The AMD Zen and Ryzen 7 Review: A Deep Dive on 1800X, 1700X and 1700
by Ian Cutress on March 2, 2017 9:00 AM ESTExecution, Load/Store, INT and FP Scheduling
The execution of micro-ops get filters into the Integer (INT) and Floating Point (FP) parts of the core, which each have different pipes and execution ports. First up is the Integer pipe which affords a 168-entry register file which forwards into four arithmetic logic units and two address generation units. This allows the core to schedule six micro-ops/cycle, and each execution port has its own 14-entry schedule queue.
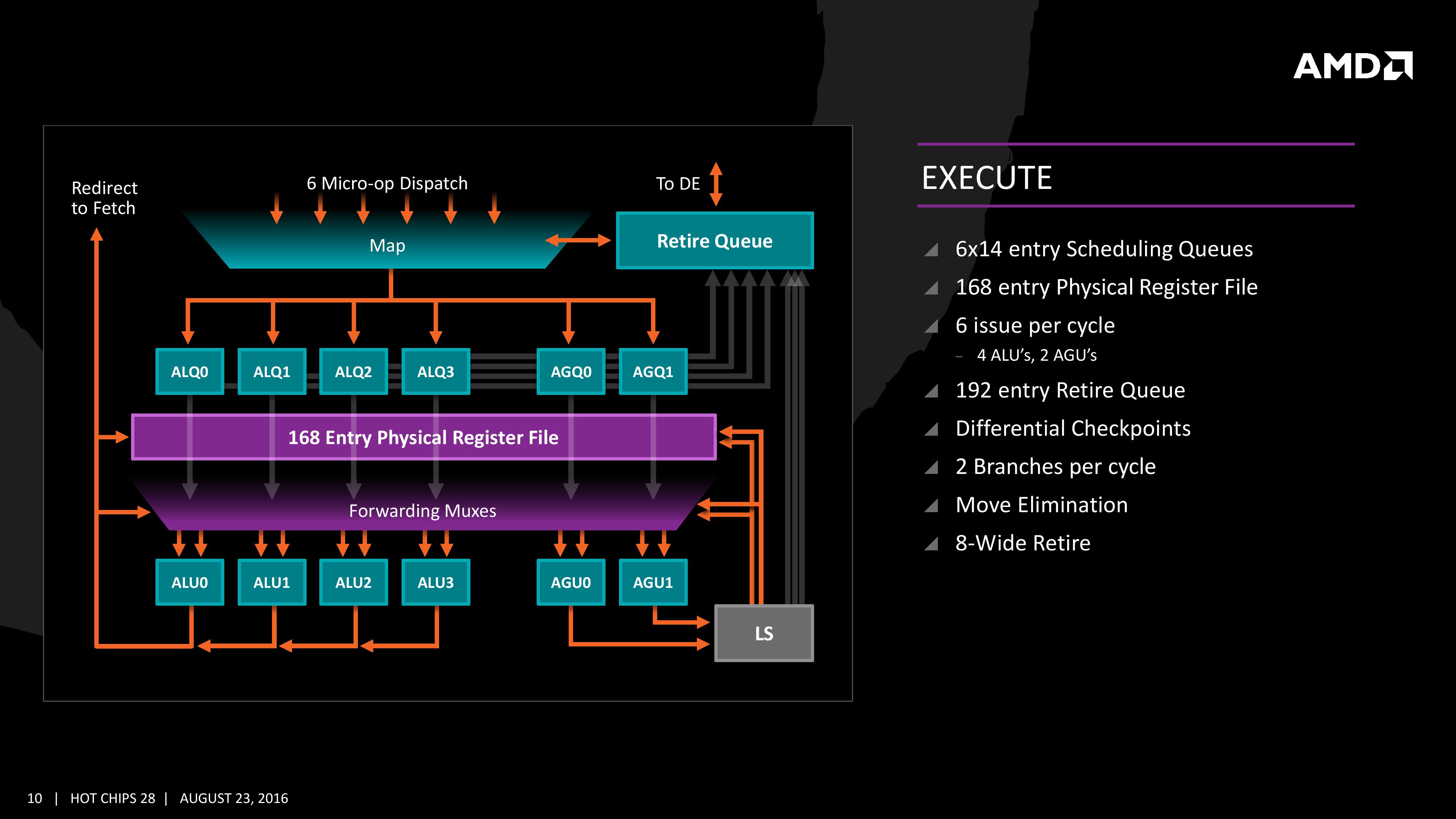
The INT unit can work on two branches per cycle, but it should be noted that not all the ALUs are equal. Only two ALUs are capable of branches, one of the ALUs can perform IMUL operations (signed multiply), and only one can do CRC operations. There are other limitations as well, but broadly we are told that the ALUs are symmetric except for a few focused operations. Exactly what operations will be disclosed closer to the launch date.
The INT pipe will keep track of branching instructions with differential checkpoints, to cut down on storing redundant data between branches (saves queue entries and power), but can also perform Move Elimination. This is where a simple mov command between two registers occurs – instead of inflicting a high energy loop around the core to physically move the single instruction, the core adjusts the pointers to the registers instead and essentially applies a new mapping table, which is a lower power operation.
Both INT and FP units have direct access to the retire queue, which is 192-entry and can retire 8 instructions per cycle. In some previous x86 CPU designs, the retire unit was a limiting factor for extracting peak performance, and so having it retire quicker than dispatch should keep the queue relatively empty and not near the limit.
The Load/Store Units are accessible from both AGUs simultaneously, and will support 72 out-of-order loads. Overall, as mentioned before, the core can perform two 16B loads (2x128-bit) and one 16B store per cycle, with the latter relying on a 44-entry Store queue. The TLB buffer for the L2 cache for already decoded addresses is two level here, with the L1 TLB supporting 64-entry at all page sizes and the L2 TLB going for 1.5K-entry with no 1G pages. The TLB and data pipes are split in this design, which relies on tags to determine if the data is in the cache or to start the data prefetch earlier in the pipeline.
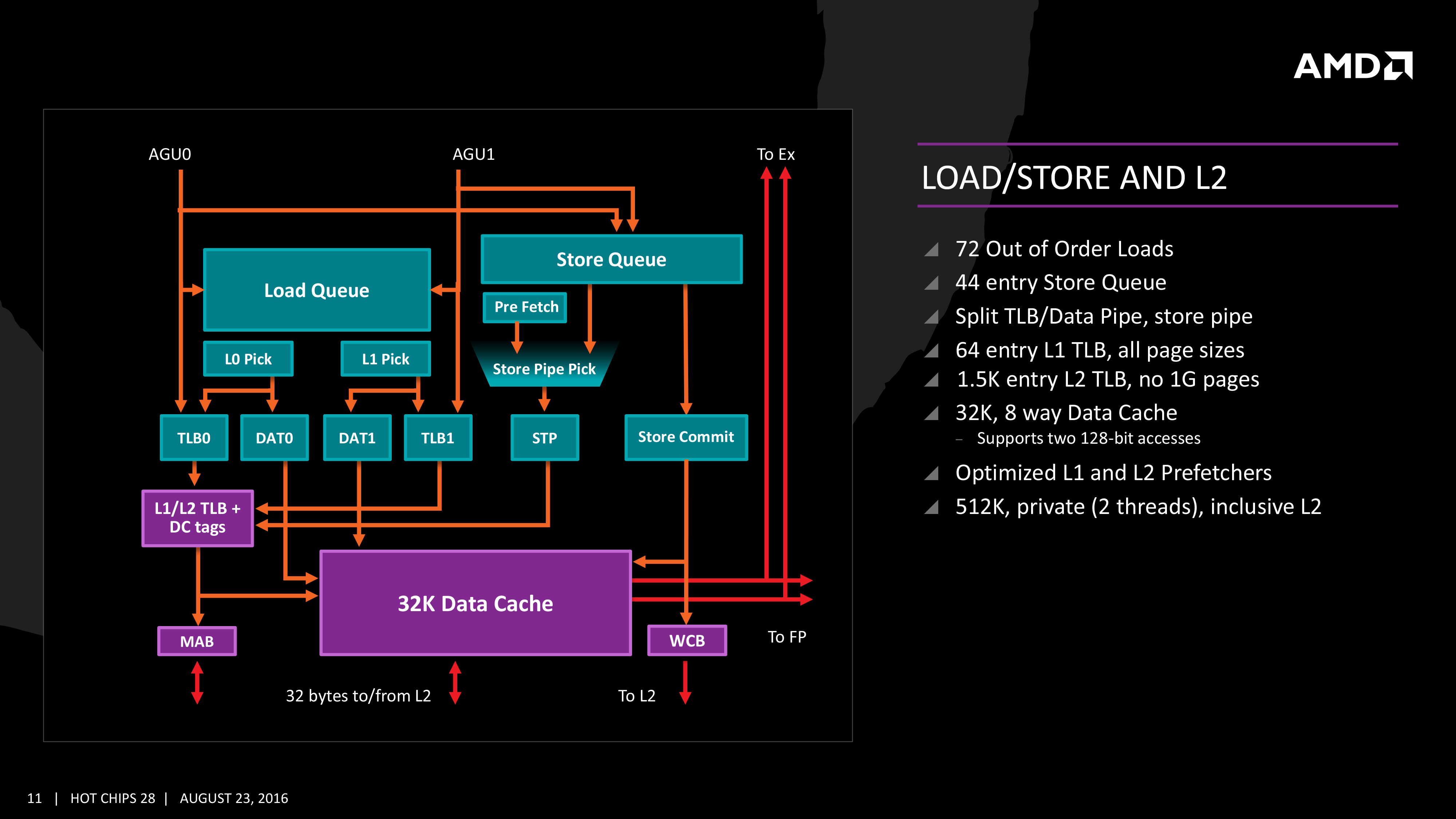
The data cache here also has direct access to the main L2 cache at 32 Bytes/cycle, with the 512 KB 8-way L2 cache being private to the core and inclusive. When data resides back in L1 it can be processed back to either the INT or the FP pipes as required.
Moving onto the floating point part of the core, and the first thing to notice is that there are two scheduling queues here. These are listed as ‘schedulable’ and ‘non-schedulable’ queues with lower power operation when certain micro-ops are in play, but also allows the backup queue to sort out parts of the dispatch in advance via the LDCVT. The register file is 160 entry, with direct FP to INT transfers as required, as well as supporting accelerated recovery on flushes (when data is written to a cache further back in the hierarchy to make room).
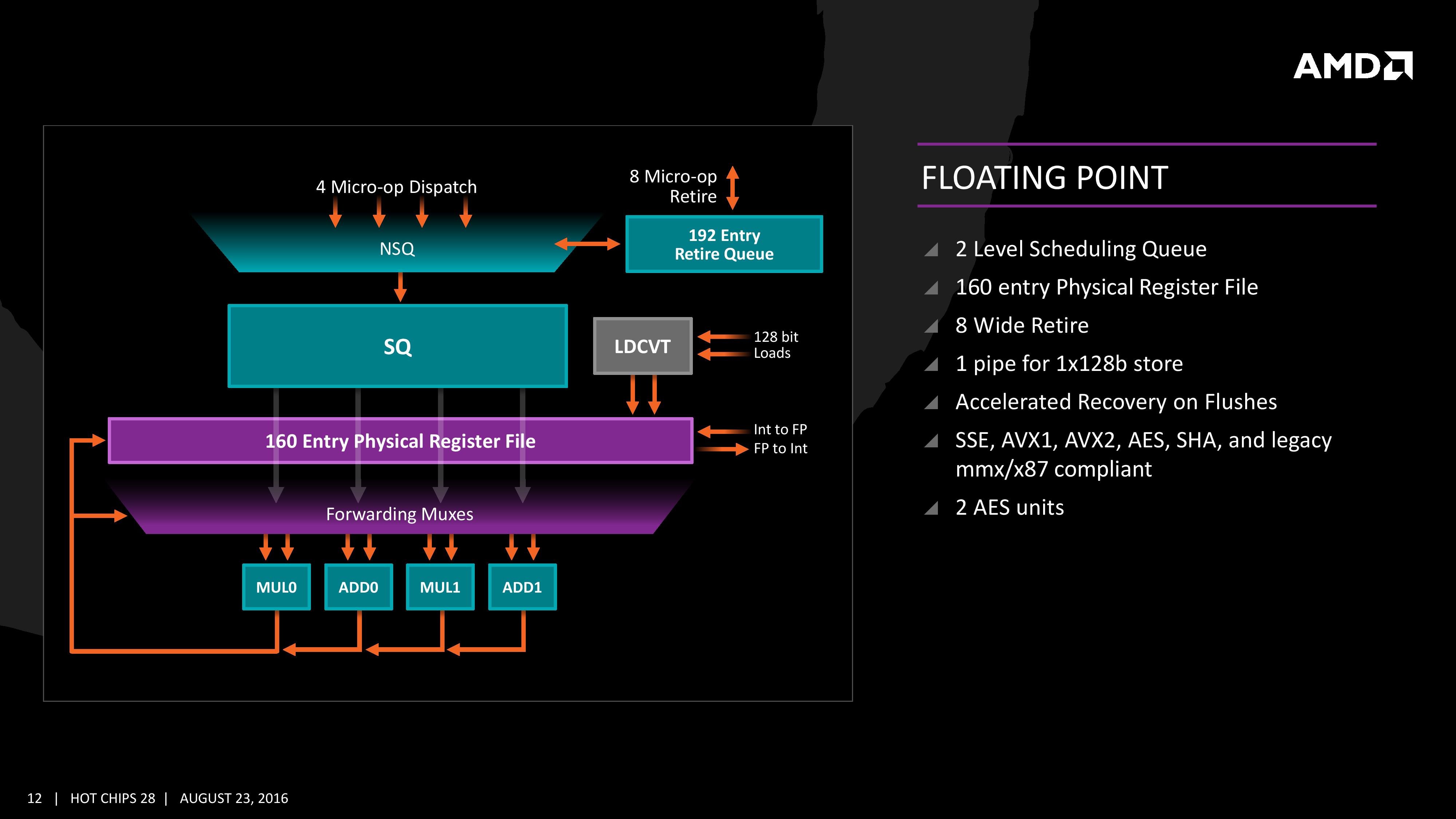
The FP Unit uses four pipes rather than three on Excavator, and we are told that the latency in Zen is reduced as well for operations (though more information on this will come at a later date). We have two MUL and two ADD in the FP unit, capable of joining to form two 128-bit FMACs, but not one 256-bit AVX. In order to do AVX, the unit will split the operations accordingly. On the counter side each core will have 2 AES units for cryptography as well as decode support for SSE, AVX1/2, SHA and legacy mmx/x87 compliant code.








574 Comments
View All Comments
nt300 - Saturday, March 11, 2017 - link
The Ryzen 7 1700 is definitely the gaming choice IMO. The CPU that does well in gaming and amazing at everything else. Windows 10 hasn't been properly optimized for ZEN, so any Benchmarks and Gaming Benchmarks are not set in stone.A2Ple98 - Monday, May 22, 2017 - link
Actually Ryzen isn't for only gamers, is mostly for streamers and professionals. The cores that aren't used for gaming, they are used to encode the video you are stream. As for pro people, they get almost a i7-6900K for half the price.Sweeprshill - Thursday, March 2, 2017 - link
Does not seem to be proper English here ?Sweeprshill - Thursday, March 2, 2017 - link
n/m can't edit comments I supposent300 - Saturday, March 11, 2017 - link
Wrong, ZEN is a new design and quite innovative. Just like the past, AMD has let this industry for many years. More so when they launched the Athlon 64 with the IMC which Intel claimed was useless and a waste of die space. That Athlon 64 at 1000 MHz less clock speed smoked any Intel chip you put it against.My point, ZEN is new, and both ZEN and Intel chips are unique in there own way, might share some similarities, but nevertheless they are different.
nos024 - Thursday, March 2, 2017 - link
Nope. Ryzen will need to drop in price. $500 1800x is still too expensive. According to this even a 7700k @ $300 -$350 is still a good choice for gamers.2011-v3 still offers a platform with more PCIe3 lanes and quad memory channel. I thought about an 1800x and 370 mobo combo, but that costs similar to a 6850k with x99.
Sorry, ill stick to intel this time around. Good that ryzen caused a ripple in price war though.
Gothmoth - Thursday, March 2, 2017 - link
gamer... as if the world is only full with idiotic people who waste their lives playing shooter or RPG´s.nos024 - Thursday, March 2, 2017 - link
Ikr? Whatever makes your world go round man.brushrop03 - Thursday, March 2, 2017 - link
Well playedAndrewJacksonZA - Thursday, March 2, 2017 - link
lol