AMD 7th Gen Bristol Ridge and AM4 Analysis: Up to A12-9800, B350/A320 Chipset, OEMs first, PIBs Later
by Ian Cutress on September 23, 2016 9:00 AM ESTThe Integrated GPU
For all but one of the processors, integrated graphics is the name of the game. AMD configures the integrated graphics in terms of Compute Units (CUs), with each CU having 64 streaming processors (SPs) using GCN 1.3 (aka GCN 3.0) architecture, the same architecture as found in AMD’s R9 Fury line of GPUs. The lowest processor in the stack, the A6-9500E, will have four CUs for 256 SPs, and the A12 APUs will have eight CUs, for 512 SPs. The other processors will have six CUs for 384 SPs, and in each circumstance the higher TDP processor typically has the higher base and turbo frequency.
| AMD 7th Generation Bristol Ridge Processors | |||||
| GPU | GPU SPs | GPU Base | GPU Turbo | TDP | |
| A12-9800 | Radeon R7 | 512 | 800 | 1108 | 65W |
| A12-9800E | Radeon R7 | 512 | 655 | 900 | 35W |
| A10-9700 | Radeon R7 | 384 | 720 | 1029 | 65W |
| A10-9700E | Radeon R7 | 384 | 600 | 847 | 35W |
| A8-9600 | Radeon R7 | 384 | 655 | 900 | 65W |
| A6-9500 | Radeon R5 | 384 | 720 | 1029 | 65W |
| A6-9500E | Radeon R5 | 256 | 576 | 800 | 35W |
| Athlon X4 950 | - | - | - | - | 65W |
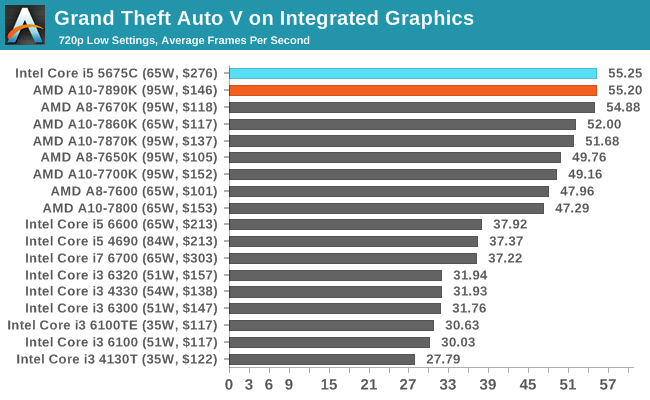
The new top frequency, 1108 MHz, for the A12-9800 is an interesting element in the discussion. Compared to the previous A10-7890K, we have a +28% increase in raw GPU frequency with the same number of streaming processors, but a lower TDP. This means one of two things – either the 1108 MHz frequency mode is a rare turbo state as the TDP has to be shared between the CPU and APU, or the silicon is sufficient enough to maintain a 28% higher frequency with ease. Obviously, based on the overclocking results seen previously, it might be interesting to see how the GPU might change in frequency without a TDP barrier and with sufficient cooling. For comparison, when we tested the A10-7890K in Grand Theft Auto at a 1280x720 resolution and low-quality settings, we saw an average 55.20 FPS.
Bearing in mind the change in the cache configuration moving to Bristol Ridge, moving from a 4 MB L2 to a 2 MB L2 but increasing the DRAM compatibility from DDR3-2133 to DDR4-2400, that value should move positive, and distinctly the most cost effective part for gaming.
Each of these processors supports the following display modes:
- DVI, 1920x1200 at 60 Hz
- DisplayPort 1.2a, 4096x2160 at 60 Hz (FreeSync supported)
- HDMI 2.0, 4096x2160 at 60 Hz
- eDP, 2560x1600 at 60 Hz
Technically the processor will support three displays, with any mix of the above. Analog video via VGA can be supported by a DP-to-VGA converter chip on the motherboard or via an external dongle.
For codec support, Bristol Ridge can do the following (natively unless specified):
- MPEG2 Main Profile at High Level (IDCT/VLD)
- MPEG4 Part 2 Advanced Simple Profile at Level 5
- MJPEG 1080p at 60 FPS
- VC1 Simple and Main Profile at High Level (VLD), Advanced Profile at Level 3 (VLD)
- H.264 Constrained Baseline/Main/High/Stereo High Profile at Level 5.2
- HEVC 8-bit Main Profile Decode Only at Level 5.2
- VP9 decode is a hybrid solution via the driver, using CPU and GPU
AMD still continues to support HSA and the arrangement between the Excavator v2 modules in Bristol Ridge and the GCN graphics inside is no different – we still get Full 1.0 specification support. With the added performance, AMD is claiming equal scores for the A12-9800 on PCMark 8 Home with OpenCL acceleration as a Core i5-6500 ($192 tray price), and the A12-9800E is listed as a 17% increase in performance over the i5-6500T. With synthetic gaming benchmarks, AMD is claiming 90-100% better performance for the A12 over the i5 competition.








122 Comments
View All Comments
Alexvrb - Sunday, September 25, 2016 - link
Geekbench is trash at comparing across different architectures. It makes steaming piles look good. Only using SSE (first gen, ancient) on x86 processors would certainly be a part of the puzzle regarding Geekbench results. Thanks, Patrick.Not to take anything away from Apple's cores. I wouldn't be surprised that they have better performance per WATT than Skylake. Perf/watt is kind of a big deal for mobile, and Apple (though I don't care for them as a company) builds very efficient processor cores. With A10 using a big.LITTLE implementation of some variety, they stand to gain even more efficiency. But in terms of raw performance? Never rely on Geekbench unless maybe you're comparing an A9 Apple chip to an A10 or something. MAYBE.
ddriver - Monday, September 26, 2016 - link
Hey, it is not me who uses crap like geekbench and sunspider to measure performnace, it is sites like AT ;)BurntMyBacon - Monday, September 26, 2016 - link
@ddriver: "Hey, it is not me who uses crap like geekbench and sunspider to measure performnace, it is sites like AT ;)"LOL. My gut reaction was to call you out on blame shifting until I realized ... You are correct. There hasn't exactly been a lot of benchmark comparison between ARM and x86. Of course, there isn't much out there with which to compare either so ...
patrickjp93 - Monday, September 26, 2016 - link
Linpack and SAP. Both are massive benchmark suites that will give you the honest to God truth, and the truth is ARM is still 10 years behind.patrickjp93 - Monday, September 26, 2016 - link
They use it in context and admit the benchmarks are not equally optimized across architectures.patrickjp93 - Monday, September 26, 2016 - link
It doesn't even use SSE. It uses x86_64 and x87 scalar float instructions. It doesn't even give you MMX or SSE. That's how biased it is.patrickjp93 - Monday, September 26, 2016 - link
Just because you write code simply enough using good modern form and properly align your data and make functions and loops small enough to be easily optimized does not mean GCC doesn't choke. Mike Acton gave a great lecture at CPPCon 2014 showing various examples where GCC, Clang, and MVCC choke.Define very good.
Define detailed analysis. Under what workloads? Is it more efficient for throughput or latency (because I guarantee it can't be both)?
Yes, Geekbench uses purely scalar code on x86 platforms. It's ludicrously pathetic.
It's 8x over scalar, and that's where it matters, and it can even be better than that because of loop Muop decreases which allow the loops to fit into the detector buffers which can erase the prefetch and WB stages until the end of the loop.
No, they're not more powerful. A Pentium IV is still more powerful than the Helio X35 or Exynos 8890.
No, those are select benchmarks that are more network bound than CPU bound and are meaningless for the claims people are trying to make based on them.
BurntMyBacon - Monday, September 26, 2016 - link
@ddriver: "I've been using GCC mostly, and in most of the cases after doing explicit vectorization I found no perf benefits, analyzing assembly afterwards revealed that the compiled has done a very good job at vectorizing wherever possible."It's not just about vectorizing. I haven't taken a look at Geekbench code, but it is pretty easy to under-utilize processor resources. Designing workloads to fit within a processors cache for repetitive operations is a common way to optimize. It does, however, leave a processor with a larger cache underutilized for the purposes of the workload. Similar examples can be found for wide vs narrow architectures and memory architectures feeding the processor. Even practical workloads can be done various ways that are much more or less suitable to a given platform. Compression / Encoding methods are some examples here.
BurntMyBacon - Monday, September 26, 2016 - link
@patrickjp93: "Yes you can get 5x the performance by optimizing. Geekbench only handles 1 datem at a time on Intel hardware vs. the 8 you can do with AVX and AVX2. Assuming you don't choke on bandwidth, you can get an 8x speedup."If you have processor with a large enough cache to keep a workload almost entirely in cache and another with far less cache that has to access main memory repetitively to do the job, the difference can be an order of magnitude or more. Admittedly, the type of workload that is small enough to fit in any processor cache isn't common, but I've seen cases of it in benchmarks and (less commonly in) scientific applications.
patrickjp93 - Tuesday, September 27, 2016 - link
Heh, they're usually based on Monte Carlo simulations if they can.