The Intel Broadwell Review Part 2: Overclocking, IPC and Generational Analysis
by Ian Cutress on August 3, 2015 8:00 AM ESTConclusions: Broadwell Overclocking, IPC and Generational Gain
For everyone who has been in the PC industry for a decade or more, several key moments stand out when it comes to a better processor in the market. The Core architecture made leaps and bounds over the previous Pentium 4 Prescott debacle, primarily due to a refocus on efficiency over raw frequency. The Sandy Bridge architecture also came with a significant boost, moving the Northbridge on die and simplifying design.

Since then, despite the perseverance of (or soon to be mildly delayed) Moore’s Law, performance is measured differently. Efficiency, core count, integrated SIMD graphics, heterogeneous system architecture and specific instruction sets are now used due to the ever expanding and changing paradigm of user experience. Something that is fast for both compute and graphics, and then also uses near-zero power is the holy-grail in design. But let’s snap back to reality here – software is still designed in code one line at a time. The rate at which those lines are processed, particularly in response driven scenarios, is paramount. This is why the ‘instructions per clock/cycle’ metric, IPC, is still an important aspect of modern day computing.

As the movement from Haswell to Broadwell is a reduction in the lithography node, from 22nm to 14nm, with a few silicon changes, Broadwell was a mobile first design and launched in late 2014 with notebook parts. This is typical with node reductions due to the focus on efficiency overall rather than just performance. For the desktop parts, launched over six months later, we end up with an integrated graphics focused implementation purposefully designed for all-in-one PCs and integrated systems rather than a mainstream, high end processor. The i7 and i5 are both targeted at 65W, rather than 84W/88W of the previous architecture. This gives the CPUs a much lower frequency and without a corresponding IPC change, makes the upgrade path more focused for low end Haswell owners, those who are still several generations behind wanting an upgrade or those who specifically want an integrated graphics solution.
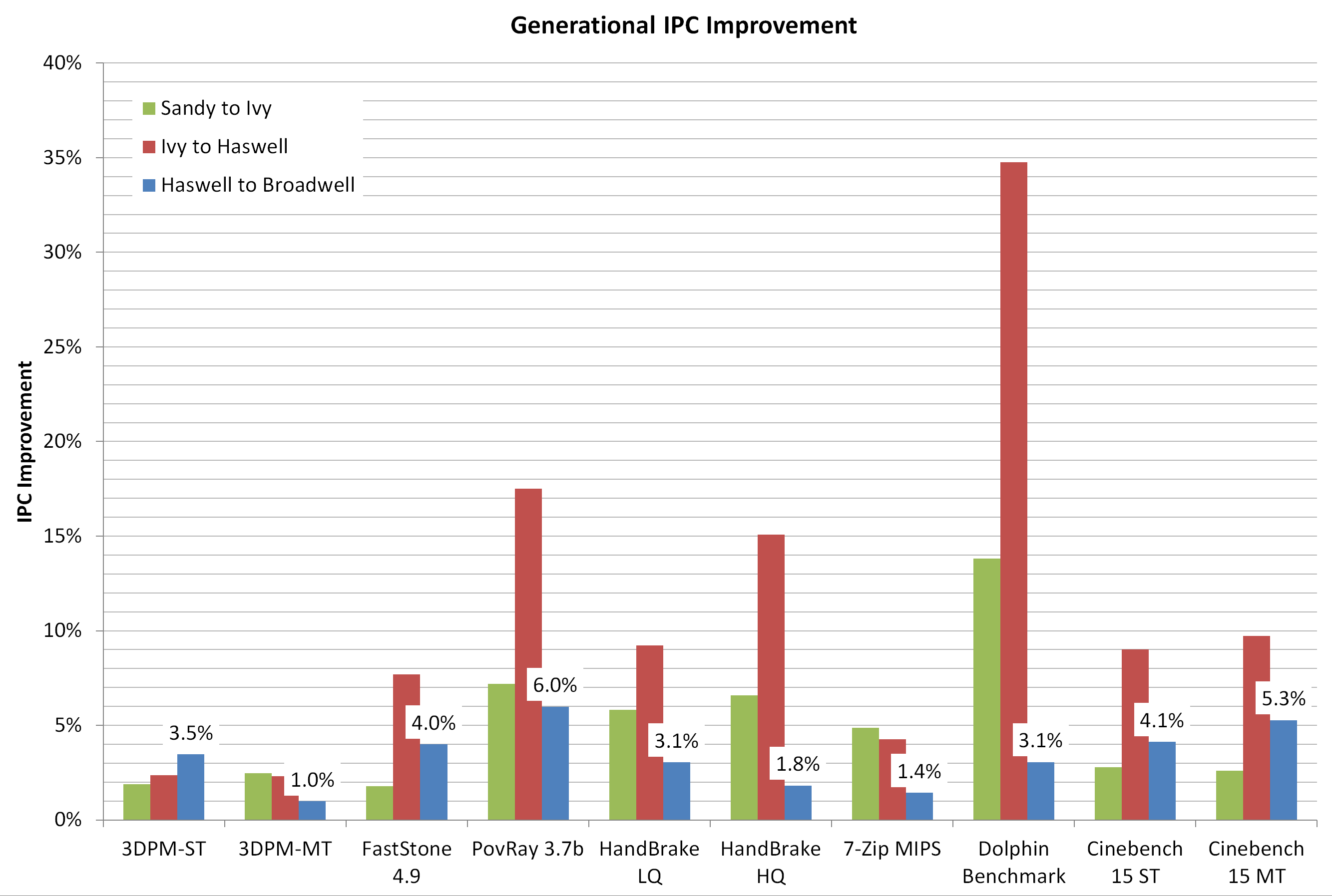
In our first look at Broadwell on the desktop, our recommendation that it would only appeal to those who need the best integrated graphics solution regardless of cost still stands. Part 2 has revealed that clock-for-clock, Broadwell gives 3.3% better performance from our tests although DRAM focused workloads (WinRAR) can benefit up to 25%, although those are few and far between. If we compare it back several generations, that small IPC gain is wiped out by processors like the i7-4790K that overpower the CPU performance in pure frequency or even the i7-4770K which still has a frequency advantage. From an overall CPU performance standpoint out of the box, the i7-5775C sits toe-to-toe with the i7-4770K with an average 1% loss. However, moving the comparison up to the i7-4790K and due to that frequency difference, the Broadwell CPU sits an average 12% behind it, except in those specific tests that can use the eDRAM.
There’s nothing much to be gained with overclocking either. Our i7-5775C CPU made 4.2 GHz, in line with Intel’s expectations for these processors. If we compare that to an overclocked 4.6 GHz i7-4790K, the 4790K is still the winner. Overclocking on these Broadwell CPUs still requires care, due to the arrangement of the CPU under the heatspreader with the added DRAM. We suggest the line method of thermal paste application rather than the large-pea method as a result.

Looking back on the generational improvements since Sandy Bridge is actually rather interesting. I remember using the i7-2600K, overclocking it to 5.0 GHz and remembering how stunned I was at the time. Step forward 4.5 years and we have a direct 21% increase in raw performance per clock, along with the added functionality benefits of faster memory and a chipset that offers a lot more functionality. If you’ve been following the technology industry lately, there is plenty of talk surrounding the upcoming launch of Skylake, an architectural update to Intel’s processor line on 14nm. I can’t wait to see how that performs in relation to the four generations tested in this article.
*When this article was initially published, inaccuracies were made in calculating the IPC gain in the timed benchmarks. The article has been updated to reflect this change. In light of the recalculation,overall conclusions are still correct.
Interesting related links:
The Intel Broadwell Desktop Review: Core i7-5775C and Core i5-5675C Tested (Part 1)
AnandTech Bench CPU Comparison Tool








121 Comments
View All Comments
name99 - Monday, August 3, 2015 - link
Well think about WHY these results are as they are:- There is one set of benchmarks (most of the raytracing and sci stuff) that can make use of AVX. They see a nice boost from initial AVX (implemented by routing each instruction through the FPU twice) to AVX on a wider execution unit to the introduction of AVX2.
- There is a second set of benchmarks (primarily winRAR) that manipulate data which fits in the crystalwell cache but not in the 8MB L3). Again a nice win there; but that's a specialized situation. In data streaming examples (which better described most video encode/decode/filtering) that large L4 doesn't really buy you anything.
- There WOULD be a third set of benchmarks (if AnandTech tested for this) that showed a substantial improvement in indirect branch performance going from IB to Haswell. This is most obvious on interpreters and similar such code, though it also helps virtual functions in C++/Swift style code and Objective C method calls. My recollection is that you can see this jump in the GeekBench Lua benchmark. (Interestingly enough, Apple's A8 seems to use this same advanced TAGE-like indirect predictor because it gets Lua IPC scores as good as Intel).
OK, no we get to Skylake. Which of these apply?
- No AVX bump except for Xeons.
- Usually no CrystalWell
So the betting would be that the BIG jumps we saw won't be there. Unless they've added something new that they haven't mentioned yet (eg a substantially more sophisticated prefetcher, or value prediction), we won't even get the small targeted boost that we saw when Haswell's indirect predictor was added. So all we'll get is the usual 1 or 2% improvement from adding 4 or 6 more physical registers and ROB slots, maybe two more issue slots, a few more branch predictor slots, the usual sort of thing.
There ARE ideas still remaining in the academic world for big (30% or so) improvements in single-threaded IPC, but it's difficult for Intel to exploit these given how complex their CPUs are, and how long the pipeline is from starting a chip till when it ships. In the absence of competition, my guess is they continue to play it safe. Apple, I think, is more likely to experiment with these ideas because their base CPU is a whole lot easier to understand and modify, and they have more competition.
(Though I don't expect these changes in the A9. The A7 was adequate to fight off the expected A57; the A8 is adequate to fight off the expected A72; and all the A9 needs to do to maintain a one year plus lead is add the ARMv81.a ISA and the same sort of small tweaks and a two hundred or so MHz boost that we saw applied to the A8. I don't expect the big microarchitectural changes at Apple until
- they've shipped ARMv81.a ISA
- they've shipped their GPU (tightly integrated HSA style with not just VM and shared L3, but with tighter faster coupling between CPU and GPU for fast data movement, and with the OS able to interrupt and to some extent virtualize the GPU)
- they're confident enough in how wide-spread 64-bit apps are that they don't care about stripping out the 32-bit/thumb ISA support in the CPU [with what they implies for the pipeline, in particular predication and barrel shifter] and can create a microarchitecture that is purely optimized for the 64-bit ISA.
Maybe this will be the A10, IF the A9 has ARMv8.1a and an Apple GPU.)
Speedfriend - Tuesday, August 4, 2015 - link
"The A7 was adequate to fight off the expected A57;"In hindsight the A7 was not very good at all, it was the reason that Apple was unable to launch a large screen phone with decent battery life. Look at he improvements made to A8, around 10% better performance, but 50% more battery life.
Speedfriend - Tuesday, August 4, 2015 - link
"they've shipped their GPU" by the way, why do you expect them to ship their own GPU and not use IMG's. The IMG GPU have consistently been the best in the market.nunya112 - Monday, August 3, 2015 - link
by the looks of it. the 4790K seems to be the best CPU. until skylake that is. but even then I doubt there will be much improvementnunya112 - Monday, August 3, 2015 - link
unless u have the older ivy's then yeah maybe worth it ?TheinsanegamerN - Monday, August 3, 2015 - link
Nah. the older ivys can be overclocked to easily meet these chips. the IPC of broadwell is overshadowed by a 400mhz lower clock rate on typical OC. only reason to upgrade is if you NEED something on the new chipset or are running some nehalem-era chip.Teknobug - Monday, August 3, 2015 - link
Ivy's are the best overclockers.TheinsanegamerN - Monday, August 3, 2015 - link
Sandy overclocked better than ivy,Hulk - Monday, August 3, 2015 - link
Ian - Very nice job on this one! Thanks.Meaker10 - Monday, August 3, 2015 - link
A slight correction, on the image of crystal well it is the die on the left (the much larger one) which is the cache and the small one is the cpu on the right.