AMD Discloses Bobcat & Bulldozer Architectures at Hot Chips 2010
by Anand Lal Shimpi on August 24, 2010 1:33 AM ESTA Real Redesign
When we first met Phenom we were disappointed that it didn’t introduce the major architectural changes AMD needed to keep up with Intel. The front end and execution hardware remained largely unchanged from the K8, and as a result Intel pulled ahead significantly in performance per clock over the past few years. With Bulldozer, we finally got the redesign that we’ve been asking for.
If we look at Westmere, Intel has a 4-issue architecture that’s shared among two threads. At the front end, a single Bulldozer module is essentially the same. The fetch logic in Bulldozer can grab instructions from two threads and send it to the decoder. Note that either thread can occupy the full width of the front end if necessary.
The instruction fetcher pulls from a 64KB 2-way instruction cache, unchanged from the Phenom II.
The decoder is now 4-wide an increase from the 3-wide front end that AMD has had since the K7 all the way up to Phenom II. AMD can now fuse x86 branch instructions, similar to Intel’s macro-ops fusion to increase the effective width of the machine as well. At a high level, AMD’s front end has finally caught up to Intel, but here’s where AMD moves into the passing lane.
The 4-wide decode engine feeds three independent schedulers: two for the integer cores and one for the shared floating point hardware.
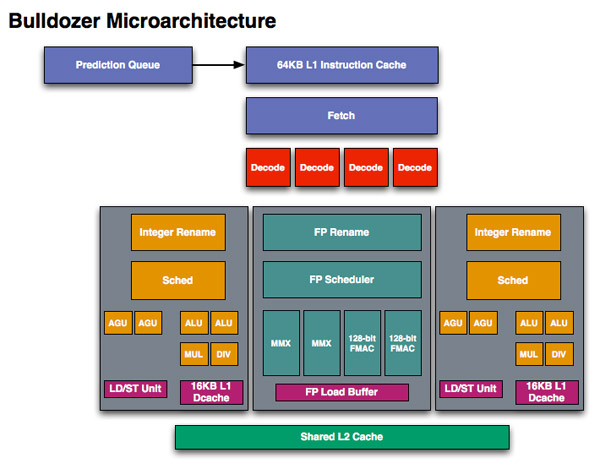
Bullddozer, 2 threads per module
Each integer scheduler is now unified. In the Phenom II and previous architectures AMD had individual schedulers for math and address operations, but with Bulldozer it’s all treated as one.
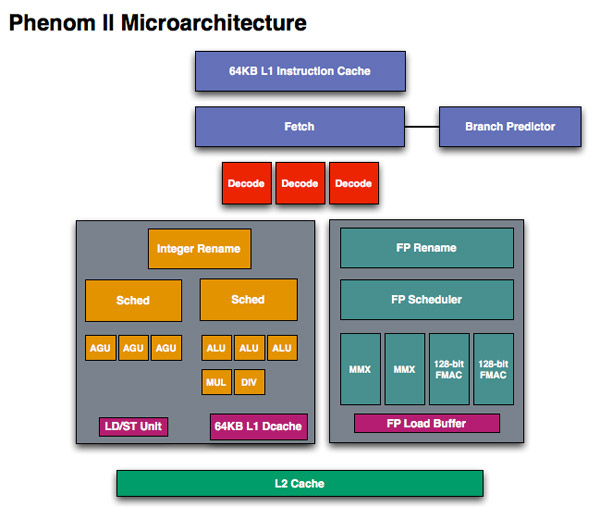
Phenom II, 1 thread per core
Each scheduler has four ports that feed a pair of ALUs and a pair of AGUs. This is down one ALU/AGU from Phenom II (it had 3 ALUs and 3 AGUs respectively and could do any mix of 3). AMD insists that the 3rd address generation unit wasn’t necessary in Phenom II and was only kept around for symmetry with the ALUs and to avoid redesigning that part of the chip - the integer execution core is something AMD has kept around since the K8. The 3rd ALU does have some performance benefits, and AMD canned it to reduce die size, but AMD mentioned that the 4-wide front end, fusion and other enhancements more than make up for this reduction. In other words, while there’s fewer single thread integer execution resources in Bulldozer than Phenom II, single threaded integer performance should still be higher.
Each integer core has its own 16KB L1 data cache. The L1 caches are segmented by thread so the shared FP core chooses which L1 cache to pull from depending on what thread it’s working on.
I asked AMD if the small L1 data cache was going to be a problem for performance, but it mentioned that in modern out of order machines it’s quite easy to hide the latency to L2 and thus this isn’t as big of an issue as you’d think. Given how aggressive AMD has been in the past with ramping up L1 cache sizes, this is a definite change of pace which further indicates how significant of a departure Bulldozer is from the norm at AMD.

While there are two integer schedulers in a single Bulldozer module (one for each thread), there’s only one FP scheduler. There’s some hardware duplication at the FP scheduler to allow two threads to share the execution resources behind it. While each integer core behaves like an independent core, the FP resources work as they would in a SMT (Hyper Threading) system.
The FP scheduler has four ports to its FPUs. There are two 128-bit FMAC pipes and two 128-bit packed integer pipes. Like Sandy Bridge, AMD’s Bulldozer will support SSE all the way up to 4.2 as well as Intel’s new AVX instructions. The 256-bit AVX ops will be handled by the two 128-bit FMAC units in each Bulldozer module.
Each Bulldozer module has its own private L2 cache shared by both integer cores and the FP execution hardware.








76 Comments
View All Comments
SuperiorSpecimen - Tuesday, August 24, 2010 - link
Let's see some competition outside of the price game!mrmojo1 - Tuesday, August 24, 2010 - link
Awesome article, can't wait to see their release :) Should be very interesting!crawmm - Tuesday, August 24, 2010 - link
I drooled on my laptop reading this. Thank you, Anand. Good overview. And fun reading after a day of tedious (and mindless) work.lothar98 - Tuesday, August 24, 2010 - link
"In many ways the architecture looks to be on-par with what Intel has done with Nehalem/Westmere."I truly hope that this does not end up to be how things roll out. It has been far too long since we have seen good competition throughout the range of consumer CPU lineup. Currently we have options and competition in the mid-low end giving us exceptional bang for our buck. While one would never say you can get the best bang for your buck in the mid or high end everyone can still appreciate having options as well as getting value.
Freddo - Tuesday, August 24, 2010 - link
Bobcat seems very interesting to me, I hope it won't take long until we see a good netbook with it, with good build quality (metal, no plastic toy), a HDMI port and 2GB RAM.Mike1111 - Tuesday, August 24, 2010 - link
I'm wondering: what about AMD powered notebooks? And I don't mean netbooks or CULV notebooks. Looks like bulldozer won't come to notebooks until 2012, which would mean that AMD would most likely have to compete with Intel's 22nm Sandy Bridge successor, Ivy Bridge.Penti - Tuesday, August 24, 2010 - link
Llano APU, it's briefly mentioned. It's where we're at. Basically K10-based 4-core with integrated DX11 GPU. Better then today but not much of a competition.mino - Tuesday, August 24, 2010 - link
The GPU in the is supposed to be at least 5x the speed of current IGP performance.Basically you get a "discrete" GPU for a price of IGP ...
MonkeyPaw - Tuesday, August 24, 2010 - link
I can see Bobcat scaling upward in notebooks. It's multi-core capable, and is a fully-functional CPU. A quad core Bobcat with better-than-Intel graphics should be a very fulfilling product for notebooks in the mid-range, while providing good battery life (thank you, power gating). Anything above that could be handled by low-voltage Bulldozers as a premium offering. To me, that seems like a better solution than Intel's, where the Atom to Core increase is so severe.Kiijibari - Tuesday, August 24, 2010 - link
Ehh guys ...MMX is depracated in 64bit mode together with x87 and 3Dnow!:
--------
The x87, MMX, and 3DNow! instruction sets are deprecated in 64-bit modes. The instructions sets are still present for backward compatibility for 32-bit mode; however, to avoid compatibility issues in the future, their use in current and future projects is discouraged.
--------
http://msdn.microsoft.com/en-us/library/ee418798%2...
Why on Earth should AMD build in 2 special MMX pipes in a brand new µarchitecture ?
AMD just announced that they got rid of 3Dnow!, MMX pipes make no sense at all.
You probably mean XOP, dont you ?