AMD Zen Microarchitecture: Dual Schedulers, Micro-Op Cache and Memory Hierarchy Revealed
by Ian Cutress on August 18, 2016 9:00 AM ESTDeciphering the New Cache Hierarchy
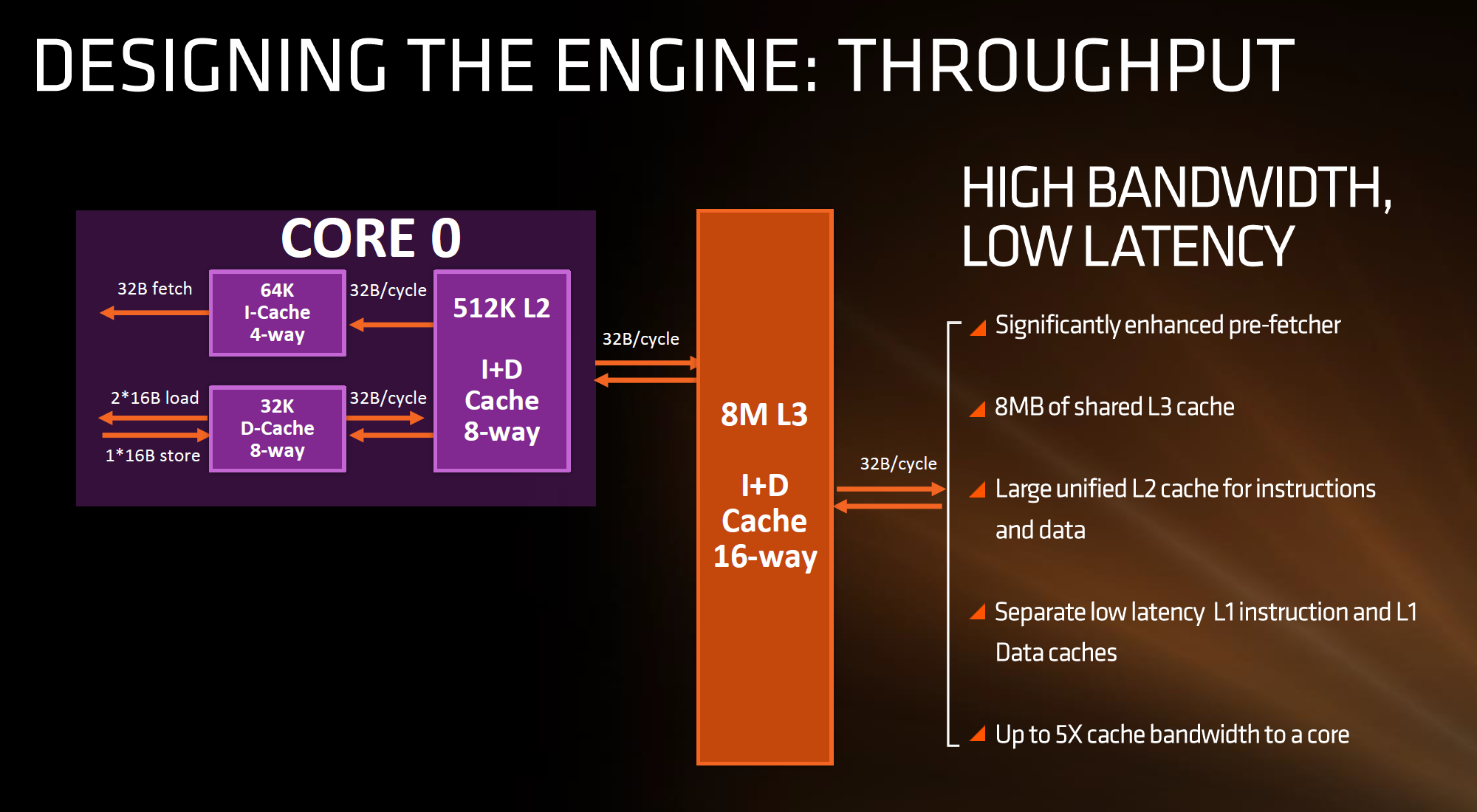
The cache hierarchy is a significant deviation from recent previous AMD designs, and most likely to its advantage. The L1 data cache is both double in size and increased in associativity compared to Bulldozer, as well as being write-back rather than write-through. It also uses an asymmetric load/store implementation, identifying that loads happen more often than stores in the critical paths of most work flows. The instruction cache is no longer shared between two cores as well as doubling in associativity, which should decrease the proportion of cache misses. AMD states that both the L1-D and L1-I are low latency, with details to come.
The L2 cache sits at half a megabyte per core with 8-way associativity, which is double that of Intel’s Skylake which has 256 KB/core and is only 4-way. On the other hand, Intel’s L3/LLC on their high-end Skylake SKUs is at 2 MB/core or 8 MB/CPU, whereas Zen will feature 1 MB/core and both are at 16-way associativity.
Edit 7:18am: Actually, the slide above is being slightly evasive in its description. It doesn't say how many cores the L3 cache is stretched over, or if there is a common LLC between all cores in the chip. However, we have recieved information from a source (which can't be confirmed via public AMD documents) that states that Zen will feature two sets of 8MB L3 cache between two groups of four cores each, giving 16 MB of L3 total. This would means 2 MB/core, but it also implies that there is no last-level unified cache in silicon across all cores, which Intel has. The reasons behind something like this is typically to do with modularity, and being able to scale a core design from low core counts to high core counts. But it would still leave a Zen core with the same L3 cache per core as Intel.
| Cache Levels | ||||
| Bulldozer FX-8150 |
Zen | Broadwell-E i7-6950X |
Skylake i7-6700K |
|
| L1 Instruction | 64 KB 2-way per module |
64 KB 4-way | 32 KB 8-way | 32 KB 8-way |
| L1 Data | 16 KB 4-way Write Through |
32 KB 8-way Write Back |
32 KB 8-way Write-Back |
32 KB 8-way Write-Back |
| L2 | 2 MB 16-way per module |
512 KB 8-way | 256 KB 8-way | 256 KB 4-way |
| L3 | 1 MB/core 64-way |
1 or 2 MB/core ? 16-way |
2.5 MB/core 16/20-way |
2 MB/core 16-way |
What this means, between the L2 and the L3, is that AMD is putting more lower level cache nearer the core than Intel, and as it is low level it becomes separate to each core which can potentially improve single thread performance. The downside of bigger and lower (but separate) caches is how each of the cores will perform snoop in each other’s large caches to ensure clean data is being passed around and that old data in L3 is not out-of-date. AMD’s big headline number overall is that Zen will offer up to 5x cache bandwidth to a core over previous designs.








216 Comments
View All Comments
willis936 - Thursday, August 18, 2016 - link
I thought the zen hype was all noise but if they're actually doing what they're claiming they may make up a lot of ground here.BrokenCrayons - Thursday, August 18, 2016 - link
I'd be cautious about that. If AMD was expecting to be extremely competitive, I think the company would be keeping a closer hold on architectural details so as to catch Intel more by surprise. Instead, they're leaning more toward full disclosure which means they're looking to build hype with consumers. One could read into that openness as a harbinger of a mediocre product launch for which Intel might already be well-prepared to meet.And if that's true, I'd be disappointed. We need a more competitive market to kick things along a little even if it won't last for very long thanks to the ever-increasing difficulty in developing smaller transistors.
nandnandnand - Thursday, August 18, 2016 - link
Zen is getting a one time massive boost in IPC due to correcting the failed architecture.The scientists and engineers working at AMD aren't high school dropouts. It's not crazy to think that they can put out something 75-90% as good as Intel, and undercut them on price. Namely because Moore's law is almost dead and Intel has stalled out, delaying 10nm by a year. Let's see 14nm vs. 14nm. The ever-increasing difficulty in developing smaller transistors works to AMD's benefit.
wumpus - Thursday, August 18, 2016 - link
One thing to remember is that GoFlo can't supply more than 10% of the marketshare. Even during AMD's glory days when Intel was floundering with Pentium4 and the Itanic disaster, there simply was no way to take over the market due to the simply inability to supply enough chips (which Intel was able to exploit with exclusive deals to the likes of Dell).Now with no chance of meeting, let alone exceeding the power of Intel (who has vastly more smart guys who have been literally refining this overall architecture for more than 10 years (the current uarch might not be the same as core2, but it is vastly more similar than Zen is to Bulldozer). AMD's only real chance is to find some niche they can beat Intel at, and convince the customers that want it to buy AMD (and yes, the latter is often harder than the former).
Obviously, it looks like AMD is going for the full-thread power. The catch is that *everybody* looks at full-thread power (IBM Power and any competition popping up from the ARM world), so Intel has probably spent more R&D researching how to combat that than AMD spent making the Zen. Intel already wastes enough transistors in the more expensive chips on built-in graphics (chips that will *never* use it considering the relative cost of a GPU to the CPU itself), so they can easily add more cores (which will improve benchmarks and presumably decrease AMD sales, even if they do almost nothing else in the real world than those unused graphics).
Of course, Intel seems to have hit a 10 year plateau (possibly through AMD's, IBM's and ARM's complete inability to compete*). They should certainly not be as surprised by any Intel counters as they may have been with the 1060.
* It must be said that Intel finally admitted that while ARM can't eat Intel's lunch, they can't eat ARM's lunch either. If only this was true for AMD.
mdriftmeyer - Thursday, August 18, 2016 - link
Samsung and GloFo share the same 14nm process, so yes they can provide > 10% of the market.Nagorak - Thursday, August 18, 2016 - link
There are diminishing returns on everything. Having ten times as many "smart people" maybe gives you a 10-20% advantage. AMD can see what worked for Intel and basically reverse engineer it too. The process disadvantage has been pretty much narrowed. It would not surprise me if Zen was competitive with Intel at this point.I'm not sure that I agree with Intel's decision to give up on mobile. Sure they haven't made much headway, but it made sense they were going after it, and I don't think just throwing in the towel was necessarily the right thing to do.
BrokenCrayons - Friday, August 19, 2016 - link
Reverse engineering Intel products and then incorporating those technologies into new AMD products would cause AMD to ALWAYS remain behind Intel because of the latency between reverse engineering and production. To get into that sort of a situation means AMD would never achieve a technological parity or be in a position to rise above the competition. In a competitive market, that's a path to bankruptcy and nothing else. In order to survive, AMD must be innovative, nimble, and aggressive.Kevin G - Saturday, August 20, 2016 - link
If AMD becomes popular again, they can port the design to TSMC for additional volume. They do have a minimum order agreement with GloFo but it isn't truly exclusive.FMinus - Thursday, August 18, 2016 - link
When we get to now the details of an architecture, the competition already knows about it two years ago. There's no point being quiet.jardows2 - Friday, August 19, 2016 - link
I'm not so sure about that. It's not like the GPU market where there is lots of fluidity in the technology. Intel is pretty much locked in for features/improvements for the next few years. A few details about their competitor, coming this close to release, isn't going to change anything Intel does. It's not like Intel is in the position to radically redesign Kaby Lake or Cannon Lake, and after that is so far out that it is irrelevant to Zen's launch.I think AMD is doing a smart move by releasing more details. Perhaps they feel the sting of hyping up Bulldozer so much, but releasing few details, and getting trashed in real-world performance. For Zen, release more details so the hype doesn't dwarf the reality, and give people the desire to purchase the product.