The Intel Broadwell Review Part 2: Overclocking, IPC and Generational Analysis
by Ian Cutress on August 3, 2015 8:00 AM ESTProfessional Performance: Windows
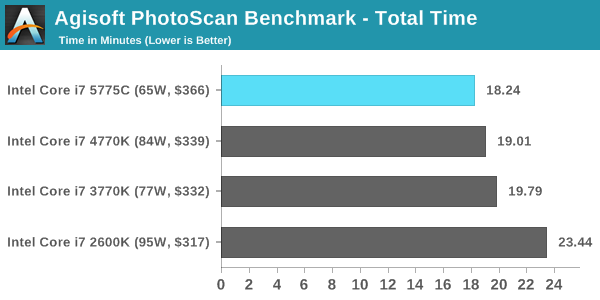
Agisoft Photoscan – 2D to 3D Image Manipulation: link
Agisoft Photoscan creates 3D models from 2D images, a process which is very computationally expensive. The algorithm is split into four distinct phases, and different phases of the model reconstruction require either fast memory, fast IPC, more cores, or even OpenCL compute devices to hand. Agisoft supplied us with a special version of the software to script the process, where we take 50 images of a stately home and convert it into a medium quality model. This benchmark typically takes around 15-20 minutes on a high end PC on the CPU alone, with GPUs reducing the time.
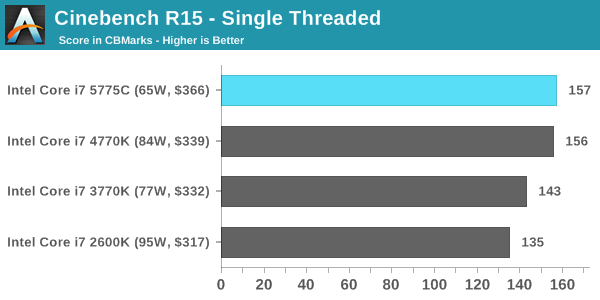
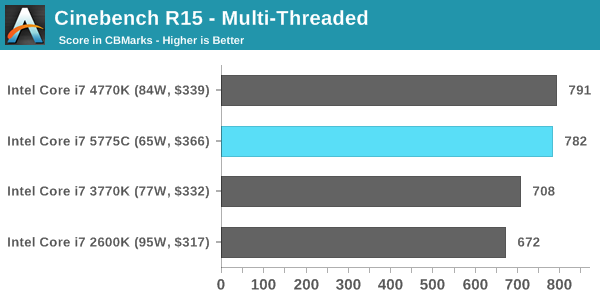
Cinebench R15
Cinebench is a benchmark based around Cinema 4D, and is fairly well known among enthusiasts for stressing the CPU for a provided workload. Results are given as a score, where higher is better.
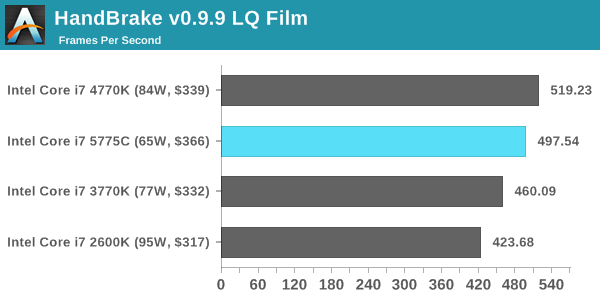
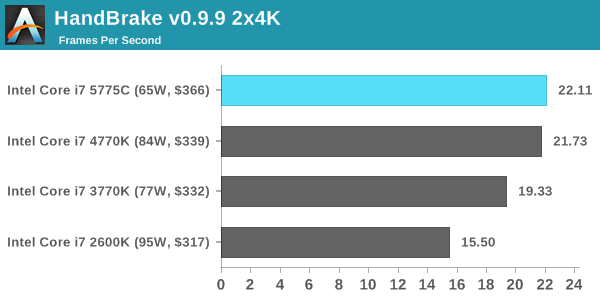
HandBrake v0.9.9: link
For HandBrake, we take two videos (a 2h20 640x266 DVD rip and a 10min double UHD 3840x4320 animation short) and convert them to x264 format in an MP4 container. Results are given in terms of the frames per second processed, and HandBrake uses as many threads as possible.
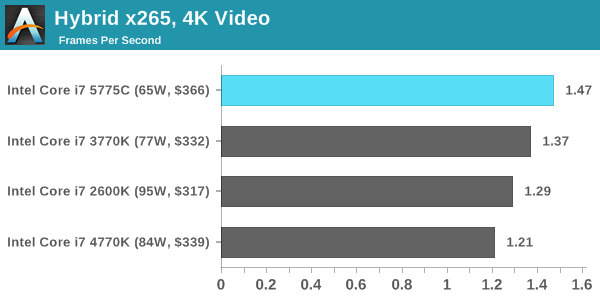
Hybrid x265
Hybrid is a new benchmark, where we take a 4K 1500 frame video and convert it into an x265 format without audio. Results are given in frames per second.








121 Comments
View All Comments
name99 - Monday, August 3, 2015 - link
Well think about WHY these results are as they are:- There is one set of benchmarks (most of the raytracing and sci stuff) that can make use of AVX. They see a nice boost from initial AVX (implemented by routing each instruction through the FPU twice) to AVX on a wider execution unit to the introduction of AVX2.
- There is a second set of benchmarks (primarily winRAR) that manipulate data which fits in the crystalwell cache but not in the 8MB L3). Again a nice win there; but that's a specialized situation. In data streaming examples (which better described most video encode/decode/filtering) that large L4 doesn't really buy you anything.
- There WOULD be a third set of benchmarks (if AnandTech tested for this) that showed a substantial improvement in indirect branch performance going from IB to Haswell. This is most obvious on interpreters and similar such code, though it also helps virtual functions in C++/Swift style code and Objective C method calls. My recollection is that you can see this jump in the GeekBench Lua benchmark. (Interestingly enough, Apple's A8 seems to use this same advanced TAGE-like indirect predictor because it gets Lua IPC scores as good as Intel).
OK, no we get to Skylake. Which of these apply?
- No AVX bump except for Xeons.
- Usually no CrystalWell
So the betting would be that the BIG jumps we saw won't be there. Unless they've added something new that they haven't mentioned yet (eg a substantially more sophisticated prefetcher, or value prediction), we won't even get the small targeted boost that we saw when Haswell's indirect predictor was added. So all we'll get is the usual 1 or 2% improvement from adding 4 or 6 more physical registers and ROB slots, maybe two more issue slots, a few more branch predictor slots, the usual sort of thing.
There ARE ideas still remaining in the academic world for big (30% or so) improvements in single-threaded IPC, but it's difficult for Intel to exploit these given how complex their CPUs are, and how long the pipeline is from starting a chip till when it ships. In the absence of competition, my guess is they continue to play it safe. Apple, I think, is more likely to experiment with these ideas because their base CPU is a whole lot easier to understand and modify, and they have more competition.
(Though I don't expect these changes in the A9. The A7 was adequate to fight off the expected A57; the A8 is adequate to fight off the expected A72; and all the A9 needs to do to maintain a one year plus lead is add the ARMv81.a ISA and the same sort of small tweaks and a two hundred or so MHz boost that we saw applied to the A8. I don't expect the big microarchitectural changes at Apple until
- they've shipped ARMv81.a ISA
- they've shipped their GPU (tightly integrated HSA style with not just VM and shared L3, but with tighter faster coupling between CPU and GPU for fast data movement, and with the OS able to interrupt and to some extent virtualize the GPU)
- they're confident enough in how wide-spread 64-bit apps are that they don't care about stripping out the 32-bit/thumb ISA support in the CPU [with what they implies for the pipeline, in particular predication and barrel shifter] and can create a microarchitecture that is purely optimized for the 64-bit ISA.
Maybe this will be the A10, IF the A9 has ARMv8.1a and an Apple GPU.)
Speedfriend - Tuesday, August 4, 2015 - link
"The A7 was adequate to fight off the expected A57;"In hindsight the A7 was not very good at all, it was the reason that Apple was unable to launch a large screen phone with decent battery life. Look at he improvements made to A8, around 10% better performance, but 50% more battery life.
Speedfriend - Tuesday, August 4, 2015 - link
"they've shipped their GPU" by the way, why do you expect them to ship their own GPU and not use IMG's. The IMG GPU have consistently been the best in the market.nunya112 - Monday, August 3, 2015 - link
by the looks of it. the 4790K seems to be the best CPU. until skylake that is. but even then I doubt there will be much improvementnunya112 - Monday, August 3, 2015 - link
unless u have the older ivy's then yeah maybe worth it ?TheinsanegamerN - Monday, August 3, 2015 - link
Nah. the older ivys can be overclocked to easily meet these chips. the IPC of broadwell is overshadowed by a 400mhz lower clock rate on typical OC. only reason to upgrade is if you NEED something on the new chipset or are running some nehalem-era chip.Teknobug - Monday, August 3, 2015 - link
Ivy's are the best overclockers.TheinsanegamerN - Monday, August 3, 2015 - link
Sandy overclocked better than ivy,Hulk - Monday, August 3, 2015 - link
Ian - Very nice job on this one! Thanks.Meaker10 - Monday, August 3, 2015 - link
A slight correction, on the image of crystal well it is the die on the left (the much larger one) which is the cache and the small one is the cpu on the right.