GIGABYTE F2A85XN-WiFi Review: FM2 and Richland in mini-ITX
by Ian Cutress on August 21, 2013 10:00 AM ESTComputation Benchmarks
Readers of our motherboard review section will have noted the trend in modern motherboards to implement a form of MultiCore Enhancement / Acceleration / Turbo (read our report here) on their motherboards. This does several things – better benchmark results at stock settings (not entirely needed if overclocking is an end-user goal), at the expense of heat and temperature, but also gives in essence an automatic overclock which may be against what the user wants. Our testing methodology is ‘out-of-the-box’, with the latest public BIOS installed and XMP enabled, and thus subject to the whims of this feature. It is ultimately up to the motherboard manufacturer to take this risk – and manufacturers taking risks in the setup is something they do on every product (think C-state settings, USB priority, DPC Latency / monitoring priority, memory subtimings at JEDEC). Processor speed change is part of that risk which is clearly visible, and ultimately if no overclocking is planned, some motherboards will affect how fast that shiny new processor goes and can be an important factor in the purchase. Processors which were tested on MultiCore Turbo enabled systems are indicated with a '+' symbol in the graphs.
With XMP enabled, the GIGABYTE F2A85XN-WiFi exhibited full MultiCore Turbo, resulting in a 44x multiplier throughout our benchmarks. This confirms that this ‘addition’ to the BIOS has now made the move to AMD.
Point Calculations - 3D Movement Algorithm Test
The algorithms in 3DPM employ both uniform random number generation or normal distribution random number generation, and vary in various amounts of trigonometric operations, conditional statements, generation and rejection, fused operations, etc. The benchmark runs through six algorithms for a specified number of particles and steps, and calculates the speed of each algorithm, then sums them all for a final score. This is an example of a real world situation that a computational scientist may find themselves in, rather than a pure synthetic benchmark. The benchmark is also parallel between particles simulated, and we test the single thread performance as well as the multi-threaded performance.
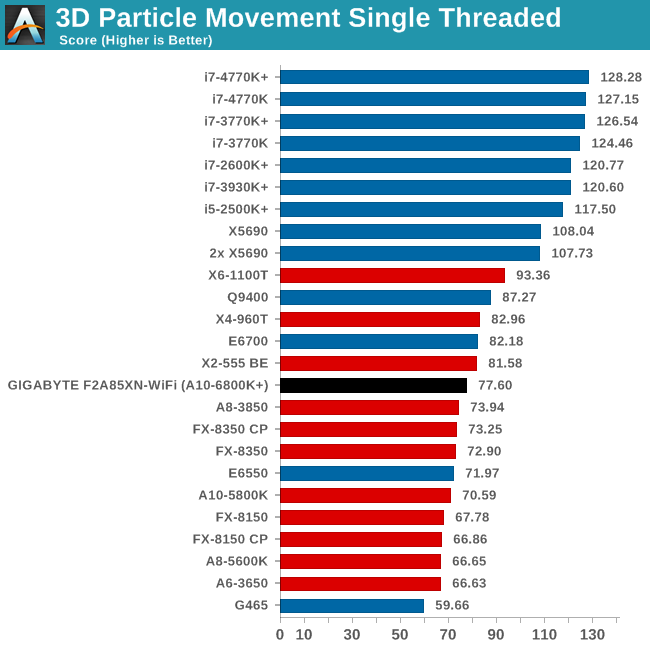
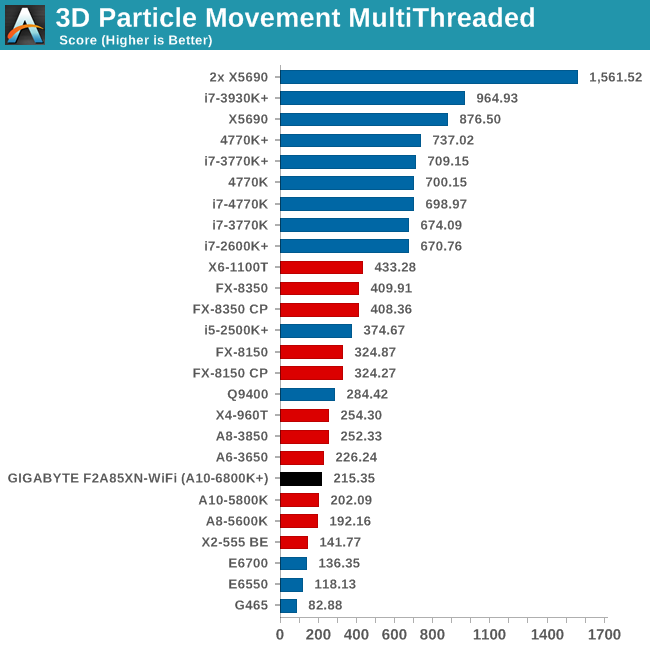
In the single threaded test we get a clear 10% difference from the A10-5800K. This is not seen in multi-threaded mode, as all the modules are filled with FP operations.
Compression - WinRAR 4.2
With 64-bit WinRAR, we compress the set of files used in the USB speed tests. WinRAR x64 3.93 attempts to use multithreading when possible, and provides as a good test for when a system has variable threaded load. WinRAR 4.2 does this a lot better! If a system has multiple speeds to invoke at different loading, the switching between those speeds will determine how well the system will do.
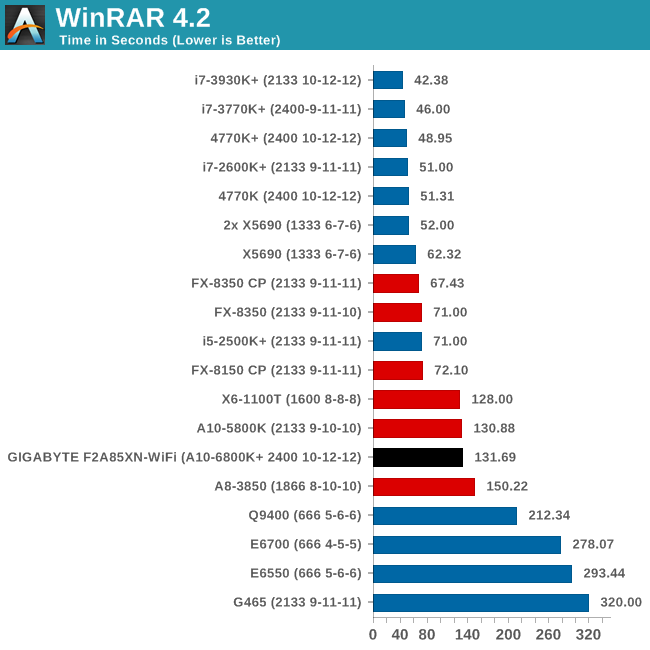
Similar to 3DPM-MT, filling the CPU with operations seems to equate the A10-5800K with the A10-6800K.
Image Manipulation - FastStone Image Viewer 4.2
FastStone Image Viewer is a free piece of software I have been using for quite a few years now. It allows quick viewing of flat images, as well as resizing, changing color depth, adding simple text or simple filters. It also has a bulk image conversion tool, which we use here. The software currently operates only in single-thread mode, which should change in later versions of the software. For this test, we convert a series of 170 files, of various resolutions, dimensions and types (of a total size of 163MB), all to the .gif format of 640x480 dimensions.
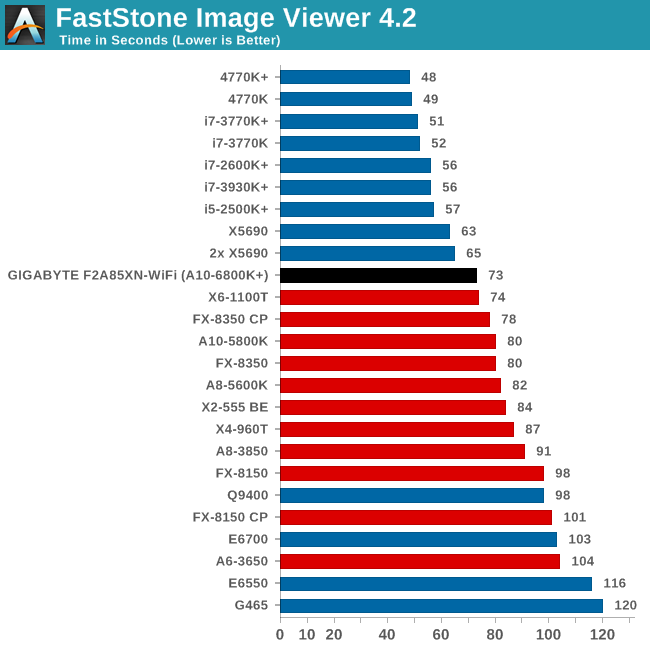
In single threaded mode for FastStone, the A10-6800K records the fastest AMD time we have seen.
Video Conversion - Xilisoft Video Converter 7
With XVC, users can convert any type of normal video to any compatible format for smartphones, tablets and other devices. By default, it uses all available threads on the system, and in the presence of appropriate graphics cards, can utilize CUDA for NVIDIA GPUs as well as AMD WinAPP for AMD GPUs. For this test, we use a set of 33 HD videos, each lasting 30 seconds, and convert them from 1080p to an iPod H.264 video format using just the CPU. The time taken to convert these videos gives us our result.
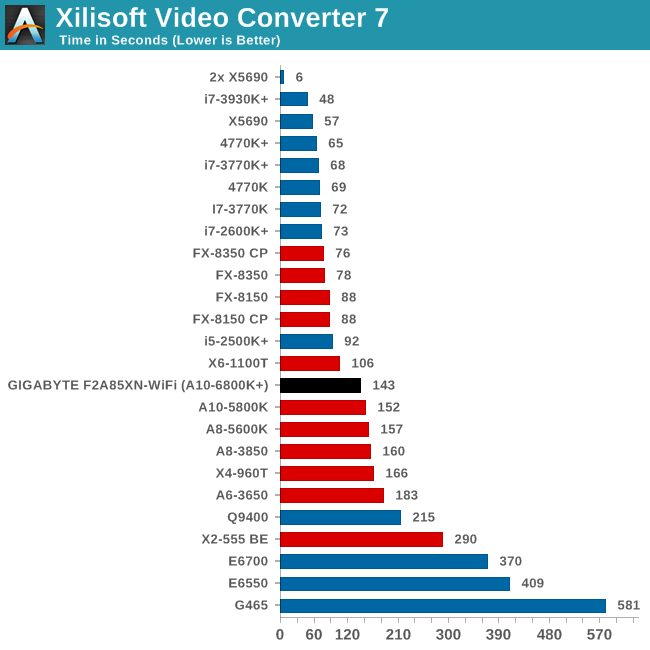
With four threads to play with, the A10-6800K falls behind the AMD cores with more threads, but beats out the A10-5800K.
Rendering – PovRay 3.7
The Persistence of Vision RayTracer, or PovRay, is a freeware package for as the name suggests, ray tracing. It is a pure renderer, rather than modeling software, but the latest beta version contains a handy benchmark for stressing all processing threads on a platform. We have been using this test in motherboard reviews to test memory stability at various CPU speeds to good effect – if it passes the test, the IMC in the CPU is stable for a given CPU speed. As a CPU test, it runs for approximately 2-3 minutes on high end platforms.
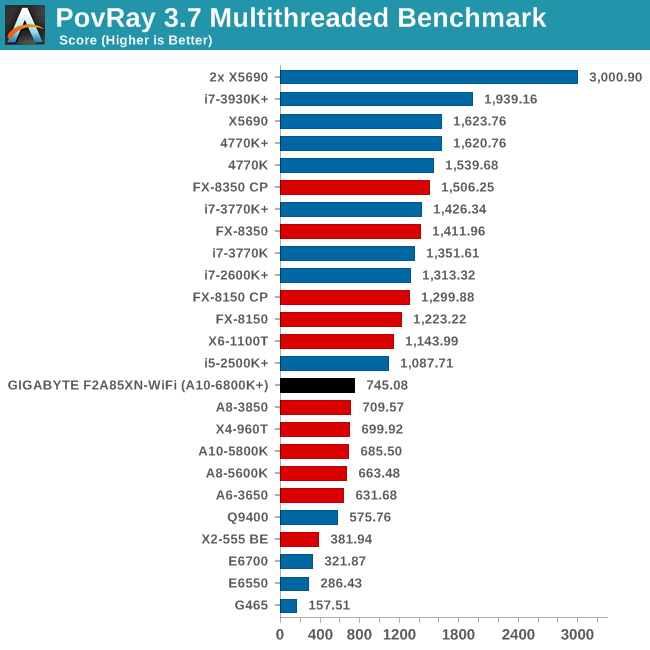
PovRay is a good indicator of pure unconstrained performance, and we get another 10% jump from the A10-5800K to the A10-6800K.
Video Conversion - x264 HD Benchmark
The x264 HD Benchmark uses a common HD encoding tool to process an HD MPEG2 source at 1280x720 at 3963 Kbps. This test represents a standardized result which can be compared across other reviews, and is dependent on both CPU power and memory speed. The benchmark performs a 2-pass encode, and the results shown are the average of each pass performed four times.
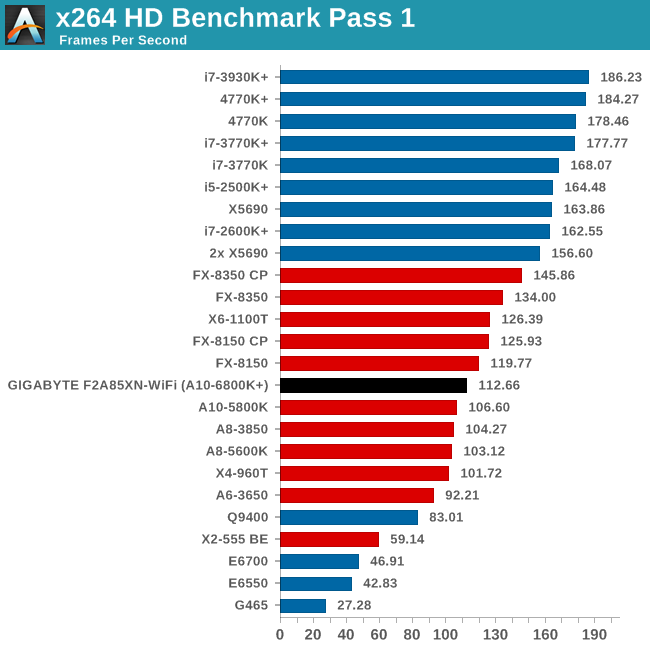
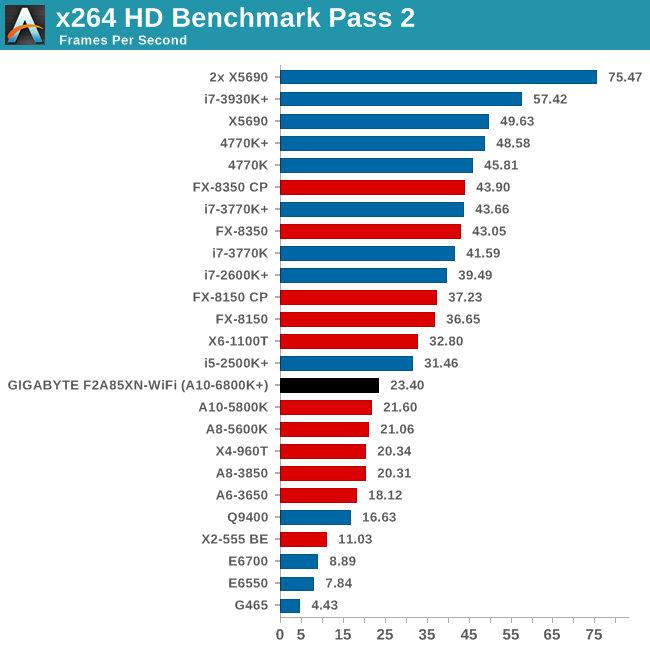
Grid Solvers - Explicit Finite Difference
For any grid of regular nodes, the simplest way to calculate the next time step is to use the values of those around it. This makes for easy mathematics and parallel simulation, as each node calculated is only dependent on the previous time step, not the nodes around it on the current calculated time step. By choosing a regular grid, we reduce the levels of memory access required for irregular grids. We test both 2D and 3D explicit finite difference simulations with 2n nodes in each dimension, using OpenMP as the threading operator in single precision. The grid is isotropic and the boundary conditions are sinks. Values are floating point, with memory cache sizes and speeds playing a part in the overall score.
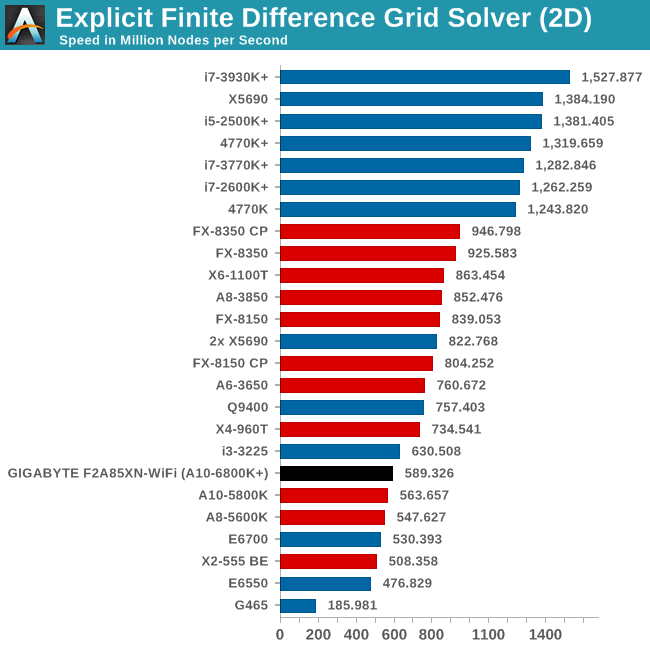
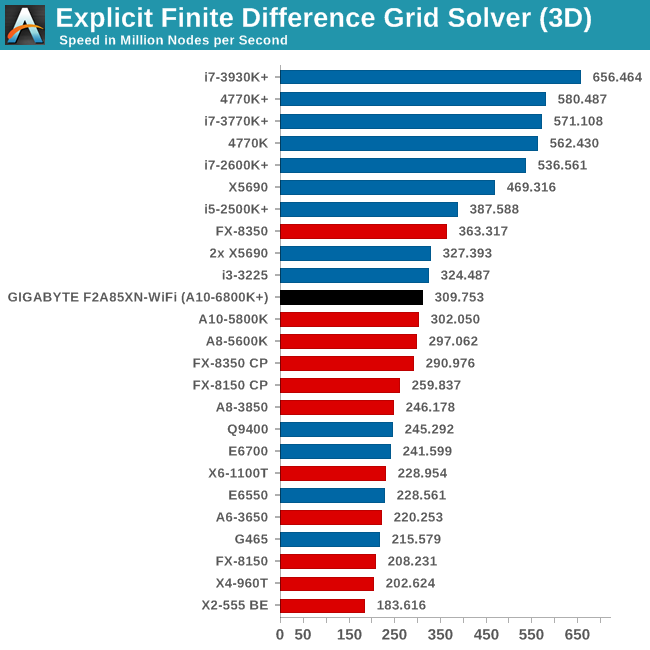
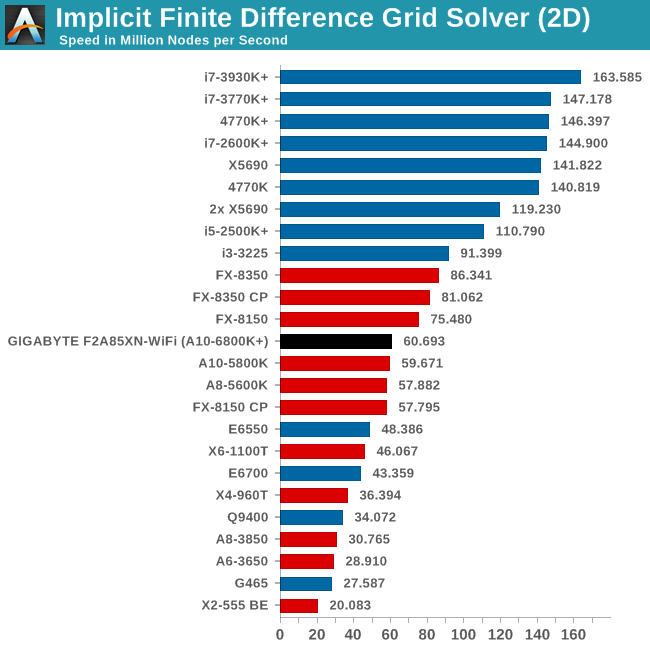
Grid Solvers - Implicit Finite Difference + Alternating Direction Implicit Method
The implicit method takes a different approach to the explicit method – instead of considering one unknown in the new time step to be calculated from known elements in the previous time step, we consider that an old point can influence several new points by way of simultaneous equations. This adds to the complexity of the simulation – the grid of nodes is solved as a series of rows and columns rather than points, reducing the parallel nature of the simulation by a dimension and drastically increasing the memory requirements of each thread. The upside, as noted above, is the less stringent stability rules related to time steps and grid spacing. For this we simulate a 2D grid of 2n nodes in each dimension, using OpenMP in single precision. Again our grid is isotropic with the boundaries acting as sinks. Values are floating point, with memory cache sizes and speeds playing a part in the overall score.
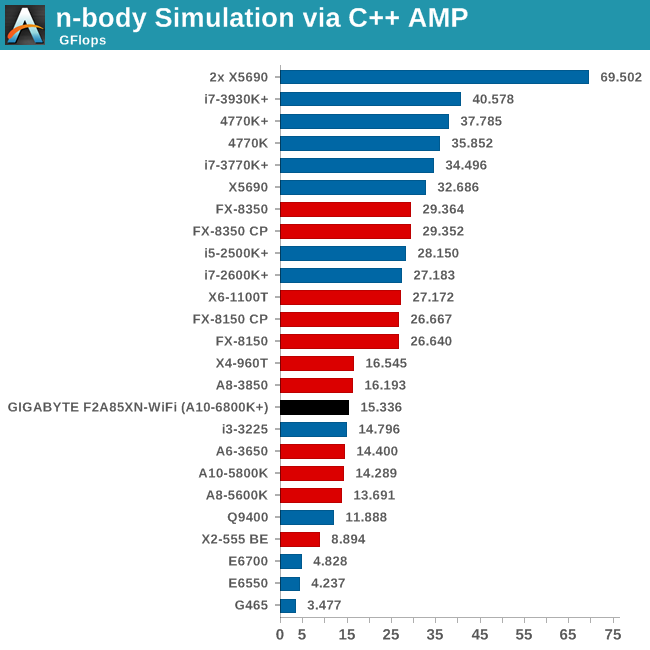
Point Calculations - n-Body Simulation
When a series of heavy mass elements are in space, they interact with each other through the force of gravity. Thus when a star cluster forms, the interaction of every large mass with every other large mass defines the speed at which these elements approach each other. When dealing with millions and billions of stars on such a large scale, the movement of each of these stars can be simulated through the physical theorems that describe the interactions. The benchmark detects whether the processor is SSE2 or SSE4 capable, and implements the relative code. We run a simulation of 10240 particles of equal mass - the output for this code is in terms of GFLOPs, and the result recorded was the peak GFLOPs value.








31 Comments
View All Comments
DanNeely - Wednesday, August 21, 2013 - link
Every time I look at the ultra-crowded layout of an mITX board I'm reminded of how dated the main 24 ATX power plug is and how much it would benefit from being replaced. While they were king in the p1 era with the CPU and PCI busses running on 3.3v directly and most other chips on the board designed for 5V; 3.3 and 5V are barely used at all any more but have 3 and 5 wires in the 24pin cable; while -5V has been removed entirely from modern versions of the spec. Dropping to a single 3.3/5v wire and removing the -5v one would free 7 pins directly; and with only 4 power pins left in the legacy connector (3.3, 5, 2 x 12) there's no need for 8 ground pins either. Probably we could drop 5 of them.This would allow for a successor cable that's only half as large; freeing space on crowded boards and replacing the 24wire cable with a 12 wire one that would be much less of a pain to route in a crowded case. I'm inclined to keep the CPUs 12V separate just to avoid trading one overly fat wire bundle for another and because AIUI the other half of why the CPUs 12V comes in separately is to get it as close to the socket as possible without crowding the area with everything else.
EnzoFX - Wednesday, August 21, 2013 - link
Yes, I've been saying this since ITX was taking hold. It is absurd how held back we are by entrenched standards. It's not in their business to reinvent.Jambe - Thursday, August 22, 2013 - link
I enjoyed this astute observation-comment.Right on.
That is all.
cjs150 - Friday, August 23, 2013 - link
Totally agree on the ATX cable.While we are at why do motherboards virtually never come with the ATX connector being at right angles rather than straight up - we get that for SATA connectors and it seriously improves cable management
flemeister - Friday, August 23, 2013 - link
Not such a good idea for mITX boards, when you might expect to install them in small cases such as the Antec ISK110 or Minibox M350. Right-angled ATX power or sata ports would be blocked off.How about RAM though? Why not use SO-DIMMs that are about 60% the size of regular DIMMs? They're readily available, and are priced the same or very close to the price of regular size RAM. Assuming two sticks of RAM, that would save even more room on the motherboard than a redesign of the 24-pin connector. Just look at the Asus P8H67-I Deluxe for an example. :)
DanNeely - Friday, August 23, 2013 - link
It's not just mITX boards that would have a problem with right angled ATX power sockets. Unless the PSU also included a right angle 24pin cable it would be problematic in any case that uses cable management holes to route the cables behind the mobo tray. Trying to make a 90* bend in that cramped a space would put a lot of torque on the socket; a big ugly loop sticking up allows for a much looser and less stressful bend.DanNeely - Friday, August 23, 2013 - link
For dimm sizes I think it's mostly a capacity issue. For more modest builds it probably doesn't matter; but higher capacities tend to come out a year or two sooner in full size dimms because you can jam more chips onto them if need be. Currently DDR3 dimms and sodimms both max out at 8GB for desktops; but if you're willing to pay the price premium server ram is available in up to 32GB dimms.flemeister - Saturday, August 24, 2013 - link
True, but how about SO-DIMMs on a budget Intel H81/B85 or AMD A55/A75 board? Or one of the low-power Intel Atom or AMD Brazos ITX boards? Or even a budget Z87 ITX board, to avoid the need for a vertically mounted VRM daughterboard (unless that's actually cheaper to do)? More space for surface mounted components, and probably cheaper to make the board? Could also mean less PCB layers?DanNeely - Saturday, August 24, 2013 - link
You're only saving 36 pins/dimm (204 vs 240); so there's no where near enough savings to drop a PCB layer. Beyond that I'd guess that since they do offer some models with SoDIMM slots that they just don't sell as well. If I had to guesses why it'd be that people are more likely to have spare DIMMs laying around than spare SoDIMMs; meaning that the total build cost is lower since the ram is free and/or the cost savings from larger DIMMs are enough to drive shoppers.The one configuration I could see driving some enthusiast/gamer consumption of SoDIMM based mITX boards would be 4 slots instead of only 2 for 32GB max instead of 16; is conspicuous by its absence.
Hyoyeon - Wednesday, August 21, 2013 - link
You mention DisplayPort several times, but this board does not have a DP connector. Where did this come from?