The AMD Zen and Ryzen 7 Review: A Deep Dive on 1800X, 1700X and 1700
by Ian Cutress on March 2, 2017 9:00 AM ESTExecution, Load/Store, INT and FP Scheduling
The execution of micro-ops get filters into the Integer (INT) and Floating Point (FP) parts of the core, which each have different pipes and execution ports. First up is the Integer pipe which affords a 168-entry register file which forwards into four arithmetic logic units and two address generation units. This allows the core to schedule six micro-ops/cycle, and each execution port has its own 14-entry schedule queue.
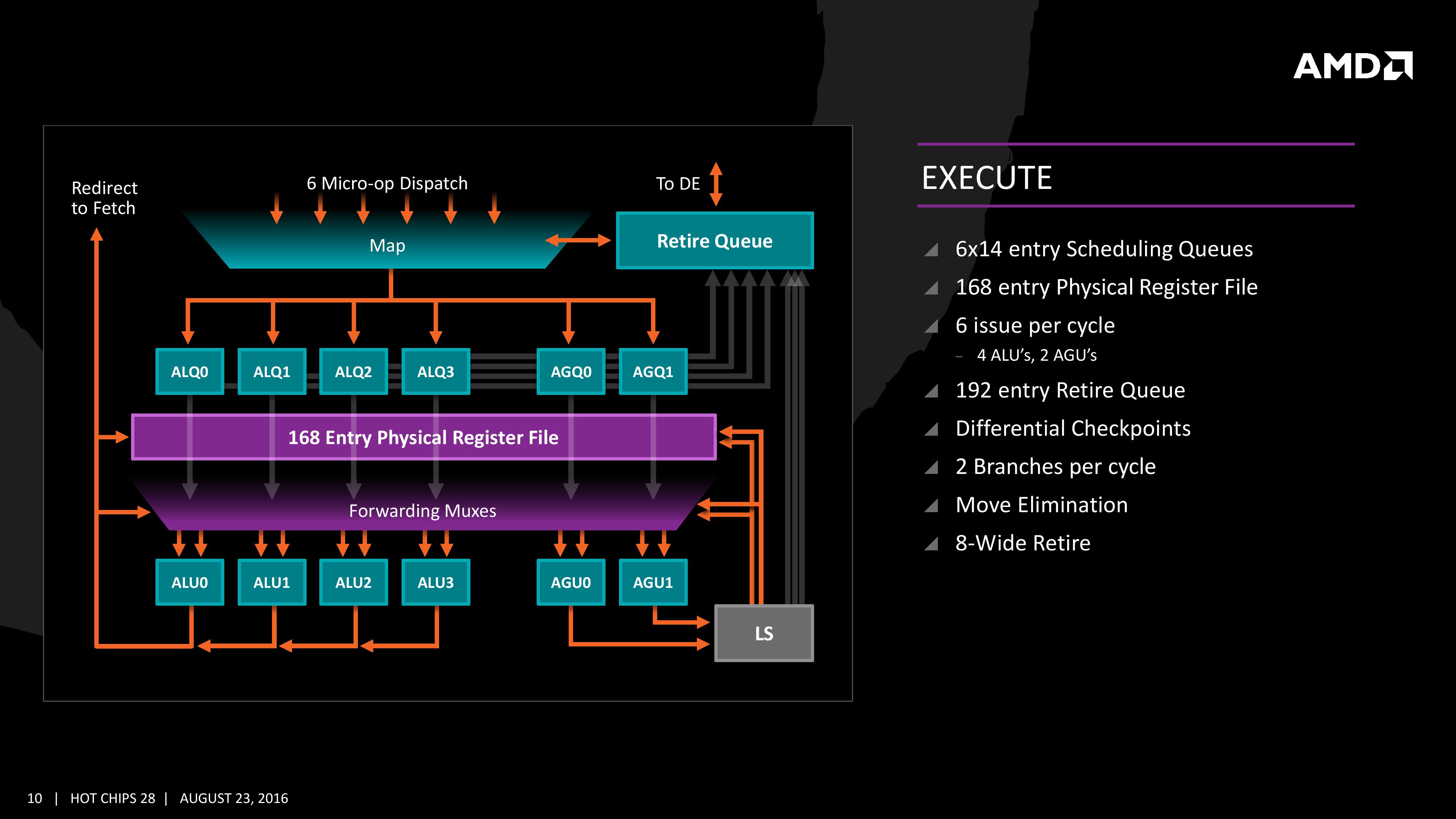
The INT unit can work on two branches per cycle, but it should be noted that not all the ALUs are equal. Only two ALUs are capable of branches, one of the ALUs can perform IMUL operations (signed multiply), and only one can do CRC operations. There are other limitations as well, but broadly we are told that the ALUs are symmetric except for a few focused operations. Exactly what operations will be disclosed closer to the launch date.
The INT pipe will keep track of branching instructions with differential checkpoints, to cut down on storing redundant data between branches (saves queue entries and power), but can also perform Move Elimination. This is where a simple mov command between two registers occurs – instead of inflicting a high energy loop around the core to physically move the single instruction, the core adjusts the pointers to the registers instead and essentially applies a new mapping table, which is a lower power operation.
Both INT and FP units have direct access to the retire queue, which is 192-entry and can retire 8 instructions per cycle. In some previous x86 CPU designs, the retire unit was a limiting factor for extracting peak performance, and so having it retire quicker than dispatch should keep the queue relatively empty and not near the limit.
The Load/Store Units are accessible from both AGUs simultaneously, and will support 72 out-of-order loads. Overall, as mentioned before, the core can perform two 16B loads (2x128-bit) and one 16B store per cycle, with the latter relying on a 44-entry Store queue. The TLB buffer for the L2 cache for already decoded addresses is two level here, with the L1 TLB supporting 64-entry at all page sizes and the L2 TLB going for 1.5K-entry with no 1G pages. The TLB and data pipes are split in this design, which relies on tags to determine if the data is in the cache or to start the data prefetch earlier in the pipeline.
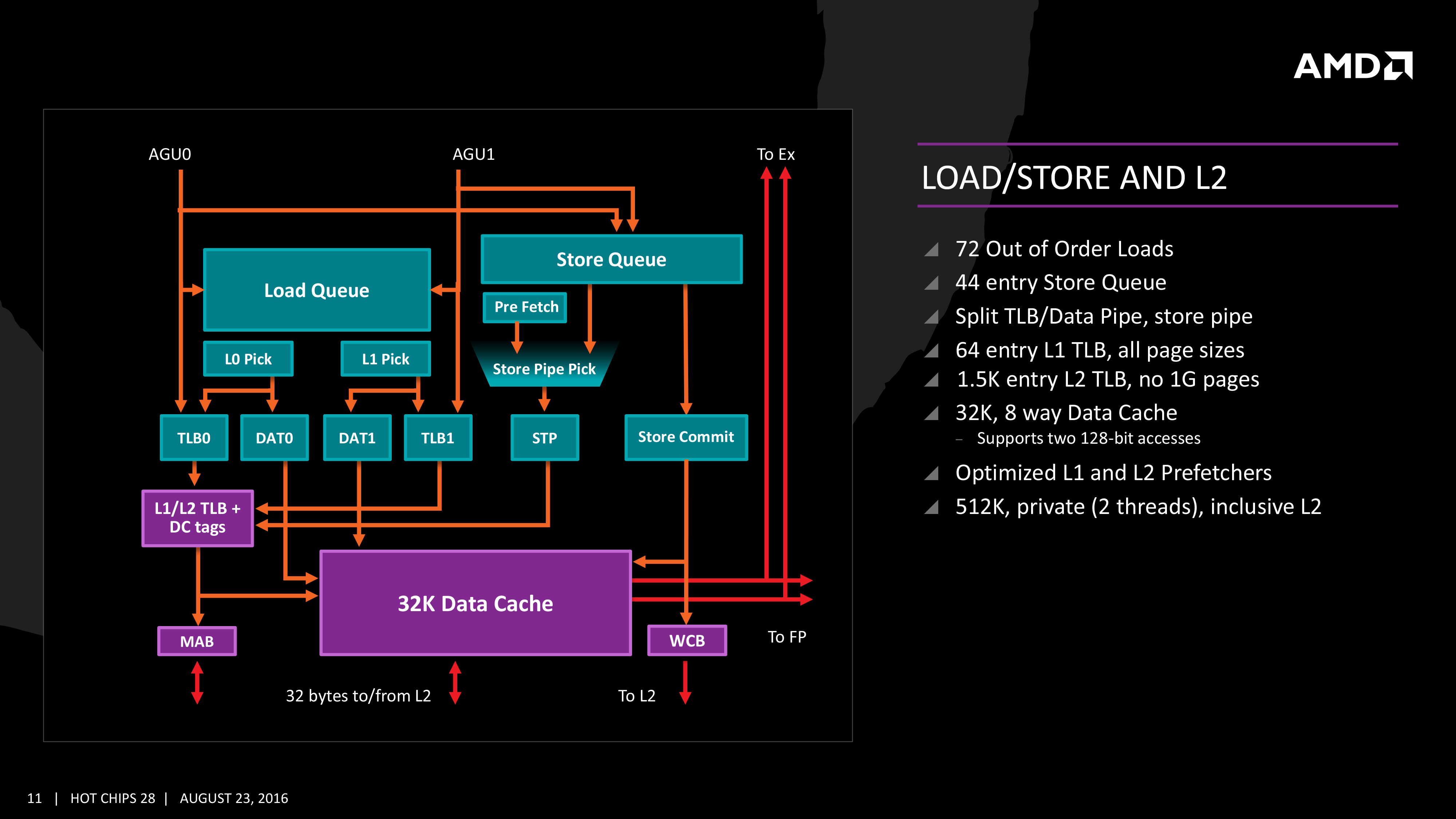
The data cache here also has direct access to the main L2 cache at 32 Bytes/cycle, with the 512 KB 8-way L2 cache being private to the core and inclusive. When data resides back in L1 it can be processed back to either the INT or the FP pipes as required.
Moving onto the floating point part of the core, and the first thing to notice is that there are two scheduling queues here. These are listed as ‘schedulable’ and ‘non-schedulable’ queues with lower power operation when certain micro-ops are in play, but also allows the backup queue to sort out parts of the dispatch in advance via the LDCVT. The register file is 160 entry, with direct FP to INT transfers as required, as well as supporting accelerated recovery on flushes (when data is written to a cache further back in the hierarchy to make room).
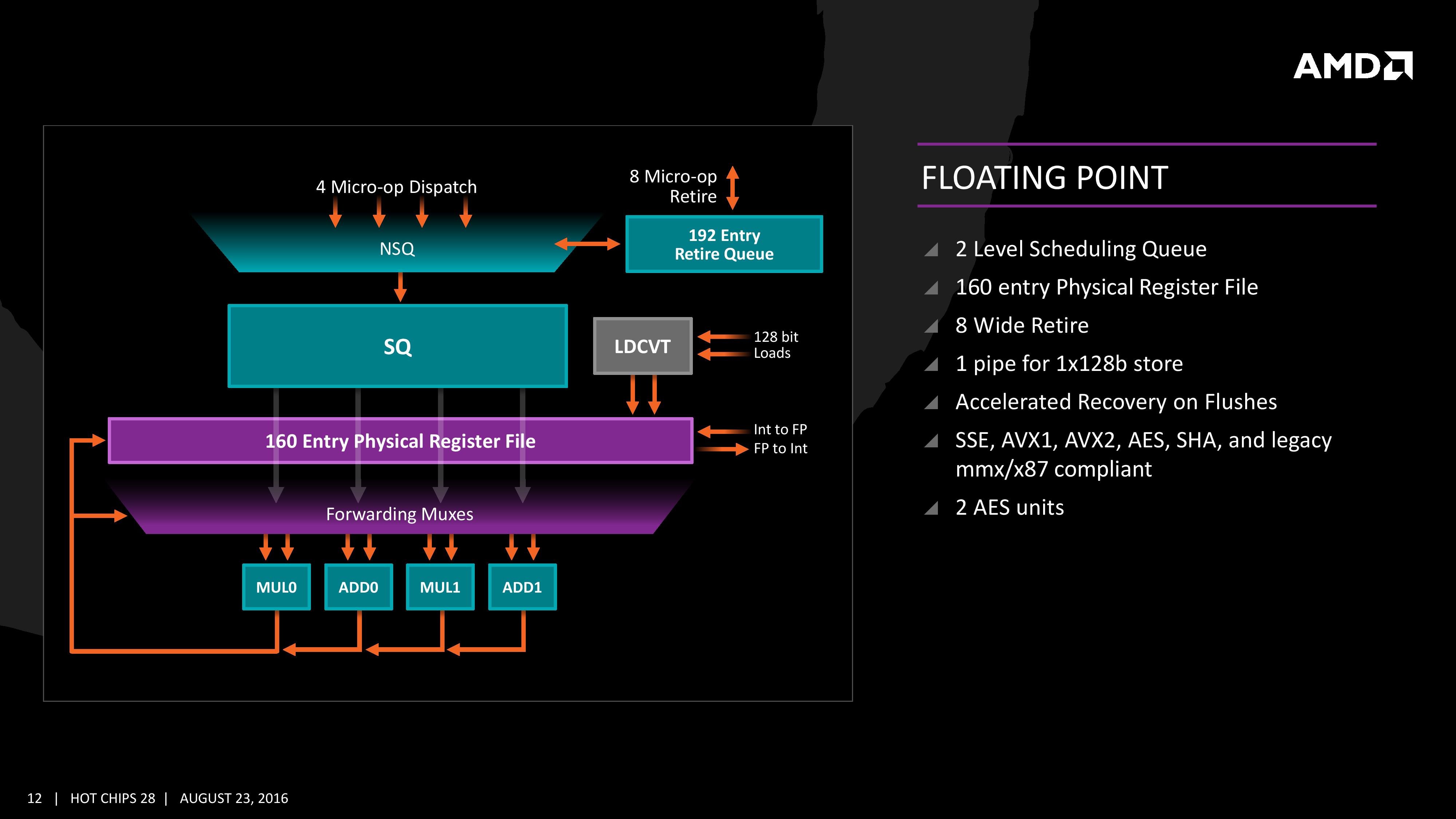
The FP Unit uses four pipes rather than three on Excavator, and we are told that the latency in Zen is reduced as well for operations (though more information on this will come at a later date). We have two MUL and two ADD in the FP unit, capable of joining to form two 128-bit FMACs, but not one 256-bit AVX. In order to do AVX, the unit will split the operations accordingly. On the counter side each core will have 2 AES units for cryptography as well as decode support for SSE, AVX1/2, SHA and legacy mmx/x87 compliant code.








574 Comments
View All Comments
mikeZZZ - Friday, March 3, 2017 - link
Anadtech, can we please run closer to real life scenarios such as a gaming benchmark with a file compression benchmark running at the same time. Even gaming enthusiasts run more than one program at a time. For example, file decompression in the background while playing a game, or baseball game streaming in a small window while playing a game. You already have many individual benchmarks, so why not go the extra but significant benchmark of running two? We know this favors the higher core CPUs (maybe even Ryzen 7 1700 over all other lower core ones CPUs) but that is closer to real life and should be very meaningful to someone wanting to make an informed purchase.ValiumMm - Saturday, March 4, 2017 - link
Would also like to see thisUrQuan3 - Friday, March 3, 2017 - link
Just want to put out a quick comment about benchmarking with Handbrake. In dealing with Broadwell-E, and especially ThunderX, I've found that Handbrake often doesn't scale well past about 10 cores, and really doesn't scale well past 16 or so. What seems to happen is that the single-threaded parts of Handbrake tend to dominate the encode time. In extreme cases, ultra-fast and placebo will take almost the same amount of time as x264 is consuming input faster than the rest of Handbrake can generate it. On ThunderX, I've found I can complete four 1080p placebo encodes in the same amount of time that I can complete one. I would expect a similar result on a 48 core Intel, though I do not have access to one beyond 24 cores. Turbo boost would hide this effect a bit.I am not knocking using Handbrake for benchmarking. The Handbrake and ray-trace results are the two that I care about most. I just thought I'd give a heads up about this limitation. You can check CPU usage statistics to get an indication of when you are running up against this limit.
Oh, and I am very excited to see multiple ray-tracers in your runs. Please continue.
Meteor2 - Saturday, March 4, 2017 - link
Presumably though you can have several x264 jobs running simultaneously on that hardware? So while your time to encode a certain piece doesn't decrease, you have more total-throughput (e.g. encoding several different bitrates for adaptive streaming). Should give good efficiency too on a larger Broadwell-E or a ThunderX.UrQuan3 - Tuesday, March 7, 2017 - link
Exactly. It's the first time I've thought about installing a queue manager for a single computer.jade5419 - Saturday, March 4, 2017 - link
I agree with this. In my experience Handbrake has a core / thread limit.I have a Z600 system with dual Xeon 5570 @ 2.93GHz, 6 core / 12 threads (total 24 threads), 48GB of RAM and a Z620 system with dual Xeon E5-2690 @ 2.9GHz 8 core / 16 threads (total 32 threads), 64GB RAM.
The two systems transcode video at the same speed using Handbrake 1.0.3. Monitoring CPU usage shows all threads of the Z600 at 100% utilization whereas the CPU utilization on the Z620 is approximately 80%.
Notmyusualid - Sunday, March 5, 2017 - link
Ever tried running GTA5 on 28 cores?It doesn't work. You have to adjust the game 'launchers' core affinity to < 26 cores or it won't even load.
Given this discovery, I expect there are many more applications out there, that may crap-out as we see more and more cores come into the mainstream.
Just a thought.
mapesdhs - Sunday, March 5, 2017 - link
I'd love to know why this happens. I'm guessing something dumb within Windows.Outlander_04 - Friday, March 3, 2017 - link
There is more than enough good news to make me want to buy a 6 core Ryzen when they become available .Likely that will be the sweet spot for gamers
0ldman79 - Saturday, March 4, 2017 - link
I'm looking forward to seeing Ryzen updated in the bench.There aren't any apps or benchmarks that cross over between the FX series and the Ryzen series, so we can't do any side by side comparison.
Great review guys. Looking forward to the six core Ryzen. I think just like the FX series the six core will be the sweet spot.