Streaming SIMD Extensions
Perhaps the most touted improvement the Pentium III has over it's older brother the Pentium II is the addition of Streaming SIMD Extensions, or SSE for short. As described in Anandtech's Pentium III review, SIMD is:
SIMD, or Single Instruction Multiple Data (in this case
SIMD-FP as it applies to FPU instructions, whereas MMX offered SIMD-Int for Integer
instructions) allows a single command (or instruction) to be applied to multiple sets of
data
simultaneously. The key to understanding the benefits of SIMD-FP instructions is the
emphasis on the simultaneous execution of commonly used instructions such as
multiplies, divides, and adds.
Specifically applied to SSE, SIMD is the ability perform a single instruction on four pairs of 32bit floating point values in one clock cycle. Clearly, SIMD offers a vast improvement in performance; however, AMD has used 3DNow (a SIMD instruction set) for many months. What is it that sets SSE and 3DNow apart, if anything?
SSE in Action
Here is an example of SSE being used in a real world situation, transforming a 3D vertex.
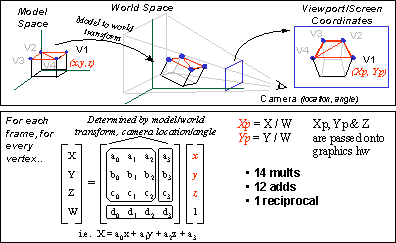
copyright (c) 1999 Intel
Let R1 = 128bit register 1, R2 = 128bit register 2, etc. All other values are 32bit floating point.
Take X = a0*x + a1*y + a2*z + a3*1
Using SIMD principles, a0 a1 a2 a3 is packed into R1, x y z 1 packed into R2, and then SIMD_Multiply ( R1, R2) is called and the result stored in R3.
Then R3 is unpacked and the 32bit components are added. Notice that the SIMD principles saved us 3 multiplications; we performed 4 multiplications in one shot using SIMD_multiply. The same process is continued for calculating values for Y, Z, and W.
New Registers vs Recycled Registers
One of the most notable differences between SSE and 3DNow is the addition of 8 new 128bit "vector" registers. Unlike 3DNow's SIMD implementation which uses the 8 existing FP/MMX 64bit registers, SSE will have its own dedicated set of registers in order to minimize mode switching and maximize parallelism between FP, MMX, and SIMD instructions. Applications which make extensive use MMX and SIMD will benefit from the new registers.
Max Throughput vs Theoretical Throughput
Since SIMD works by packing as many 32bit FP values as possible (in the case of 3DNow, 2, SSE, 4) into the operand registers (or memory) and then performing the operating on these registers, it is evident that 3DNow can only perform two normal floating point operations per operation. SSE, on the other hand can perform four floating point operations per operation. The reason I say per operation rather than per clock is because the current 3DNow implementations found in AMDs processors can perform 2 SIMD operations per clock. This means that the peak throughput of both SSE and 3DNow is four floating point operations per clock. The problem with the 3DNow implementation is that the two SIMD operations which are to be executed simultaneously cannot be both additions, or both multiplies. After skimming the Intel CPU documentation (800+ page acrobat file, cut me some slack :) it doesn't look as if SSE has any pairing restrictions (i.e which two instructions must go together for optimal performance). This makes sense because the SSE unit does not handle two SIMD instructions per clock anyway. Quality optimization, both hand and machine (compiler), should virtually alleviate the pairing restrictions in the 3DNow implementation.








0 Comments
View All Comments