AMD 7th Gen Bristol Ridge and AM4 Analysis: Up to A12-9800, B350/A320 Chipset, OEMs first, PIBs Later
by Ian Cutress on September 23, 2016 9:00 AM ESTThe Integrated GPU
For all but one of the processors, integrated graphics is the name of the game. AMD configures the integrated graphics in terms of Compute Units (CUs), with each CU having 64 streaming processors (SPs) using GCN 1.3 (aka GCN 3.0) architecture, the same architecture as found in AMD’s R9 Fury line of GPUs. The lowest processor in the stack, the A6-9500E, will have four CUs for 256 SPs, and the A12 APUs will have eight CUs, for 512 SPs. The other processors will have six CUs for 384 SPs, and in each circumstance the higher TDP processor typically has the higher base and turbo frequency.
| AMD 7th Generation Bristol Ridge Processors | |||||
| GPU | GPU SPs | GPU Base | GPU Turbo | TDP | |
| A12-9800 | Radeon R7 | 512 | 800 | 1108 | 65W |
| A12-9800E | Radeon R7 | 512 | 655 | 900 | 35W |
| A10-9700 | Radeon R7 | 384 | 720 | 1029 | 65W |
| A10-9700E | Radeon R7 | 384 | 600 | 847 | 35W |
| A8-9600 | Radeon R7 | 384 | 655 | 900 | 65W |
| A6-9500 | Radeon R5 | 384 | 720 | 1029 | 65W |
| A6-9500E | Radeon R5 | 256 | 576 | 800 | 35W |
| Athlon X4 950 | - | - | - | - | 65W |
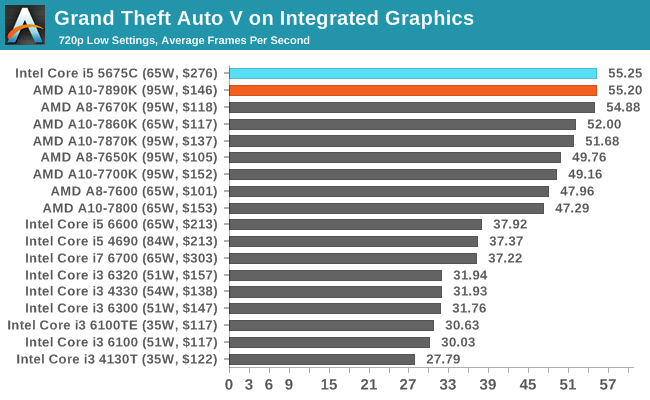
The new top frequency, 1108 MHz, for the A12-9800 is an interesting element in the discussion. Compared to the previous A10-7890K, we have a +28% increase in raw GPU frequency with the same number of streaming processors, but a lower TDP. This means one of two things – either the 1108 MHz frequency mode is a rare turbo state as the TDP has to be shared between the CPU and APU, or the silicon is sufficient enough to maintain a 28% higher frequency with ease. Obviously, based on the overclocking results seen previously, it might be interesting to see how the GPU might change in frequency without a TDP barrier and with sufficient cooling. For comparison, when we tested the A10-7890K in Grand Theft Auto at a 1280x720 resolution and low-quality settings, we saw an average 55.20 FPS.
Bearing in mind the change in the cache configuration moving to Bristol Ridge, moving from a 4 MB L2 to a 2 MB L2 but increasing the DRAM compatibility from DDR3-2133 to DDR4-2400, that value should move positive, and distinctly the most cost effective part for gaming.
Each of these processors supports the following display modes:
- DVI, 1920x1200 at 60 Hz
- DisplayPort 1.2a, 4096x2160 at 60 Hz (FreeSync supported)
- HDMI 2.0, 4096x2160 at 60 Hz
- eDP, 2560x1600 at 60 Hz
Technically the processor will support three displays, with any mix of the above. Analog video via VGA can be supported by a DP-to-VGA converter chip on the motherboard or via an external dongle.
For codec support, Bristol Ridge can do the following (natively unless specified):
- MPEG2 Main Profile at High Level (IDCT/VLD)
- MPEG4 Part 2 Advanced Simple Profile at Level 5
- MJPEG 1080p at 60 FPS
- VC1 Simple and Main Profile at High Level (VLD), Advanced Profile at Level 3 (VLD)
- H.264 Constrained Baseline/Main/High/Stereo High Profile at Level 5.2
- HEVC 8-bit Main Profile Decode Only at Level 5.2
- VP9 decode is a hybrid solution via the driver, using CPU and GPU
AMD still continues to support HSA and the arrangement between the Excavator v2 modules in Bristol Ridge and the GCN graphics inside is no different – we still get Full 1.0 specification support. With the added performance, AMD is claiming equal scores for the A12-9800 on PCMark 8 Home with OpenCL acceleration as a Core i5-6500 ($192 tray price), and the A12-9800E is listed as a 17% increase in performance over the i5-6500T. With synthetic gaming benchmarks, AMD is claiming 90-100% better performance for the A12 over the i5 competition.








122 Comments
View All Comments
ddriver - Saturday, September 24, 2016 - link
Hey, at least Trump is only preposterous and stupid. Hillary is all that PLUS crazy and evil. She is just as racist as Trump, if not more so, but she is not in the habit of being honest, she'd prefer to claim the votes of minorities.Politics is a joke and the current situation is a very good example of it. People deserve all shit that coming their way if they still put faith in the political process after this.
ClockHound - Friday, September 23, 2016 - link
+101Particularly enjoyed the term: "walled garden spyware milking station" model
Ok, not really enjoyed, cringed at the accuracy, however. ;-)
msroadkill612 - Wednesday, April 26, 2017 - link
An adage I liked "If its free, YOU are the product."hoohoo - Friday, September 23, 2016 - link
I see what you did there! Nicely done.patrickjp93 - Saturday, September 24, 2016 - link
No they aren't. If Geekbench optimized for x86 the way it does for ARM, the difference in performance per clock is nearly 5xddriver - Saturday, September 24, 2016 - link
You have no idea what you are talking about. Geekbench is very much optimized, there are basically three types of optimization:optimization done by the compiler - it eliminates redundant code, vertorizes loops and all that good stuff, that happens automatically
optimization by using intrinsics - do manually what the compiler does automatically, sometimes you could do better, but in general, compiler optimizations are very mature and very good at doing what they do
"optimization" of the type "if (CPUID != INTEL) doWorse()" - harmful optimization that doesn't really optimize anything in the true sense of the word, but deliberately chooses a less efficient code path to purposely harm the performance of a competitor - such optimizations are ALWAYS in the favor of the TOP DOG - be that intel or nvidia - companies who have excess of money to spend on such idiotic things. Smaller and less profitable companies like amd or arm - they don't do that kind of shit.
Finally, performance is not magic, you can't "optimize" and suddenly get 5X the performance. Process and TDP are a limiting factor, there is only so much performance you can get out of a chip produced at a given process for a given thermal budget. And that's if it is some perfectly efficient design. A 5W 20nm x86 chip could not possibly be any faster than a 5W 20nm ARM chip, intel has always had a slight edge in process, but if you manufacture an arm and a x86 chip on identical process (not just the claimed node size) with the same thermal budget the amr chip will be a tad faster, because the architecture is less bloated and more efficient.
It is a part of a dummy's belief system that arm chips are somehow fundamentally incapable of running professional software - on the contrary, hardware wise they are perfectly capable, only nobody bothers to write professional software for them.
patrickjp93 - Saturday, September 24, 2016 - link
I have a Bachelor's in computer science and specialized in high performance parallel, vectorized, and heterogeneous computing. I've disassembled Geekbench on x86 platforms, and it doesn't even use anything SSE or higher, and that's ancient Pentium III instructions.It does not happen automatically if you don't use the right compiler flags and don't have your data aligned to allow the instructions to work.
You need intrinsics for a lot of things. Clang and GCC both have huge compiler bug forums filled with examples of where people beat the compilers significantly.
Yes you can get 5x the performance by optimizing. Geekbench only handles 1 datem at a time on Intel hardware vs. the 8 you can do with AVX and AVX2. Assuming you don't choke on bandwidth, you can get an 8x speedup.
ARM is not more efficient on merit, and x86 is not bloated by any stretch. Both use microcode now. ARM is no longer RISC by any strict definition.
Cavium has. Oracle has. Google has. Amazon has. In all cases ARM could not keep up with Avoton and Xeon D in performance/watt/$ and thus the industry stuck with Intel instead of Qualcomm or Cavium.
Toss3 - Sunday, September 25, 2016 - link
This is a great post, and I just wanted to post an article by PC World where they discussed these things in simpler terms: http://www.pcworld.com/article/3006268/tablets/tes...As you can see the performance gains aren't really that great when it comes to real world usage, and as such we should probably start to use other benchmarks as well, and not just use Geekbench or browser javascript performance as indicators of actual performance of these SoCs especially when comparing one platform to another.
amagriva - Sunday, September 25, 2016 - link
Good post. To any interested a good paper on the subject : http://etn.se/images/expert/FD-SOI-eQuad-white-pap...ddriver - Sunday, September 25, 2016 - link
I've been using GCC mostly, and in most of the cases after doing explicit vectorization I found no perf benefits, analyzing assembly afterwards revealed that the compiled has done a very good job at vectorizing wherever possible.However, I am highly skeptical towards your claims, I'll believe it when I see it. I can't find the link now, but last year I've read detailed analysis, showing that A9X core performance per watt better than skylake over most of the A9X's clock range. And not in geekbench, but in SPEC.
As for geekbench, you make it sound as if they actually disabled vectorization explicitly. Which would be an odd thing. Not entirely clear what you mean by "1 datem at a time", but if you mean they are using scalar rather than vector instructions, that would be quite odd too. Luckily, I have better things to do than rummage about in geekbench machine code, so I will take your word that it is not properly optimized.
And sure, 256bit wide SIMD will have higher throughput than 128bit SIMD, but nowhere nearly 8 or even 5 times. And that doesn't make arm chips any less capable of running devices, which are more than useless toys. Those chips are more powerful than workstations were some 10 years ago, but their usability is nowhere near that. As the benchmarks from the link Toss3 posted indicate, the A9X is only some ~40% slower than i5-4300U in the "true/real world benchmarks", and that's a 15 watt chip vs the A9X is like what, 5-ish or something like that? And ARM is definitely more efficient once you account for intel's process advantage. This will become obvious if intel ever dare to manufacture arm cores at the same process as their own products. And it is not because of the ISA bloat but because of the design bloat.
Naturally, ARM chips are a low margin product, one cannot expect a 50$ chip to outperform a 300$ chip, but the gap appears to be closing, especially keeping in mind the brickwall process is going to hit the next decade. A 50$ chip running equal to a 300$ (and much wider design) chip from 2 year ago opens up a lot of possibilities, but I am not seeing any of them being realized by the industry.