Assessing IBM's POWER8, Part 1: A Low Level Look at Little Endian
by Johan De Gelas on July 21, 2016 8:45 AM ESTMulti Threading Prowess
The gains of 2-way SMT (Hyperthreading) on Intel processors are still relatively small (10-20%) in many applications. The reason is that threads have to share most of the critical resources such as L1-cache, the instruction TLB, µop cache, and instruction queue. That IBM uses 8-way SMT and still claims to get significant performance gains piqued our interest. Is this just benchmarketing at best or did they actually find a way to make 8-way SMT work?
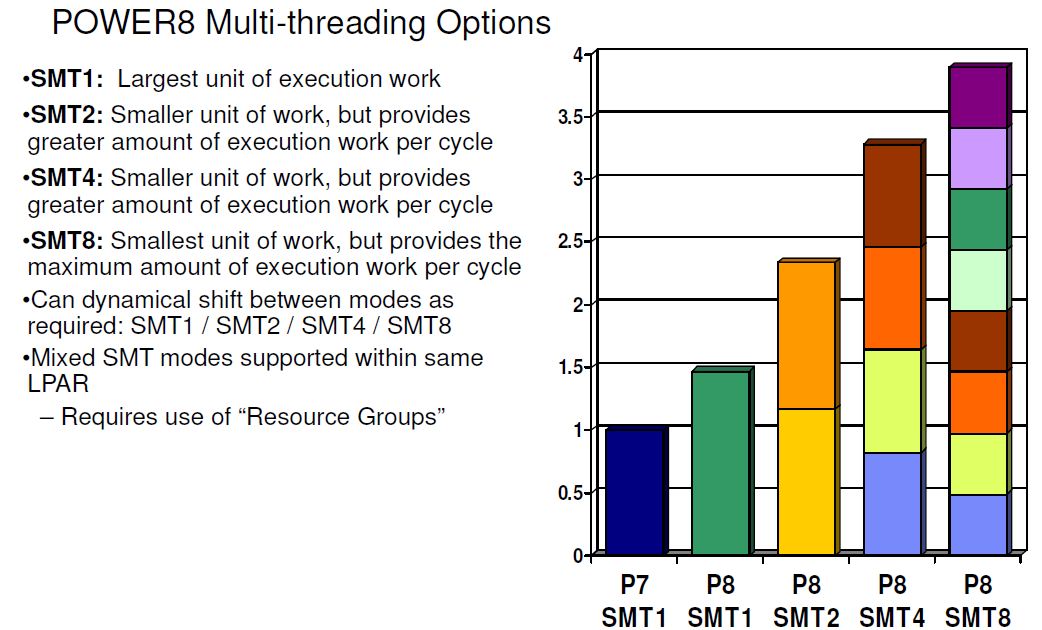
It is interesting to note that with 2-way SMT, a single thread is still running at about 80% of its performance without SMT. IBM claims no less than a 60% performance increase due to 2-way SMT, far beyond what Intel has ever claimed (30%). This can not be simply explained by the higher amount of issue slots or decoding capabilities.
The real reason is a series of trade-offs and extra resource investments that IBM made. For example, the fetch buffer contains 64 instructions in ST mode, but twice as many entries are available in 2-way SMT mode, ensuring each thread still has a 64 instruction buffer. In SMT4 mode, the size of the fetch buffer for each thread is divided in 2 (32 instructions), and only in SMT8 mode things get a bit cramped as the buffer is divided by 4.
The design philosophy of making sure that 2 threads do not hinder each other can be found further down the pipeline. The Unified Issue Queue (UniQueue) consists of two symmetric halves (UQ0 and UQ1), each with 32 entries for instructions to be issued.
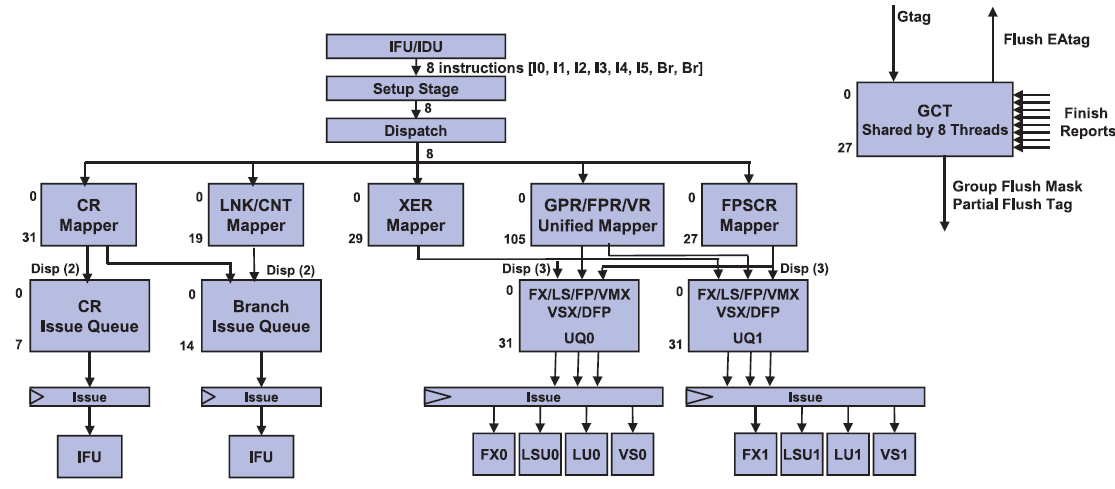
Each of these UQs can issue instructions to their own reserved Load/Store, Integer (FX), Load, and Vector units. A single thread can use both queues, but this setup is less flexible (and thus less performant) than a single issue queue. However, once you run 2 threads on top of a core (SMT-2), the back-end acts like it consists of two full-blown 5-way superscalar cores, each with their own set of physical registers. This means that one thread cannot strangle the other by using or blocking some of the resources. That is the reason why IBM can claim that two threads will perform so much better than one.
It is somewhat similar to the "shared front-end, dual-core back-end" that we have seen in Bulldozer, but with (much) more finesse. For example, the data cache is not divided. The large and fast 64 KB D-cache is available for all threads and has 4 read ports. So two threads will be able to perform two loads at the same time. Another example is that a single thread is not limited to one half, but can actually use both, something that was not possible with Bulldozer.
Dividing those ample resources in two again (SMT-4) should not pose a problem. All resources are there to run most server applications fast and one of the two threads will regularly pause when a cache miss or other stalls occur. The SMT-8 mode can sometimes be a step too far for some applications, as 4 threads are now dividing up the resources of each issue queue. There are more signs that SMT-8 is rather cramped: instruction prefetching is disabled in SMT-8 modus for bandwidth reasons. So we suspect that SMT-8 is only good for very low IPC, "throughput is everything" server applications. In most applications, SMT-8 might increase the latency of individual threads, while offering only a small increase in throughput performance. But the flexibility is enormous: the POWER8 can work with two heavy threads but can also transform itself into a lightweight thread machine gun.








124 Comments
View All Comments
JohanAnandtech - Thursday, July 21, 2016 - link
I don't think so, we just expressed it in ns so you can compare with IBM's numbers more easily. Can you elaborate why you think they are wrong?Taracta - Thursday, July 21, 2016 - link
Sorry, mixed up cycles with ns especially after reading the part about transition for the Intel from L3 to MEM.Sahrin - Thursday, July 21, 2016 - link
Yikes. Pictures without captions. Anandtech is terrible about this. ALWAYS caption your pictures, guys.djayjp - Thursday, July 21, 2016 - link
Are bar graphs not a thing anymore...?Drumsticks - Thursday, July 21, 2016 - link
Afaik, Anandtech has always used the chart when presenting things like SPEC. I'd guess it'd be for clutter reasons, but the exact reason is up to the editors to mention.JohanAnandtech - Thursday, July 21, 2016 - link
The reason for me is simply to give you the exact numbers and allow people to do their own comparisons.Drumsticks - Thursday, July 21, 2016 - link
Just to be clear, the Xeon CPU used today is 3 times more expensive than the Power8 CPU benchmarked? That's really impressive, isn't it? The Power8 has a pretty significant power increase, but if it's 43% faster, that cuts into the perf/w gap.I know we've only looked at SPEC so far in round 2, but this looks like a good showing for IBM. How big is the efficiency gap between 22nm SOI and 14nm FinFet? Any estimates?
Michael Bay - Thursday, July 21, 2016 - link
Selling at a loss is hardly impressive, especially in IBM`s case. This thing is literally their last chance.tipoo - Friday, July 22, 2016 - link
Is it at a loss, or is it just not at crazy Intel margins?Michael Bay - Saturday, July 23, 2016 - link
They`d have to have a healthy margin to offset all the R&D, plus IBM as a whole is not in a good financial position. Consider they sold their fab capability not so long ago.