The Bulldozer Aftermath: Delving Even Deeper
by Johan De Gelas on May 30, 2012 1:15 AM ESTNext stop: SPEC CPU2006 Int Rate
There is no denying that SPEC CPU2006 was never one of our favorite benchmarks in the Professional IT section of AnandTech. Although it is the standard benchmark of most CPU designers and academic researchers, it is far from a real world benchmark for most professional IT users.
For starters, a typical SPEC CPU2006 benchmark consists of running as many SPEC CPU2006 instances as there are cores available in the machine. The SPEC CPU2006 instances run completely independently from each other, so there are much fewer locks or other synchronization mechanisms at work: the benchmark scales almost perfectly as long as there is enough bandwidth available. Unfortunately, that is not how the majority of business software behaves: databases have high locking overhead and most applications need some synchronization.
Secondly, most of the subtests are related to gaming and simulations (HPC). Typically these applications are much more processing intensive and achieve a higher IPC than your average business application.
Lastly, the source code of the SPEC CPU2006 tests is compiled with extremely aggressively tuned compiler settings and compilers that are less used in the rest of the IT world. Few SPEC CPU2006 results are compiled with gcc and Microsoft's Visual Studio, for example.
However, it would be a step too far to call SPEC CPU2006 useless. From a high level perspective, the scores of SPEC CPU2006 show a strong correlation with L2/L3 cache misses, cache latency, and to a lesser degree branch prediction, just like many business applications. Given similar platforms (like Intel Nehalem and AMD's Shanghai), the CPU SPEC2006 Int score gives a vague idea of which CPU has the most raw integer crunching power, although it overemphasizes memory bandwidth and core count.
To understand the weaknesses and strengths of a certain CPU architecture, even in server workloads, there is no better test than SPEC CPU2006. The first reason is that it has been profiled by so many different people from academia to engineers. If we zoom in on the subtests we can derive a lot of information as we know exactly how these applications behave: there have been lots of performance characterization papers going into great detail.
The second reason is that SPEC CPU2006 tests are compiled with the most optimal compilers and compiler options available at a certain point in time. This gives us some insight into the "real" (e.g. future) potential of a processor. We can exclude the possibility that a processor performs badly because some legacy piece of code is detrimental to the performance. If the CPU cannot score well with these kinds of binaries, it never will!
Auto-parallelization made the normal single-threaded SPEC CPU benchmarks very hard to read. We turn to the rate version instead. Since it scales almost perfectly, it is relatively easy to deduce single-threaded performance from the SPEC rate numbers--on the condition that cache interference and bandwidth bottlenecks do not blur the picture too much, so we have to be careful with those benchmarks that miss the L2 cache a lot. The current CPU2006 int scores are as follows:
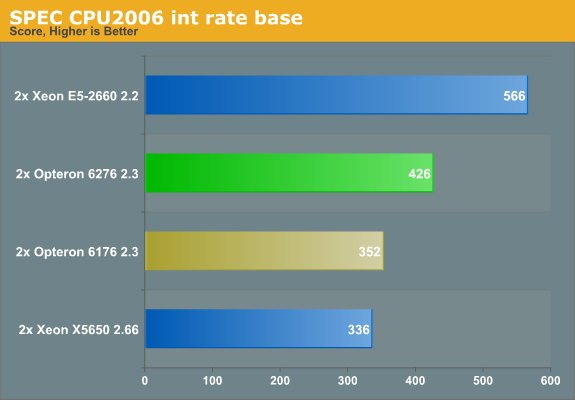
The Xeon E5 is the most efficient clock for clock, core for core. But let us compare the Opteron 6276 (2.3GHz, 16-core Bulldozer) and the Opteron 6176 (2.3GHz, 12-core Magny-Cours) in the subtests.
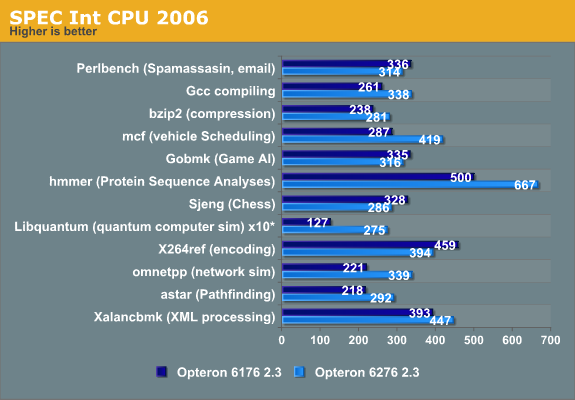
You can immediately derive from these numbers that the "Bulldozer" architecture has a very different architecture profile than Magny-Cours (which was based on the improved Barcelona architecture, Istanbul). Libquantum, omnetpp and mcf show larger performance boosts than you might expect from the 33% higher corecount. These benchmarks show that in some scenarios, Bulldozer can even increase the IPC compared to its predecessor.
We also notice that Bulldozer has some serious weaknesses compared to its predecessor, as performance decreases in the Perlbench, the game AI (gobmk), the chess (Sjeng), and the x264 encoding subtests. And although it is not uncommon that a new architecture fails to beat the previous architecture in every benchmark, it is not a good sign that even a 33% core count cannot overcome the IPC decrease in a very good scaling benchmark. If we try to understand what makes these subtests different from the others, we can get an idea of what kind of software makes Bulldozer choke. This in turn can help us to understand if relatively small tweaks can help future Opterons.








84 Comments
View All Comments
thunderising - Wednesday, May 30, 2012 - link
Glad AMD has "Greater Performance" planned sometime in the future. Wow!themossie - Wednesday, May 30, 2012 - link
"There are also other factors at play, though, as it's already known that StarCraft II doesn't use more than two cores; theinstead, it's likely the..."(feel free to remove comment after fixing this)
Nightraptor - Wednesday, May 30, 2012 - link
I am wondering if it would be possible to compare the processor performance of the Trinity A10 with a underclocked FX-4100 set to the same frequencies (I don't know if it is possible to disable the L3 cache on the FX-4100). This might give us a rough idea of how much the improvements of Piledriver have bought us. Just doing rough math in my head it would seem that they have to be pretty significant given how a FX-4100 compared to the Phenom II X4's (it lost alot, if not most of the time t of the time). The new A10 Trinity's on the other hand seem to win most of the time compared to the old architecture. Given that the A10 is a Piledriver based FX-4XXX series equivalent minus the L3 cache it would seem that Piledriver brought very significant enhancements. Either that or the Phenom II era processors responded much more poorly to the lack of L3 than Piledriver does.coder543 - Wednesday, May 30, 2012 - link
I was hoping they would be doing the same thing, even though it would be challenging to draw real information out of comparing a desktop processor and a mobile processor.SleepyFE - Wednesday, May 30, 2012 - link
+1kyuu - Wednesday, May 30, 2012 - link
+2If you can figure out some way to do a comparison and analysis of Piledriver's performance vs. Bulldozer, I think a great many of us are interested to see that. From benchmarks, it seems like Piledriver improved a great deal over Bulldozer, but it's difficult to tell without being able to compare two similar processors.
Aone - Wednesday, May 30, 2012 - link
You can compare A10-4600M or A8-4500M versus mobile Llano or Phenom or even Turion to see tweaked BD is nothing of spectacular. For instance, in most cases A8-4500M (2.3GHz base) loses to Llano A8-3500M (1.5GHz base).Nightraptor - Wednesday, May 30, 2012 - link
Where are you getting the benchmarks from that a Trinity loses to Llano. In almost all the benchmarks I have been able to find (with the exception of a few) it seems that Trinity beats Llano, hence the original post. If the Piledriver enhancements were very minor I would've expected Trinity (a hacked quad core) to lose to Llano most of the time (a true quad core). This didn't appear to happen - at least not in the anandtech review.Aone - Wednesday, May 30, 2012 - link
"http://www.notebookcheck.net/AMD-A-Series-A8-4500M...Look at "Show comparison chart". Great info!
Nightraptor - Thursday, May 31, 2012 - link
I'm not a big fan of the reliability of that website - They tend to be pretty scant on the test circumstances and configurations. Furthermore I'm curious where they are getting the informaiton for the A8-4500 as to the best of my knowledge the only Trinity in the wild at the moment is the A10 which AMD sent out in a custom made review laptop. All they list is a "K75D Sample".