The AMD Zen and Ryzen 7 Review: A Deep Dive on 1800X, 1700X and 1700
by Ian Cutress on March 2, 2017 9:00 AM ESTThe High-Level Zen Overview
AMD is keen to stress that the Zen project had three main goals: core, cache and power. The power aspect of the design is one that was very aggressive – not in the sense of aiming for a mobile-first design, but efficiency at the higher performance levels was key in order to be competitive again. It is worth noting that AMD did not mention ‘die size’ in any of the three main goals, which is usually a requirement as well. Arguably you can make a massive core design to run at high performance and low latency, but it comes at the expense of die size which makes the cost of such a design from a product standpoint less economical (if AMD had to rely on 500mm2 die designs in consumer at 14nm, they would be priced way too high). Nevertheless, power was the main concern rather than pure performance or function, which have been typical AMD targets in the past. The shifting of the goal posts was part of the process to creating Zen.

This slide contains a number of features we will hit on later in this piece, but covers a number of main topics which come under those main three goals of core, cache and power.
For the core, having bigger and wider everything was to be expected, however maintaining a low latency can be difficult. Features such as the micro-op cache help most instruction streams improve in performance and bypass parts of potentially long-cycle repetitive operations, but also the larger dispatch, larger retire, larger schedulers and better branch prediction means that higher throughput can be maintained longer and in the fastest order possible. Add in dual threads and the applicability of keeping the functional units occupied with full queues also improves multi-threaded performance.
For the caches, having a faster prefetch and better algorithms ensures the data is ready when each of the caches when a thread needs it. Aiming for faster caches was AMD’s target, and while they are not disclosing latencies or bandwidth at this time, we are being told that L1/L2 bandwidth is doubled with L3 up to 5x.
For the power, AMD has taken what it learned with Carrizo and moved it forward. This involves more aggressive monitoring of critical paths around the core, and better control of the frequency and power in various regions of the silicon. Zen will have more clock regions (it seems various parts of the back-end and front-end can be gated as needed) with features that help improve power efficiency, such as the micro-op cache, the Stack Engine (dedicated low power address manipulation unit) and Move elimination (low-power method for register adjustment - pointers to registers are adjusted rather than going through the high-power scheduler).
The Big Core Diagram
We saw this diagram last year, showing some of the bigger features AMD wants to promote:
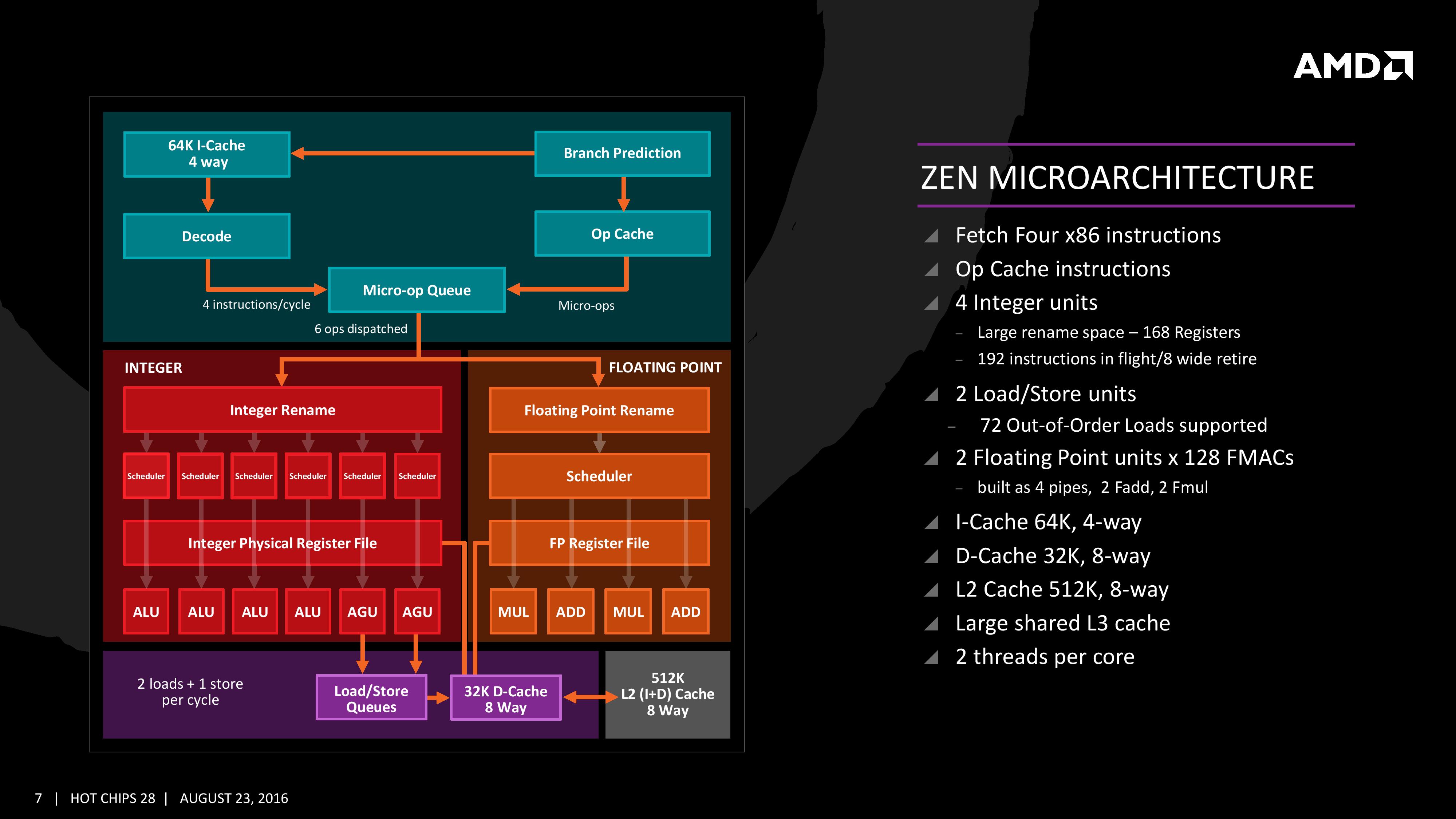
The improved branch predictor allows for 2 branches per Branch Target Buffer (BTB), but in the event of tagged instructions will filter through the micro-op cache. On the other side, the decoder can dispatch 4 instructions per cycle however some of those instructions can be fused into the micro-op queue. Fused instructions still come out of the queue as two micro-ops, but take up less buffer space as a result.
As mentioned earlier, the INT and FP pipes and schedulers are separated, however the INT rename space is 168 registers wide, which feeds into 6x14 scheduling queues. The FP employs as 160 entry register file, and both the FP and INT sections feed into a 192-entry retire queue. The retire queue can operate at 8 instructions per cycle, moving up from 4/cycle in previous AMD microarchitectures.
The load/store units are improved, supporting a 72 out-of-order loads, similar to Skylake. We’ll discuss this a bit later. On the FP side there are four pipes (compared to three in previous designs) which support combined 128-bit FMAC instructions. These can be combined for one 256-bit AVX, but beyond that it has to be scheduled over multiple instructions.








574 Comments
View All Comments
bobsta22 - Saturday, March 4, 2017 - link
Office with 20 PCs - all developers - loads of VMs and containers.All the PCs are due a CPU/Gfx refresh, but ITX mobos required.
Cant wait tbh. This is a game changer.
prisonerX - Saturday, March 4, 2017 - link
What if they come out with a 16 core line next year!bobsta22 - Saturday, March 4, 2017 - link
What?lilmoe - Tuesday, March 7, 2017 - link
It really is. As a freelance developer, I can't wait.ericgl21 - Saturday, March 4, 2017 - link
For me, the more important thing to see from AMD is if they can come up with a chip that can beat the mobile Core i7-7820HQ (4c/8t no ECC) & the Xeon E3-1575M v5 (4c/8t with ECC), for less money.And the number of PCIe gen3 lanes is very important, especially with the rise of M.2 NVMe storage sticks.
cmagic - Sunday, March 5, 2017 - link
Will anandtech review Ryzen in gaming? I would really like Anandtech view, since I don't really trust other sites especially those "entertainment" sites. Want to see how Anandtech dive into its main cause.Tchamber - Sunday, March 5, 2017 - link
@cmagicPage 15
2017 GPU
The bad news for our Ryzen review is that our new 2017 GPU testing stack not yet complete. We recieved our Ryzen CPU samples on February 21st, and tested in the hotel at the event for 6hr before flying back to Europe.
I just ordered my 1700X, I plan to keep it for at least 5 years, as my needs don't change much. My current Intel 6 core is coming up on 7 years old now. I like to buy high end and use it a long time.
Lazlo Panaflex - Monday, March 6, 2017 - link
Same here...probably gonna grab a 1700 at some point and put this here i5-2500 non-k in the kids computer.asH98 - Sunday, March 5, 2017 - link
'''The BIG QUESTION is WHY are the HEDT benchmarks (professional ie Blender) fairer than gaming benchmarks??Bottom line is that CUTTING-EDGE CODING is happening NOW in AI, HPC, data, and AV/AR, game coders because of $$$ are the last to change or learn unless forced (great for NVidia Intel) so most of the game coding is stuck in yesteryear- Bethesda will be the test bed for game coders to move forward
Hence the difference in game benchmarks vs 'professional' (HEDT) benchmarks. Game coders can get stuck using yesterday's code without repercussions and consequences as long as old hardware dominates and there are no incentives to change or learn new skills. The same Cant happen in the Professional area where speed is tantamount to performance and $$$
TheJian - Sunday, March 5, 2017 - link
I hope you're going to test a dozen games at 1080p where most of us run for article #2 and the GAMING article should come in a week not 1/2 year later like 1080/1070 gtx reviews...LOL. As this article just seems like AMD told you "guys, please don't run any games so we can sell some chips to suckers before they figure out games suck". And you listened. No point in testing 1440p or 4k for CPU, and 95% of us run 1920x1200 and BELOW so you should be testing your games there for a CPU test.The fact they are talking Zen2 instead of fixing Zen1 kind of makes me think most of the gaming is NOT going to be fixable.
http://www.legitreviews.com/amd-ryzen-7-1800x-1700...
149fps for 7700 in theif vs. 108 for 1800x? JEEZ. GTA5 again, 163 to 138. Deus ex MD 127 to 103. These are massive losses to Intel's chip and Deus was clearly gpu bound as many of Intel's chips hit the same 127fps including my old 4790k :( OUCH AMD.
https://www.guru3d.com/articles_pages/amd_ryzen_7_...
Tombraider same 7700k vs. 1800x 132fps to 114 (never mind 6850 scoring 140fps). This will probably get worse as we move to 1080ti, vega, nvidia refresh for xmas, Volta, 10nm etc. If you were using a faster gpu the cpus will separate even more especially if people are mostly gaming at 1080p. Even if many move to 1440p, that maybe fixes some games (tombraider is one with 1080 regular that hits a wall at 90fps), but again goes back to major losses as we move to 10nm etc. We get 10nm chips for mobile now and gpus probably next year at 12nm (real? fake 12nm? Either way) and might squeak into 2017 (volta, TSMC). 10nm gpus will likely come 2018 at the latest. Those gpus will make 1440p look like 1080p today surely and cpus will again spread out (and no, we won't all be running 4k then...LOL). You could see cpus smaller than 10nm BEFORE you upgrade your cpu again if you buy this year. That could get pretty ugly if the benchmarks around the web for gaming are not going to improve. One more point you'll likely be looking at GDDR6 (16Gbps probably) for vid cards allowing them to possibly stretch their legs even more if needed. Again, all not good for a gamer here IMHO.
“But Senior Engineer Mike Clark says he knows where the easy gains are for Zen 2, and they're already working through the list”
So maybe no fix in sight for Zen1? Just excuses like "run higher res, and code right guys"...I hope that isn't the best they've got. I could go on about games, but most should get the point. I was going to buy ryzen purely for Handbrake, but I'll need to see motherboard improvements and at least some movement on gaming VERY soon.
One more ouch statement from pcper.
https://www.pcper.com/news/Processors/AMD-responds...
"For buyers today that are gaming at 1080p, the situation is likely to remain as we have presented it going forward."
So they don't think a fix is coming based on AMD info and as noted as gpus get much faster (along with their memory speeds) expect 1440p to look like today's 1080p benchmarks at least to some extent.
The board part is of major interest to me, so I can wait a bit and also see Intel's response. So AMD has be hanging for a bit here, but not for too long. I do like the pro side of these though (handbrake especially, just not quite enough).