Examining Soft Machines' Architecture: An Element of VISC to Improving IPC
by Ian Cutress on February 12, 2016 8:00 AM EST- Posted in
- CPUs
- Arm
- x86
- Architecture
- Soft Machines
- IPC
The Data: Soft Machines' Proof
Ever since the initial announcement of the VISC architecture in 2014 there has been a element of it sounding too good to be true, and Soft Machines' 2016 announcements have come with yet more questions as well. Aside from questions requiring more information about the architecture and ISA, the big money questions relate to performance. We mentioned a couple of pages back that the original 28nm design made its way to silicon at 500 MHz and was shown as a proof of concept. At the 2014 conference, the platform was compared to both ARM and x86 and offered better scores on Denbench compared to both while also using less power. Now that Shasta is on the 16nm node, the big question is how the new design at a 2 GHz frequency compares, and if the increase in frequency has upset some of the IPC gains.
So it’s at this point that we have to show this graph before we can progress any further. This is a graph which has caused a lot of commotion among the analyst community, because it can be a very difficult graph to digest and work out what is going on. I’ll take you through it. But to start, ignore the vertical dashed lines.
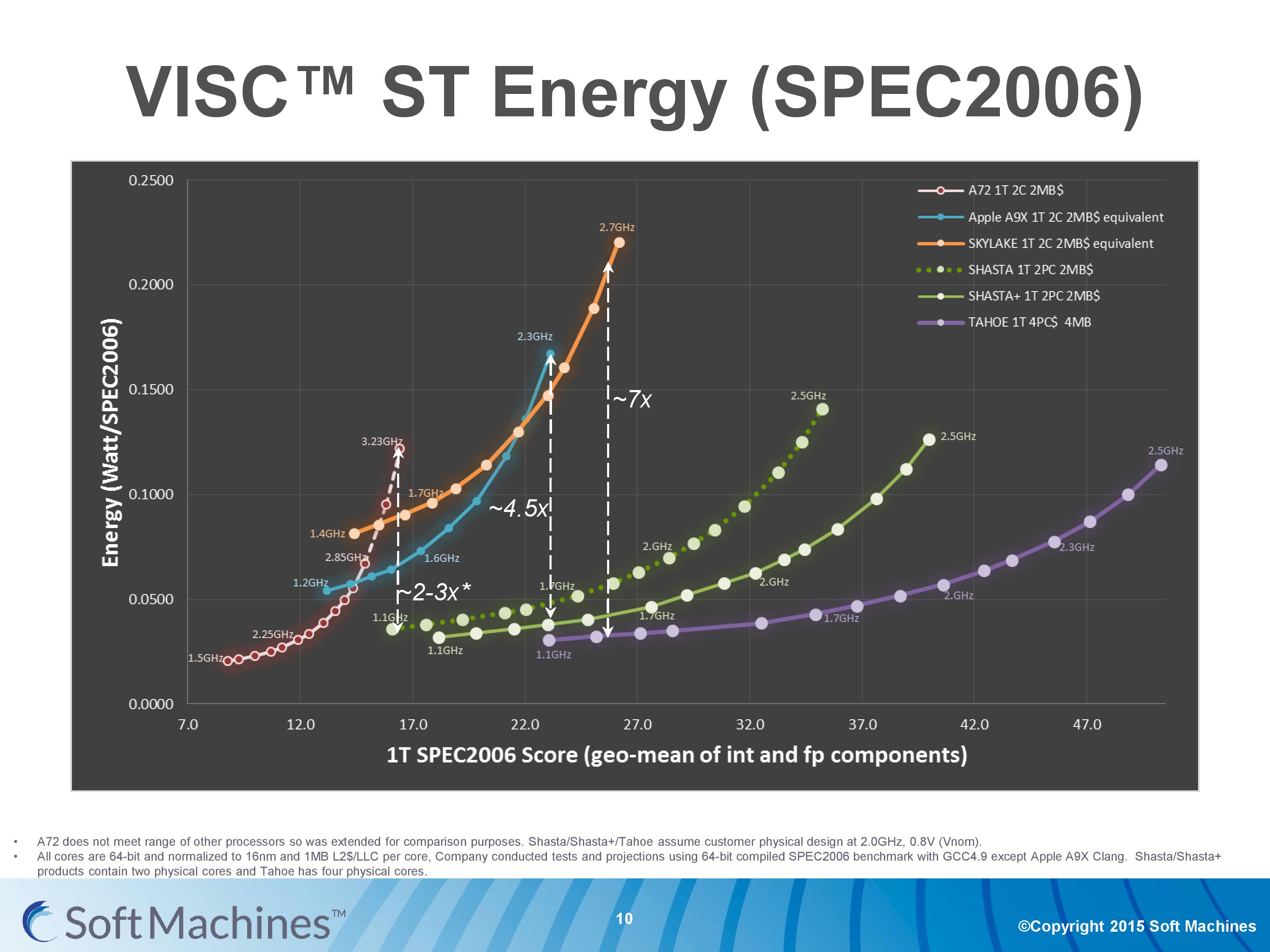
This is a graph from Soft Machines attempting to show the efficiency of several CPUs cores: Cortex-A72, Apple’s Twister (A9X), Skylake, Shasta, Shasta+ (2017), and Tahoe (2018). It is a graph of the average power consumed per unit SPEC2006 score plotted against the SPEC2006 score, and each dot on a line shows the relative score of each CPU at a given frequency.
The reason why this graph has caused a lot of commotion is that it shows a lot of data based on a lot of assumptions displayed in a very odd way. The following points are worth mentioning
| The Scores #1 | This graph shows the geometric mean of SPEC2006int and SPEC2006fp, the integer and floating point parts of the SPEC2006 set of benchmark tools. Because different architectures focus on integer and floating point performance to differing degrees (more units focused on INT or FP), these results are typically given separately, with individual subtest scores. Practically no-one in the industry puts them together as a geometric mean, which has some analysts wondering if there are certain subtests where VISC scores particularly low. |
| The Scores #2 | This graph shows only single threaded results, even though each CPU is listed as having two cores in the data but running a single thread. This puts the Soft Machines cores in the best light, as a single thread has access to all the ports on two cores as well as two re-order buffers and two cores' worth of L2 cache. |
| Conversion #1 | All the results have been converted as if each CPU design has 1MB of last level cache per core. This means that designs such as the A9X and Skylake CPUs have been reduced, and scores have been adjusted by ambiguous ‘industry standard techniques’ according to SMI. A number of analysts say that this is not a fair conversion, as an A9X core or Skylake core with less cache would be arranged differently in silicon to take advantage of more space for other things or lower latencies. |
| Conversion #2 | All the results have been converted to 16nm FinFET+ on TSMC, again by ‘industry standard techniques’. This is a hard one to grasp, because core designs are not simply ‘shrunk’ from one node to another. Similar to the cache situation, each process node can be optimized for metal layers and arrangement for latency and bandwidth optimizations. Each conversion, such as Intel’s 14nm to TSMC 16nm, or TSMC’s 28nm -> 16nm, would have to be thoroughly examined. Extrapolating from 28nm to 16nm would be an exasperating task to be accurate (and this level of extrapolation wouldn’t be acceptable even in a high school classroom as I pointed out). |
| Testing #1 | Not all points on the graph come from direct data. Each line has had several points taken from data and the rest are interpolated given basic power formulas. |
| Testing #2 | The platforms used are not all what they appear to be. So for example, the best Cortex-A72 16nm data point would be the Kirin 950 in the Huawei Mate 8, but instead a dual A72 was used from the Amazon Fire TV which as a 28nm MediaTek MT8173 running at 1.98 GHz. One could argue that A72 is new enough and only recently on 28nm that it isn’t fully optimized for the process yet and this is probably a low end version of that silicon. The Apple A9X numbers are actually taken from a 14nm A9 and the assumption was made that the dynamic power in a cold environment was similar to the A9X. The Skylake numbers were a mid-range Core i5-6200U in a Dell laptop, which could be prone to variable turbo modes or overheating, and that specific SKU is hardly the most power efficient model in Intel’s Skylake lineup. |
| Compilers | In order to ‘normalize’ the data, each of the actual data points taken were as a result of SPEC2006 being compiled on GCC 4.9 (or Clang for Apple). Typically for SPEC we normally consider the peak numbers possible with the best compiler, and as pointed out by some analysts, Intel’s results on their compiler can get scores more than double that of GCC, which can put a negative bent on Intel’s numbers. |
| Simulations | Almost all of SMI’s numbers come from internal RTL simulation of their IP designs. With the 28nm proof-of-concept chip, we were told that the difference between simulation and physical was around 5-10% on performance and power, but some chip designers have pointed out that performance on a simulated processor can be anywhere from 33-50% inaccurate from the peak theoretical performance when you actually put it into silicon. |
| Optimizations | The data shown in this graph for the VISC processors is based on assumptions relating to process optimization. The way the design is to be sold means that licensees can work with the foundries to optimize the metal stack layers or other design characteristics to get better power or higher frequencies. I was told that this was put into the graph at an assumed value around 10%, and the data in the graph includes this. |
Typically any one of these points in most contexts would be grounds to be apprehensive about the results. The fact that there are nine salient points here listed (and I may even have missed one or two) means that the data should be thrown out entirely.
Clarification on the Data from Soft Machines
Because we were one of the last media outlets to speak with Soft Machines, and I had already seen some discussion around these points, I posed the issues back to them, as well as a few questions of my own. Because of the response that had been presented, we managed to get a lot of details around the simulation and assumptions aspects. So to start, here’s the testing methodology that everyone was provided with:

For clarity on the VISC processors, simulations were done to be both signal accurate and cycle accurate, and data taken from 16nm design configurations. Both power and results were taken from these.
For the power on the other parts, the power consumption was taken at the wall. To remove system power from the equation, the system was run in 2C vs 1C modes and 1C vs idle modes at various frequencies to find the dynamic power. Each platform was tested in a cold environment to ensure the maximum temperature did not go above 55C. Each of the power numbers are estimates that have removed the production yield ‘guard’ (i.e. protection overestimate), which was about ~15%, giving benefits to the non-VISC core results.
For the power conversion to 16nm FinFET+ on TSMC:
- The A72 28nm TSMC used TSMC’s numbers for scaling.
- For the A9X numbers, the A9 numbers were taken in a cool environment to minimize Samsung 14nm leakage and the dynamic power for the A9X is assumed the same as the A9.
- For Intel, using public data it was assumed that 16FF+ voltage is 10-15% higher and area is 30% larger, giving ~1.65x power on 16FF+.
- Leakage scales with die area.
For performance testing:
- Linaro GCC 4.9 with -O3 -mcpu=cortex-a57 -static -flto -ffast-math
- If any test failed, results were taken from previous generations and expected percentage increases. For example, FORTRAN on A9 failed, so estimates were taken from the floating point numbers in C.
- For the cache adjustments, for 3MB to 2MB was reduced 3.5-4%. Because Intel has L2+L3, this is reduced a further 5%. For A72 moving from 1MB L2 to 2MB L2 in total, score was increased by 4%.
For a full rundown, this was the slide provided to us:

As part of these assumptions, I did ask about the raw data collected and if that would ever be presented. I did mention that they really need to split up INT and FP results, and I was told that it may happen at a later date but not right now. What I was given though was the effect of the cache adjustment on Skylake.
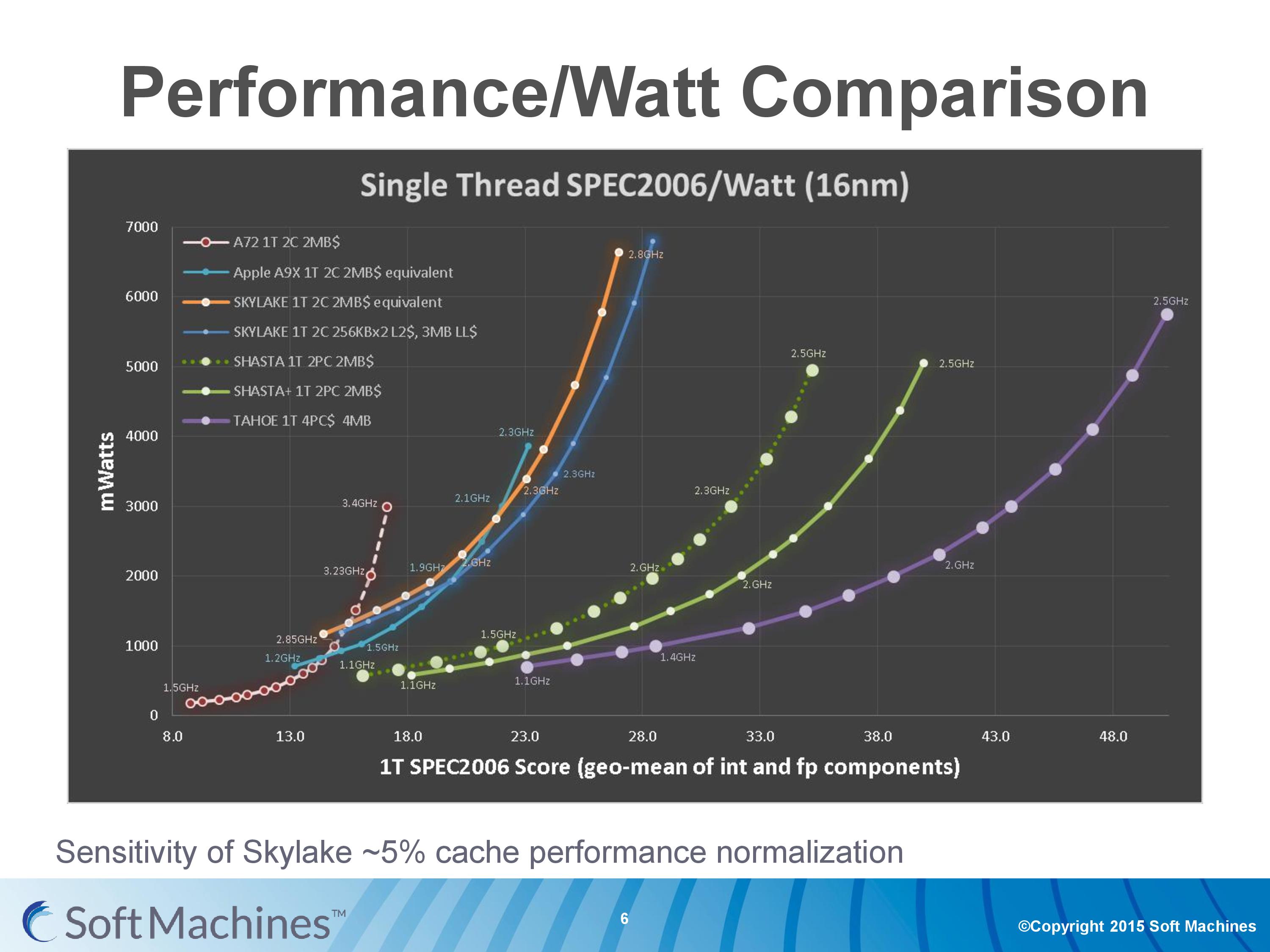
The orange line and the blue line next to it represents the movement from a multi-cache hierarchy of L2+L3 to 1MB of L2 cache per core only. The blue line still has the assumption of moving from 14nm to 16FF+, and using the GCC compiler, but the orange line has that extra assumpton.
Personally, these assumptions make me uneasy. Conversions like this are typically only done as back-of-the-envelope types of calculations during the early stages of design, because they are very rough and do not take into account things like silicon floor-plan optimization that would occur if you chose a smaller/larger cache arrangement, or changing from 8-way to 4-way associativity in the caches and so on. Typically we see companies in similar positions to SMI provide the raw or semi-modified data, using one assumption at most, with a split between FP and INT results - e.g. taking all the results as-is with GCC. The reason why it all comes into one graph is for brief simplicity, which doesn't particularly endear any reader/investor who might decide to be heavily invested in this project.
We pointed out a lot of concerns with this data to Soft Machines, including the list above of assumptions and how some of them simply do not make sense and should be restricted to that those quick rough calculations, especially when presenting at a conference. They gave us the graph above showing the effect of cache changes on Skylake, but I have asked in the future for them to display the data in a less complicated way, using standard industry metrics (such as INT or FP). Ideally the graphs are also kept to two or three data sets without requiring a 9-point interpretation scheme to understand what is happening - we typically get a dozen or so graphs from Huawei, ARM, AMD or Intel when they are describing their latest architecture or microarchitecture designs. This allows more understanding of what is happening under the hood and can be used to validate the results - as it stands, it is difficult to validate anything due to the assumptions and conversions made.








97 Comments
View All Comments
Bleakwise - Tuesday, March 14, 2017 - link
I mean IBM does this with the POWER8 very successfully.Bleakwise - Tuesday, March 14, 2017 - link
If you would like to know how an Superscaler CPU can beat an in-order CPU....https://en.wikipedia.org/wiki/Instruction-level_pa...
https://en.wikipedia.org/wiki/Superscalar_processo...
https://en.wikipedia.org/wiki/Instruction-level_pa...
So a Processor with 6 pipelines can do
1*2*3*4*5*6 in one instructoin
a processor with 12 piplines can do
1*2*3*4*5*6*7*8*9*10*11*12
in one clock cycle
This is the opposite of hyper threading, which allows my 4770k with 5 pipelines to do
1*2*3*4*5
or
1*2*3 and 4*5
or
1*2 and 3*4*5
all in one clock cycle.
jjj - Friday, February 12, 2016 - link
What they do with A72 in their slides is a huge red flag. They clock it above 3GHz on 16ff to make it look bad. When you don't need to distort the truth why do it? Was excited about them but they lost all credibility with this.vs ARM it will be hard for them ,assuming ARM will have yearly updates and a broader range of cores. Area will also matter a lot Ofc vs ARM the proper math when it comes to perf, power, thermal and area would be to include dark silicon. ARM is at 8-10 cores in 2-3 clusters but we might see even more than that (i would add a gaming cluster, as GPU perf is a rather complicated problem right now).
Hope we do get to see them in commercial products and i wonder about their longer term plans. Would be interesting if they would aim for a lot more cores at very low power and even cooler if they would aim to use different types of cores - as undoable as all that might be lol. For glasses we need a huge step forward that process and packaging might fail to enable soon enough and even server might find such a path preferable. Would love to see 1T 32PC at 50-100mW on 5nm. Or ,to just go crazy, would be great if they could reach low enough power (thermal) to stack logic and go monolithic 3D since folks are not quite able to do that , for now.
Guess , it would be great if you could ask them how far they think they can push with the number of cores in a thread.
gamerk2 - Friday, February 12, 2016 - link
Odds are, Soft Machines gets acquired by Intel (who want a low-power core for mobile. And hey, ARM support to eliminate the lack of mobile X86 software to boot) or NVIDIA (who want a CPU core, and hey, already have ARM based tablets. X86 support is a bonus an could allow full NVIDIA branded PCs).jjj - Friday, February 12, 2016 - link
It would be easier for Intel or ARM to just copy. Additionally, a sale to Intel would be difficult with Samsung and AMD as investors in SM.fiodhkf - Friday, February 12, 2016 - link
I don't understand these results. How are skylake specint and spefp scores so low? On spec.org the weakest skylake part I could quickly find is Celeron G3900 at 2.8 GHz and 2MB L3 (and huge power consumption, but let's ignore that for now). It has CINT2006 of ~45 and CFP2006 of ~61. Can i5-6200U be that much slower?extide - Friday, February 12, 2016 - link
Because those are NOT the results of a skylake chip, those are their adjusted results of a chip that is equivalent to skylake, but with 1MB L2, no L3, and made on TSMC's 16nmFF+, which is a chip that will NEVER exist in the wild and is POINTLESS to compare to as these guys will never be competing against a made up chip, only the actual stuff released by Intel, and other people.fiodhkf - Friday, February 12, 2016 - link
In the second Performance/Watt comparisonfigure the blue curve is supposed to(?) show the true unscaled-for-cache skylake (power is probably scaled to TSMC 16nmFF+, but surely they're not scaling the performance as well). Even there the skylake spec scores are only about half of what they should be according to results on spec.org.Exophase - Friday, February 12, 2016 - link
The spec.org scores are using ICC, which has optimizations that game a few SPEC2006 subtests like crazy. They also apply auto-par and pointer compression optimizations that aren't applied in GCC. There's also some extra optimizations for peak if you're looking at that but it doesn't make a huge difference in the overall score.All of this adds up to big differences in SPEC score.
fiodhkf - Friday, February 12, 2016 - link
Thanks, that was pretty much what I guessed would be one explanation for the difference. Still, I'm a bit surprised with the low skylake scores even when compared to some (old) AMD processors where spec.org scores used open64. But I don't care quite enough to try myself.