two threads are active, otherwise it's a 56-entry queue. (Not 64). Agner Fog's microarch pdf and Intel's optmization manual both confirm this (in Section 2.1.1 about Skylake's front-end improvements over previous generations).
Also, the 4-uop per clock issue width is 4 fused-domain uops, so I was able to construct a loop that runs 7 unfused-domain uops per clock (http://www.agner.org/optimize/blog/read.php?i=415#... with 2 micro-fused ALU+load, one micro-fused store, and a dec/branch. AMD doesn't talk about "unfused" uops because it doesn't use a unified scheduler, IIRC, so memory source operands always stay with the ALU uop.
Also, you mentioned it in the text, but the L1d change from write-through to write-back is worth a table row. IIRC, Bulldozer's L1d write-back has a small buffer or something to absorb repeated writes of the same lines, so it's not quite as bad as a classic write-through cache would be for L2 speed/power requirements, but Ryzen is still a big improvement.