Original Link: https://www.anandtech.com/show/2542
The Nehalem Preview: Intel Does It Again
by Anand Lal Shimpi on June 5, 2008 12:05 AM EST- Posted in
- CPUs
Two years ago in Taiwan at Computex 2006 Gary Key and I stayed up all night benchmarking the Core 2 Extreme X6800, the first Core micro-architecture (Conroe core) CPU we had laid our hands on. While Intel retroactively applied its tick-tock model to previous CPU generations, it was the Core micro-architecture and the Core 2 Duo in particular that kicked it all off.
At the end of last year we saw the first update to Core, the first post-Conroe "tick" if you will: Penryn. Penryn proved to be a nice upgrade to Conroe, reducing power consumption even further and giving a slight boost to performance. What Penryn didn't do however was shake the world the way Conroe did upon its launch in 2006.
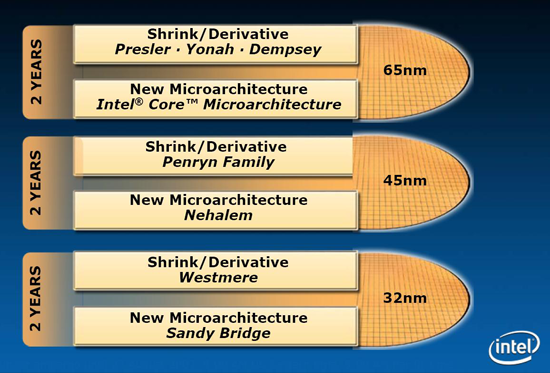
After every tick however, comes a tock. While Penryn was a die shrink of an existing architecture, Nehalem is a brand new architecture built on the same 45nm process as Penryn. It's sort of a big deal, being the first tock after the incredibly successful Core 2 launch.

731M transistors, four cores, eight threads
It's like clockwork with Intel; around six months before the release of a new processor, it's sent over to Intel's partners so they may begin developing motherboards for the chip. It was true with Northwood, Prescott, Conroe, Penryn and now Nehalem. And plus, did you really expect, on the eve of the two year anniversary of our first Core 2 preview, a trip to Taiwan for Computex without benchmarks of Nehalem? In the words of Balki Bartokomous, don't be ridiculous :)

Yep, that's what you think it is
Without Intel's approval, supervision, blessing or even desire - we went ahead and snagged us a Nehalem (actually, two) and spent some time with them.
(Sorry guys, stop making interesting chips and we'll stop trying to get an early look at them :)...)
Not One Nehalem, but Two
Nehalem itself is very stable but it has only been in Taiwanese motherboard manufacturer hands for a relatively short while now, so the only truly mature motherboards are made by Intel. Unfortunately since Intel didn't sanction our little Nehalem excursion, we were left with little more than access to some early X58 based motherboards in Taiwan. Thankfully we had two setups to play with, each for a very limited time.
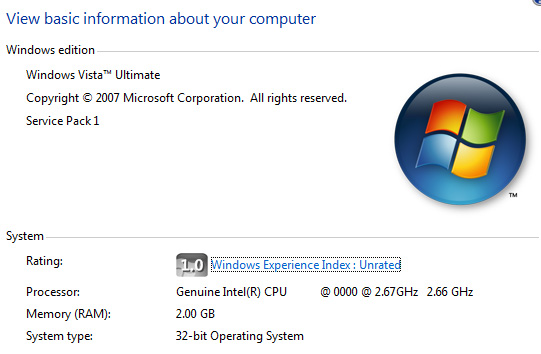
We had access to a 2.66GHz Nehalem for the longest time, unfortunately the motherboard it was paired with had some serious issues with memory performance. Not only was there no difference between single and triple channel memory configurations, memory latency was high. We know this was a board specific issue since our second Nehalem platform didn't exhibit any issues. Unfortunately we didn't have access to the more mature platform for very long at all, meaning the majority of our tests had to be run on the first setup (never fear, Nehalem is fast enough that it didn't end up mattering).
The second issue we ran into was a PCI Express problem that kept us from running any meaningful GPU benchmarks. We've been told that it'll take the motherboard guys about a month to work out these kinks, but that's why you shouldn't expect to see a full performance evaluation of Nehalem in the near term.
The CPUs are quite mature and are running extremely cool (surprisingly cool actually), their clock speeds are being artificially limited by Intel in order to avoid putting all cards on the table at this time. We saw a similar approach with the very first Penryn samples which were all locked at 2.66GHz. The Intel X58 chipset we used in our testing on the other hand got quite hot.
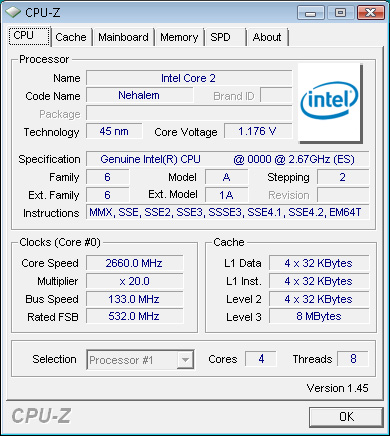
Nehalem no longer has a conventional FSB, its clock speed is derived from a multiplier of an external clock frequency - in this case 133MHz. Expect all Nehalem chips to come out in frequencies that are multiples of 133MHz.
Thankfully we don't want a thorough look at Nehalem today, we'll save that for the launch - what we do want is to whet our appetite. We want to know if Intel can pull it off a second time.
The Socket
With an integrated memory controller, Intel needed a new pinout for Nehalem and the first version with three 64-bit DDR3 memory channels features a 1366-pin LGA interface:

LGA-1366 (left) vs. LGA-775 (right)
The socket is noticeably bigger than LGA-775 as is the mounting area for heatsinks. You can't reuse LGA-775 heatsinks and instead must use a heatsink with mounting holes more spread apart. As far as we can tell, the same push-pin mounting mechanism from LGA-775 is present in Nehalem which is disappointing.
With a larger socket and more pins, the CPU itself is obviously bigger. Here's a shot of our Nehalem compared to a Core 2 Duo E8500:

Nehalem (left) vs. Penryn (right)

Nehalem (left) vs. Penryn (right)
Intel will obviously have dual-channel versions of Nehalem in the future, unfortunately it looks like they will use a smaller socket for mainstream versions of the chip (LGA-1160?). We won't have to deal with socket segmentation just yet and it is always possible that Intel will choose to stand behind a single socket for the majority of the desktop market, reserving LGA-1366 for a Skulltrail-like high end but the strategy is unclear at this point.
The Return of Hyper Threading
While Nehalem is designed to scale to up to 8 cores per chip, each one of those cores has the hardware necessary to execute two threads simultaneously - yep, it's the return of Hyper Threading. Thus our quad-core Nehalem sample appeared as 8 logical cores under Windows Vista:
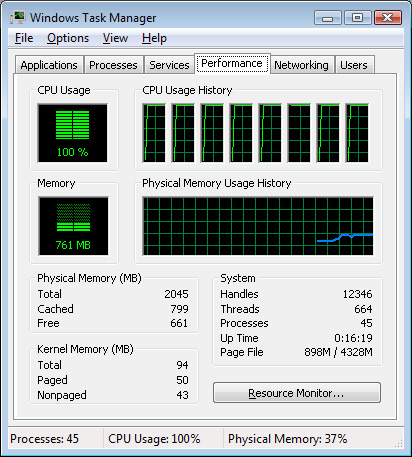
Four cores, eight threads, all in a desktop CPU
Note that as in previous implementations of Hyper Threading (or other SMT processors) this isn't a doubling of execution resources, it's simply allowing two instruction threads to make their way down the pipeline at the same time to make better use of idle execution units. Having 8 physical cores will obviously be faster, but 8 logical (4 physical) is a highly power efficient way of increasing performance.
We took Valve's source-engine map compilation benchmark and measured the compile time to execute one instance (4 threads) vs. two instances of the benchmark. The graph below shows the increase in compilation time when we double the workload:
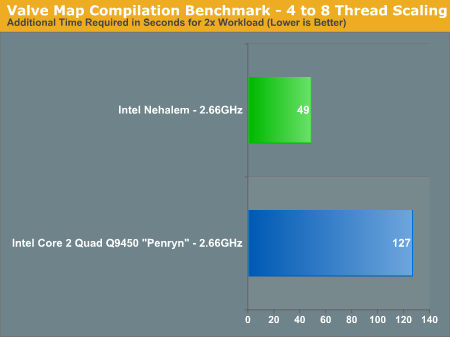
While the 2.66GHz Core 2 Quad Q9450 (Penryn) takes another 127 seconds to execute twice the workload, the 2.66GHz Nehalem only needs another 49 seconds. And if you're curious, this quad-core Nehalem running at 2.66GHz is within 20% of the performance of an eight-core 3.2GHz Skulltrail system. Equalize clock speed and we'd bet that a quad-core Nehalem would be the same speed as an 8-core Skulltrail here. The raw performance numbers are below:
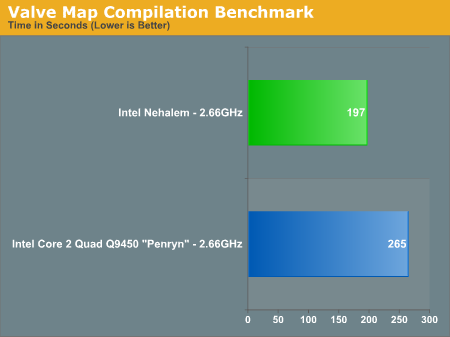
We couldn't disable Hyper Threading so we reached the limits of what we were able to investigate here.
A Quick Path to Memory
Our investigation begins with the most visibly changed part of Nehalem's architecture: the memory subsystem. Nehalem implements a very Phenom-like memory hierarchy consisting of small, fast individual L1 and L2 caches for each of its four cores and then a single, larger shared L3 cache feeding the entire chip.

Nehalem's L1 cache, despite being seemingly unchanged from Penryn, does grow in latency; it now takes 4 cycles to access vs. 3. The L2 cache is now only 256KB per core instead of being 24x the size in Penryn and thus can be accessed in only 11 cycles down from 15 (Penryn added an additional clock cycle over Conroe to access L2).
| CPU / CPU-Z Latency | L1 Cache | L2 Cache | L3 Cache |
| Nehalem (2.66GHz) | 4 cycles | 11 cycles | 39 cycles |
| Core 2 Quad Q9450 - Penryn - (2.66GHz) | 3 cycles | 15 cycles | N/A |
The L3 cache is quite possibly the most impressive, requiring only 39 cycles to access at 2.66GHz. The L3 cache is a very large 8MB cache, 4x the size of Phenom's L3, yet it can be accessed much faster. In our testing we found that Phenom's L3 cache takes a similar 43 cycles to access but at much lower clock speeds (2.0GHz). If we put these numbers into relative terms it takes 21.5 ns to get a request back from Phenom's L3 vs. 14.6 ns with Nehalem's - that's nearly 50% longer in Phenom.
While Intel did a lot of tinkering with Nehalem's caches, the inclusion of a multi-channel on-die DDR3 memory controller was the most apparent change. AMD has been using an integrated memory controller (IMC) since 2003 on its K8 based microprocessors and for years Intel has resisted doing the same, citing complexities in choosing what memory to support among other reasons for why it didn't follow in AMD's footsteps.
With clock speeds increasing and up to 8 cores (including GPUs) making their way into Nehalem based CPUs in the coming year, the time to narrow the memory gap is upon us. You can already tell that Nehalem was designed to mask the distance between the individual CPU cores and main memory with its cache design, and the IMC is a further extension of the philosophy.
The motherboard implementation of our 2.66GHz system needed some work so our memory bandwidth/latency numbers on it were way off (slower than Core 2), luckily we had another platform at our disposal running at 2.93GHz which was working perfectly. We turned to Everest Ultimate 4.50 to give us memory bandwidth and latency numbers from Nehalem.
Note that these figures are from a completely untuned motherboard and are using DDR3-1066 (dual-channel on the Core 2 system and triple-channel on the Nehalem system):
| CPU / Everest Ultimate 4.50 | Memory Read | Memory Write | Memory Copy | Memory Latency |
| Nehalem (2.93GHz) | 13.1 GB/s | 12.7 GB/s | 12.0 GB/s | 46.9 ns |
| Core 2 Extreme QX9650 - Penryn - (3.00GHz) | 7.6 GB/s | 7.1 GB/s | 6.9 GB/s | 66.7 ns |
Memory accesses on Conroe/Penryn were quick due to Intel's very aggressive prefetchers, memory accesses on Nehalem are just plain fast. Nehalem takes a little over 2/3 the time to complete a memory request as Penryn, and although we didn't have time to run comparable Phenom numbers I believe Nehalem's DDR3 memory controller is faster than Phenom's DDR2 controller.
Memory bandwidth is obviously greater with three DDR3 channels, Everest measured around a 70% increase in read bandwidth. While we don't have the memory bandwidth figures here, Gary measured a 10% difference in WinRAR performance (a test that's highly influenced by memory bandwidth and latency) between single-channel and triple-channel Nehalem configurations.
While we didn't really expect Intel to somehow do wrong with Nehalem's memory architecture, it's important to point out that it is very well implemented. Intel managed to change the cache structure and introduce an integrated memory controller while making both significantly faster than what AMD managed despite a four-year headstart.
In short: Nehalem can get data out of memory quick like bunnies.
Nehalem's Media Encoding Performance
We had time to run two of our media encoding tests: the DivX 6.8 and x264 workloads.
DivX 6.8 with Xmpeg
Our DivX test is the same one we've run in our regular CPU reviews, we're simply encoding a 1080p MPEG-2 file in DivX. We are using an unconstrained profile, encoding preset of 5 and enhanced multithreading is enabled.
The DivX test is an important one as it doesn't scale well at all beyond four threads, any performance advantage Nehalem has here is entirely due to microarchitectural improvements and not influenced by its ability to work on twice as many threads at once.
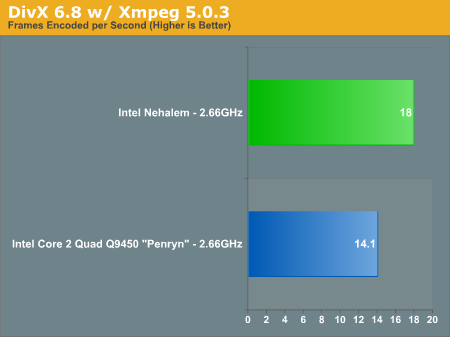
Clock for clock, Nehalem is nearly 28% faster than Penryn in our DivX test. Even better is when you put this performance in perspective: at 2.66GHz Nehalem is faster than the fastest Penryn available today the Core 2 Extreme QX9770 running at 3.2GHz. At 3.2GHz, Nehalem will be fast. The improvements in performance here are entirely due to the faster L2 cache and micro-architectural gains; being able to have more micro-ops in flight and improved unaligned cache accesses give us a significant improvement in video encoding performance.
The last time we saw these sorts of performance gains was when Conroe first launched.
x264 Encoding with AutoMKV
Using AutoMKV we compress the same source file we used in our WME test down to 100MB, but with the x264 codec. We used the 2_Pass_Insane_Quality profile:
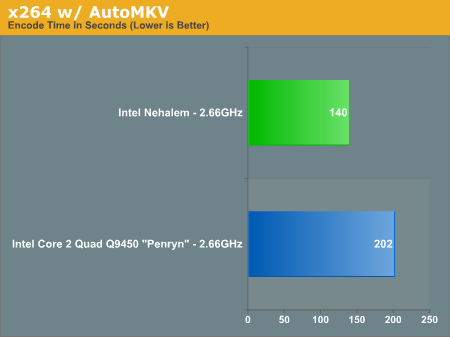
Encoding performance here went through the roof with Nehalem: a clock for clock boost of 44%. Once more, Nehalem at today's artificially limited, modest clock speed is already faster than any Penryn out today. What Intel did to AMD in 2006, it is doing to itself in 2008. Amazing.
Faster Unaligned Cache Accesses & 3D Rendering Performance
3dsmax r9
Our benchmark, as always, is the SPECapc 3dsmax 8 test but for the purpose of this article we only run the CPU rendering tests and not the GPU tests.
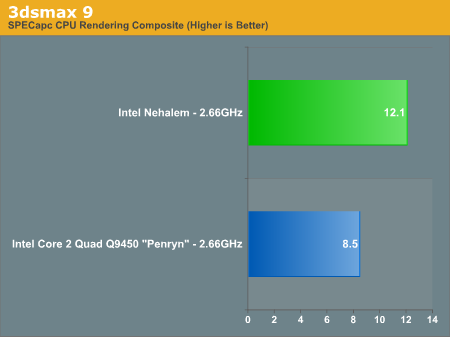
The results are reported as render times in seconds and the final CPU composite score is a weighted geometric mean of all of the test scores.
| CPU / 3dsmax Score Breakdown | Radiosity | Throne Shadowmap | CBALLS2 | SinglePipe2 | Underwater | SpaceFlyby | UnderwaterEscape |
| Nehalem (2.66GHz) | 12.891s | 11.193s | 5.729s | 20.771s | 24.112s | 30.66s | 27.357s |
| Penryn (2.66GHz) | 19.652s | 14.186s | 13.547s | 30.249s | 32.451s | 33.511s | 31.883s |
The CBALLS2 workload is where we see the biggest speedup with Nehalem, performance more than doubles. It turns out that CBALLS2 calls a function in the Microsoft C Runtime Library (msvcrt.dll) that can magnify the Core architecture's performance penalty when accessing data that is not aligned with cache line boundaries. Through some circuit tricks, Nehalem now has significantly lower latency unaligned cache accesses and thus we see a huge improvement in the CBALLS2 score here. The CBALLS2 workload is the only one within our SPECapc 3dsmax test that really stresses the unaligned cache access penalty of the current Core architecture, but there's a pretty strong performance improvement across the board in 3dsmax.
Nehalem is just over 40% faster than Penryn, clock for clock, in 3dsmax.
Cinebench R10
A benchmarking favorite, Cinebench R10 is designed to give us an indication of performance in the Cinema 4D rendering application.
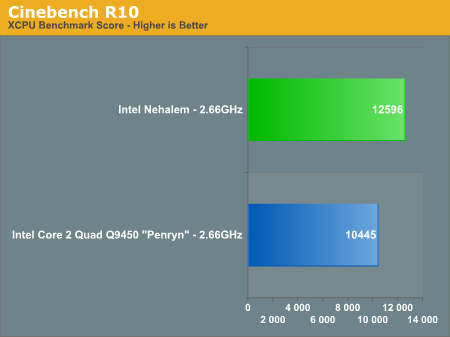
Cinebench also shows healthy gains with Nehalem, performance went up 20% clock for clock over Penryn.
We also ran the single-threaded Cinebench test to see how performance improved on an individual core basis vs. Penryn (Updated: The original single-threaded Penryn Cinebench numbers were incorrect, we've included the correct ones):
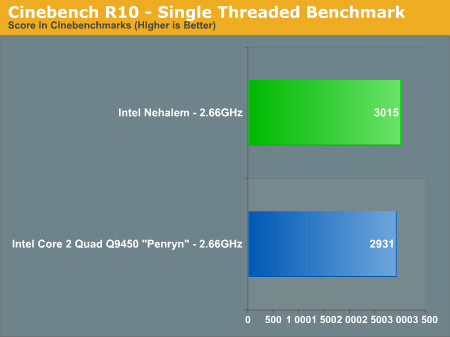
Cinebench shows us only a 2% increase in core-to-core performance from Penryn to Nehalem at the same clock speed. For applications that don't go out to main memory much and can stay confined to a single core, Nehalem behaves very much like Penryn. Remember that outside of the memory architecture and HT tweaks to the core, Nehalem's list of improvements are very specific (e.g. faster unaligned cache accesses).
The single thread to multiple thread scaling of Penryn vs. Nehalem is also interesting:
| Cinebench R10 | 1 Thread | N-Threads | Speedup |
| Nehalem (2.66GHz) | 3015 | 12596 | 4.18x |
| Core 2 Quad Q9450 - Penryn - (2.66GHz) | 2931 | 10445 | 3.56x |
The speedup confirms what you'd expect in such a well threaded FP test like Cinebench, Nehalem manages to scale better thanks to Hyper Threading. If Nehalem had the same 3.56x scaling factor that we saw with Penryn it would score a 10733, virtually inline with Penryn. It's Hyper Threading that puts Nehalem over the edge and accounts for the rest of the gain here.
While many 3D rendering and video encoding tests can take at least some advantage of more threads, what about applications that don't? One aspect of Nehalem's performance we're really not stressing much here is its IMC performance since most of these benchmarks ended up being more compute intensive. Where HT doesn't give it the edge, we can expect some pretty reasonable gains from Nehalem's IMC alone. The Nehalem we tested here is crippled in that respect thanks to a premature motherboard, but gains on the order of 20% in single or lightly threaded applications is a good expectation to have.
POV-Ray 3.7 Beta 24
POV-Ray is a popular raytracer, also available with a built in benchmark. We used the 3.7 beta which has SMP support and ran the built in multithreaded benchmark.
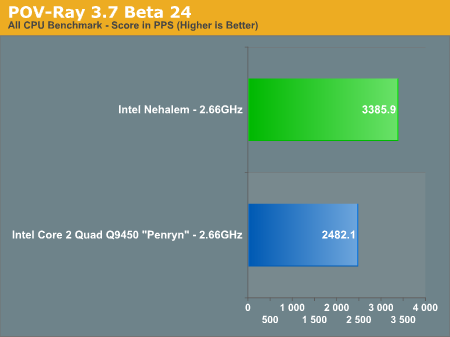
Finally POV-Ray echoes what we've seen elsewhere, with a 36% performance improvement over the 2.66GHz Core 2 Q9450. Note that Nehalem continues to be faster than even the fastest Penryns available today, despite the lower clock speed of this early sample.
Power Consumption
Built on the same 45nm process as Penryn, we expect Nehalem to have higher power consumption than Penryn but given Intel's target of a 1% increase in performance for no more than a 1% increase in power consumption per microarchitectural change - the results should be reasonable:
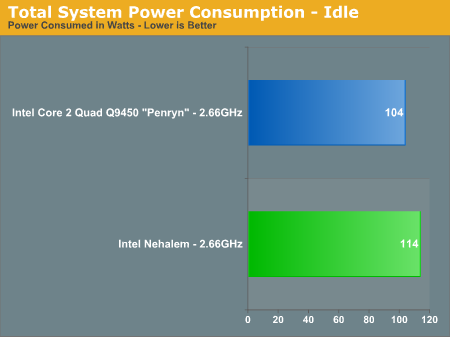
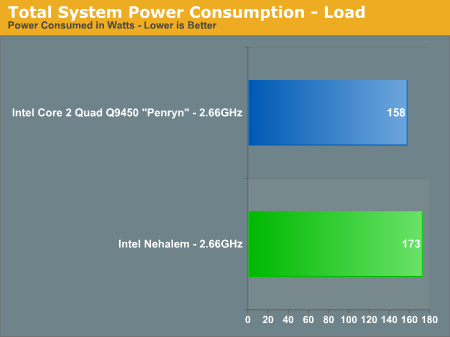
And reasonable they are; for a 20 - 50% increase in performance, total system power consumption only went up by 10%.
Final Words
First keep in mind that these performance numbers are early, and they were run on a partly crippled, very early platform. With that preface, the fact that Nehalem is still able to post these 20 - 50% performance gains says only one thing about Intel's tick-tock cadence: they did it.
We've been told to expect a 20 - 30% overall advantage over Penryn and it looks like Intel is on track to delivering just that in Q4. At 2.66GHz, Nehalem is already faster than the fastest 3.2GHz Penryns on the market today. At 3.2GHz, I'd feel comfortable calling it baby Skulltrail in all but the most heavily threaded benchmarks. This thing is fast and this is on a very early platform, keep in mind that Nehalem doesn't launch until Q4 of this year.
One valid concern is with regards to performance in applications that don't scale well beyond two or four cores, what will Nehalem offer us then? Our DivX test doesn't scale well beyond four cores and even then Nehalem's performance was in the 20 - 30% faster range that we've been expecting. The other thing to keep in mind is that none of these tests are really stressing Nehalem's integrated memory controller. When AMD made the move to an IMC, we saw an instant 20% performance boost in most applications. I suspect that the applications that don't benefit from Hyper Threading, will at least benefit from the IMC. We've only scratched the surface of Nehalem here, looking at the benefits of Hyper Threading and its lower latency unaligned cache accesses. We've hinted at what's to come with the extremely well balanced and low latency memory hierarchy of Intel's new baby. Once this thing gets closer to launch, we should be able to fill in the rest of the puzzle.
Over six years ago I had dinner with Intel's Pat Gelsinger (back when he was Intel's CTO), and I asked him the same question I always do: "what are you excited about?" Back then his response was "threading", Intel was about to launch Hyper Threading and Pat was convinced that it was absolutely necessary for the future of microprocessors.
It was at the same dinner that Pat mentioned Intel may do a chip with an integrated memory controller much like AMD, but that an IMC wouldn't solve the problem of idle execution units - only indirectly mitigate it. With Nehalem, Intel managed to combine both - and it only took 6 years to pull it off.
Pat also brought up another very good point at that dinner. He turned to me and said that you can only integrate a memory controller once, what do you do next to improve performance? Intel has managed to keep increasing performance, but what I really want to see is what happens at the next tock. Intel proved its ability with Conroe and with Nehalem it shows that the tick-tock model can work, but more than anything looking at Nehalem today makes me excited at what Sandy Bridge will bring.
The fact that we're able to see these sorts of performance improvements despite being faced with a dormant AMD says a lot. In many ways Intel is doing more to improve performance today than when AMD was on top during the Pentium 4 days.
AMD never really caught up to the performance of Conroe, through some aggressive pricing we got competition in the low end but it could never touch the upper echelon of Core 2 performance. With Penryn, Intel widened the gap. And now with Nehalem it's going to be even tougher to envision a competitive high-end AMD CPU at the end of this year. 2009 should hold a new architecture for AMD, which is the only thing that could possibly come close to achieving competition here. It's months before Nehalem's launch and there's already no equal in sight, it will take far more than Phenom to make this thing sweat.






