The AMD Zen and Ryzen 7 Review: A Deep Dive on 1800X, 1700X and 1700
by Ian Cutress on March 2, 2017 9:00 AM ESTThe High-Level Zen Overview
AMD is keen to stress that the Zen project had three main goals: core, cache and power. The power aspect of the design is one that was very aggressive – not in the sense of aiming for a mobile-first design, but efficiency at the higher performance levels was key in order to be competitive again. It is worth noting that AMD did not mention ‘die size’ in any of the three main goals, which is usually a requirement as well. Arguably you can make a massive core design to run at high performance and low latency, but it comes at the expense of die size which makes the cost of such a design from a product standpoint less economical (if AMD had to rely on 500mm2 die designs in consumer at 14nm, they would be priced way too high). Nevertheless, power was the main concern rather than pure performance or function, which have been typical AMD targets in the past. The shifting of the goal posts was part of the process to creating Zen.

This slide contains a number of features we will hit on later in this piece, but covers a number of main topics which come under those main three goals of core, cache and power.
For the core, having bigger and wider everything was to be expected, however maintaining a low latency can be difficult. Features such as the micro-op cache help most instruction streams improve in performance and bypass parts of potentially long-cycle repetitive operations, but also the larger dispatch, larger retire, larger schedulers and better branch prediction means that higher throughput can be maintained longer and in the fastest order possible. Add in dual threads and the applicability of keeping the functional units occupied with full queues also improves multi-threaded performance.
For the caches, having a faster prefetch and better algorithms ensures the data is ready when each of the caches when a thread needs it. Aiming for faster caches was AMD’s target, and while they are not disclosing latencies or bandwidth at this time, we are being told that L1/L2 bandwidth is doubled with L3 up to 5x.
For the power, AMD has taken what it learned with Carrizo and moved it forward. This involves more aggressive monitoring of critical paths around the core, and better control of the frequency and power in various regions of the silicon. Zen will have more clock regions (it seems various parts of the back-end and front-end can be gated as needed) with features that help improve power efficiency, such as the micro-op cache, the Stack Engine (dedicated low power address manipulation unit) and Move elimination (low-power method for register adjustment - pointers to registers are adjusted rather than going through the high-power scheduler).
The Big Core Diagram
We saw this diagram last year, showing some of the bigger features AMD wants to promote:
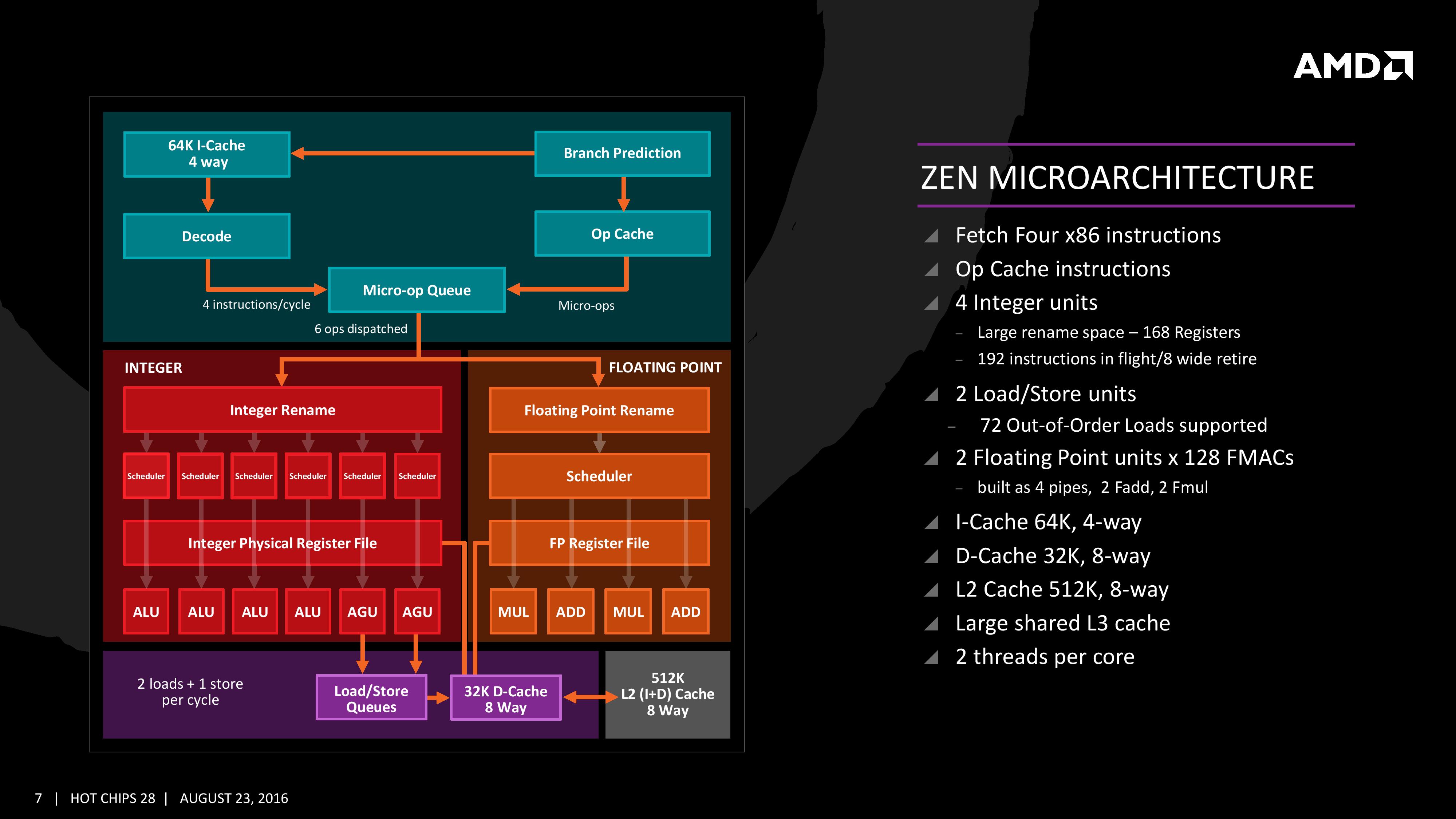
The improved branch predictor allows for 2 branches per Branch Target Buffer (BTB), but in the event of tagged instructions will filter through the micro-op cache. On the other side, the decoder can dispatch 4 instructions per cycle however some of those instructions can be fused into the micro-op queue. Fused instructions still come out of the queue as two micro-ops, but take up less buffer space as a result.
As mentioned earlier, the INT and FP pipes and schedulers are separated, however the INT rename space is 168 registers wide, which feeds into 6x14 scheduling queues. The FP employs as 160 entry register file, and both the FP and INT sections feed into a 192-entry retire queue. The retire queue can operate at 8 instructions per cycle, moving up from 4/cycle in previous AMD microarchitectures.
The load/store units are improved, supporting a 72 out-of-order loads, similar to Skylake. We’ll discuss this a bit later. On the FP side there are four pipes (compared to three in previous designs) which support combined 128-bit FMAC instructions. These can be combined for one 256-bit AVX, but beyond that it has to be scheduled over multiple instructions.








574 Comments
View All Comments
Notmyusualid - Saturday, March 4, 2017 - link
Can't disagree with you pal. They look like they execptional value for money.I on the other hand, am already on LGA2011-v3 platform, so I won't be changing, but the main point here is - AMD are back. And we welcome them too.
Alexvrb - Saturday, March 4, 2017 - link
Yeah... if the pricing is as good as rumored for the Ryzen 5, I may pick up a quad-core model. Gives me an upgrade path too, maybe a Ryzen+ hexa or octa-core down the road. For budget builds that Ryzen 3 non-SMT quad-core is going to be hard to argue with though.wut - Sunday, March 5, 2017 - link
You're really optimistically assuming things.Kaby Lake Core i5 7400 $170
Ryzen 5 1600X $259
...and single thread benchmark shows Core i5 to be firmly ahead, just as Core i7 is. The story doesn't seem to change much in the mid range.
Meteor2 - Tuesday, March 7, 2017 - link
@wut spot-on. It also seems that Zen on GloFlo 14 nm doesn't clock higher than 4.0 GHz. Zen has lower IPC and lower actual clocks than Intel KBL.Whichever way you cut it, however many cores in a chip are being considered, in terms of performance, Intel leads. Intel's pricing on >4 core parts is stupid and AMD gives them worthy price competition here. But at 4C and below, Intel still leads. AMD isn't price-competitive here either. No wonder Intel haven't responded to Zen. A small clock bump with Coffee Lake and a slow move to 10 nm starting with Cannon Lake for mobile CPUs (alongside or behind the introduction of 10 nm 'datacentre' chips) is all they need to do over the next year.
After all, if Intel used the same logic as TSMC and GloFlo in naming their process nodes, i.e. using the equivalent nanometre number of if finFETs weren't being used, Intel would say they're on a 10 nm process. They have a clear lead over GloFlo and thus anything AMD can do.
Cooe - Sunday, February 28, 2021 - link
I'm here from the future to tell you that you were wrong about literally everything though. AMD is kicking Intel's ass up and down the block with no end in sight.Cooe - Sunday, February 28, 2021 - link
Hahahaha. I really fucking hope nobody actually took your "buying advice". The 6-core/12-thread Ryzen 5 1600 was about as fast at 1080p gaming as the 4c/4t i5-7400 ON RELEASE in 2017, and nowadays with modern games/engines it's like TWICE AS FAST.deltaFx2 - Saturday, March 4, 2017 - link
I think the reviewer you're quoting is Gamers Nexus. He doesn't come across as being a particularly erudite person on matters of computer architecture. He throws a bunch of tests at it, and then spews a few untutored opinions, which may or may not be true. Tom's hardware does a lot of the same thing, and more, and their opinions are far more nuanced. Although they too could have tried to use an AMD graphics card to see if the problems persist there as well, but perhaps time was the constraint.There's the other question of whether running the most expensive GPU at 1080p is representative of real-world performance. Gaming, after all, is visual and largely subjective. Will you notice a drop of (say) 10 FPS at 150 FPS? How do you measure goodness of output? Let's contrive something.
All CPUs have bottlenecks, including Intel. The cases where AMD does better than Intel are where AMD doesn't have the bottlenecks Intel has, but nobody has noticed it before because there wasn't anything else to stack up against it. The question that needs to be answered in the following weeks and months is, are AMD's bottlenecks fixable with (say) a compiler tweak or library change? I'd expect much of it is, but lets see. There was a comment on some forum (can't remember) that said that back when Athlon64 (K8) came out, the gaming community was certain that it was terrible for gaming, and Netburst was the way to go. That opinion changed pretty quickly.
Notmyusualid - Saturday, March 4, 2017 - link
Gamers Nexus seem 'OK' to me. I don't know the site like I do Anandtech, but since Anand missed out the games....I am forced to make my opinions elsewhere. And funny you mentions Toms, they seem to back it up to some degree too, and I know these two sites are cross-owned.
But still, when Anand get around to benching games with Ryzen, only then will I draw my final conclusions.
deltaFx2 - Sunday, March 5, 2017 - link
@ Notmyusualid: I'm sure Gamers Nexus numbers are reasonable. I think they and Tom's (and other reviewers) see a valid bottleneck that I can only guess is software optimization related. The issue with GN was the bizarre and uninformed editorializing. Comments like, the workloads that AMD does well at are not important because they can be accelerated on GPU (not true, but if true, why on earth did GN use it in the first place?). There are other cases where he drops i5s from evaluation for "methodological reasons" but then says R7 == i5. Even based on the tests he ran, this is not true. Anyway, the reddit link goes over this in far more detail than I could (or would).Meteor2 - Tuesday, March 7, 2017 - link
@DeltaFX2 in what way was GamersNexus conclusion that tasks that can be pushed to GPUs should be incorrect? Are you saying Premiere and Blender can't be used on GPUs?GN's conclusion was:
"If you’re doing something truly software accelerated and cannot push to the GPU, then AMD is better at the price versus its Intel competition. AMD has done well with its 1800X strictly in this regard. You’ll just have to determine if you ever use software rendering, considering the workhorse that a modern GPU is when OpenCL/CUDA are present. If you know specific in stances where CPU acceleration is beneficial to your workflow or pipeline, consider the 1800X."
I think that's very fair and a very good summary of Ryzen.