MIPS Strikes Back: 64-bit Warrior I6400 Arrives
by Stephen Barrett on September 2, 2014 10:00 AM ESTMIPS Instruction Set: 64-bit Release 6
Computer processors accomplish tasks by following instructions. The processor, however, only understands instructions in a specific "language". The language of a processor is called its Instruction Set Architecture (ISA). The code sent to a processor must be in that ISA to be understood. It's similar to what would happen if someone proceeded to give me instructions in Portuguese: I unfortunately would have no idea how to execute them. When a program or operating system is authored and compiled, the compiler is parameterized to generate the 1s and 0s of binary code using a specific ISA.
In general, there are two types of ISAs. Complex Instruction Set Computing (CISC) and Reduced Instruction Set Computing (RISC). The difference between them being of course their relative complexity. In general, a RISC ISA contains significantly fewer instructions that are far simpler than a CISC ISA.
Despite its increased complexity, CISC actually predates RISC and was only named retroactively. CISC ISAs were a necessity when low level code (assembly) was often authored by hand, and compilation was crippled by dramatically less powerful compilers than those available today. Having higher level instructions in the ISA, such as looping, allowed simple compilers to extract sufficient performance and human assembly authors to write programs. The most popular CISC ISA ever written is the x86 ISA used in Intel, AMD, and VIA processors. Interestingly, these processors now use dedicated decoding hardware to actually translate CISC instructions into RISC instructions that are executed internally.
RISC ISAs push much of the instruction complexity into the code compiler. Instead of using instruction decode circuits inside the CPU core to translate complex instructions into simple ones, RISC processors operate directly on the simple instructions provided by the compiler. This benefit is somewhat offset as often code compiled for RISC ISAs is larger; it may take multiple RISC instructions for the equivalent CISC instruction. This holds true in computer science theory, as one of the first things taught is there is often a tradeoff between storage and efficiency. If there is a desire for increased efficiency, precompute items ahead of time and then store them. If you need to save storage (or reduce the memory footprint), compute items on-the-fly.
The most popular RISC ISA ever written is the ARM ISA. The MIPS ISA, like ARM, is RISC. It has been revised several times since its inception in 1985. The first five releases are named according to roman numerals I through V, and each was a super set of the last. In 1999, MIPS announced a large revision of the ISA which deprecated the old hierarchical I through V scheme and instead focused on two ISAs: MIPS32 and MIPS64.
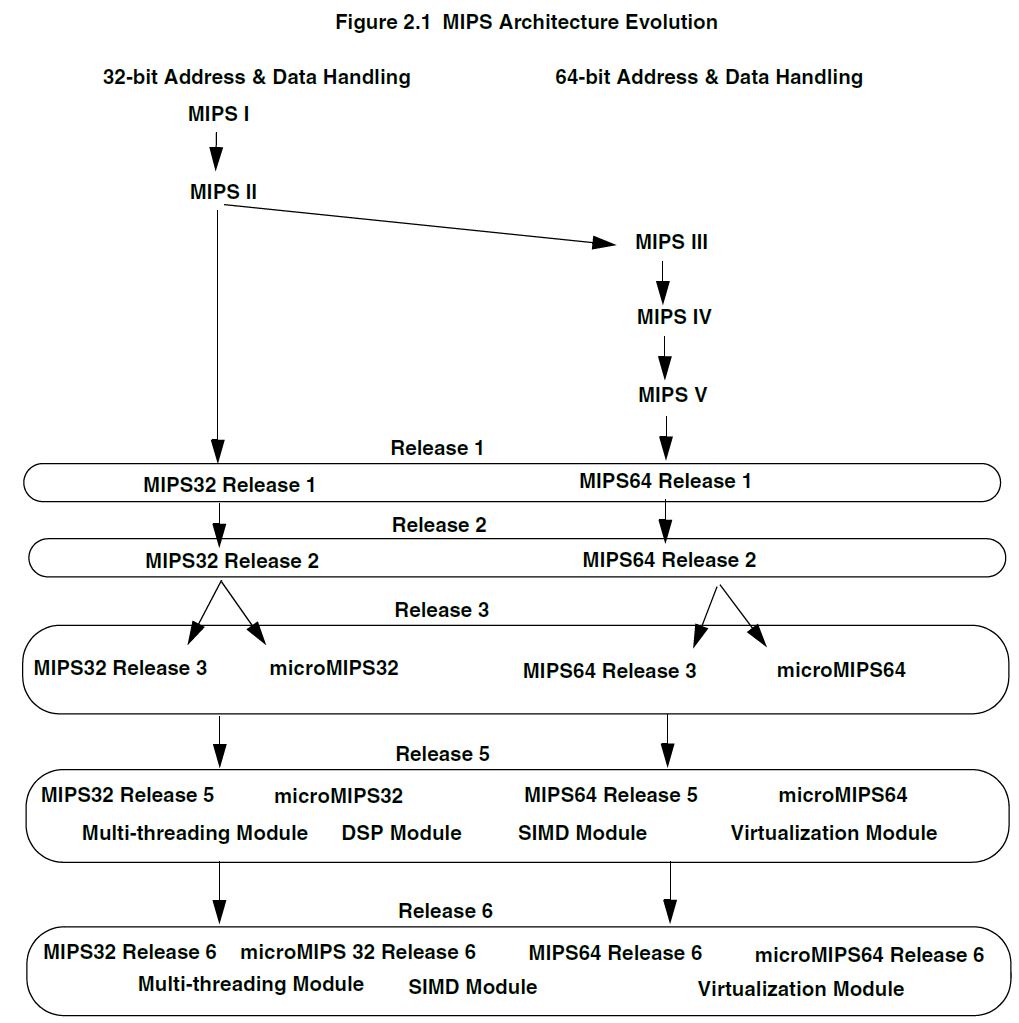
Release 6 occurred in 2014 and the I6400 is the first CPU utilizing the new ISA. I won’t go through all the changes in the ISA, but the most significant is a culling of the instructions. Significant work was done to simplify the ISA by removing infrequently used instructions, in particular those that overlapped with Imagination’s PowerVR GPUs. Additional instructions were also added specifically targeting today’s applications like web browsers. The fruit of these instructions has recently been seen as Google Chrome’s V8 rendering engine added experimental support for MIPS64 release 6 in July.
In the MIPS programmer’s guide the release 6 ISA is actually referred to as MIPS3264 release 6. This naming is not by accident, as MIPS64 ISA is actually a direct superset of the MIPS32 ISA. In contrast to AMD64 (x86-64), there are no "operating modes" that dictate the bitness of instructions executed on the CPU but rather an entirely new set of instructions specifically for 64-bit. Registers inside the CPU are all 64bit, and when a 32-bit instruction executes, results saved in registers are sign-extended to the entire 64-bits of space. This means there is no mode switching, and 32-bit and 64-bit applications can coexist and even be executed using the same hardware resources like registers (more on this later).
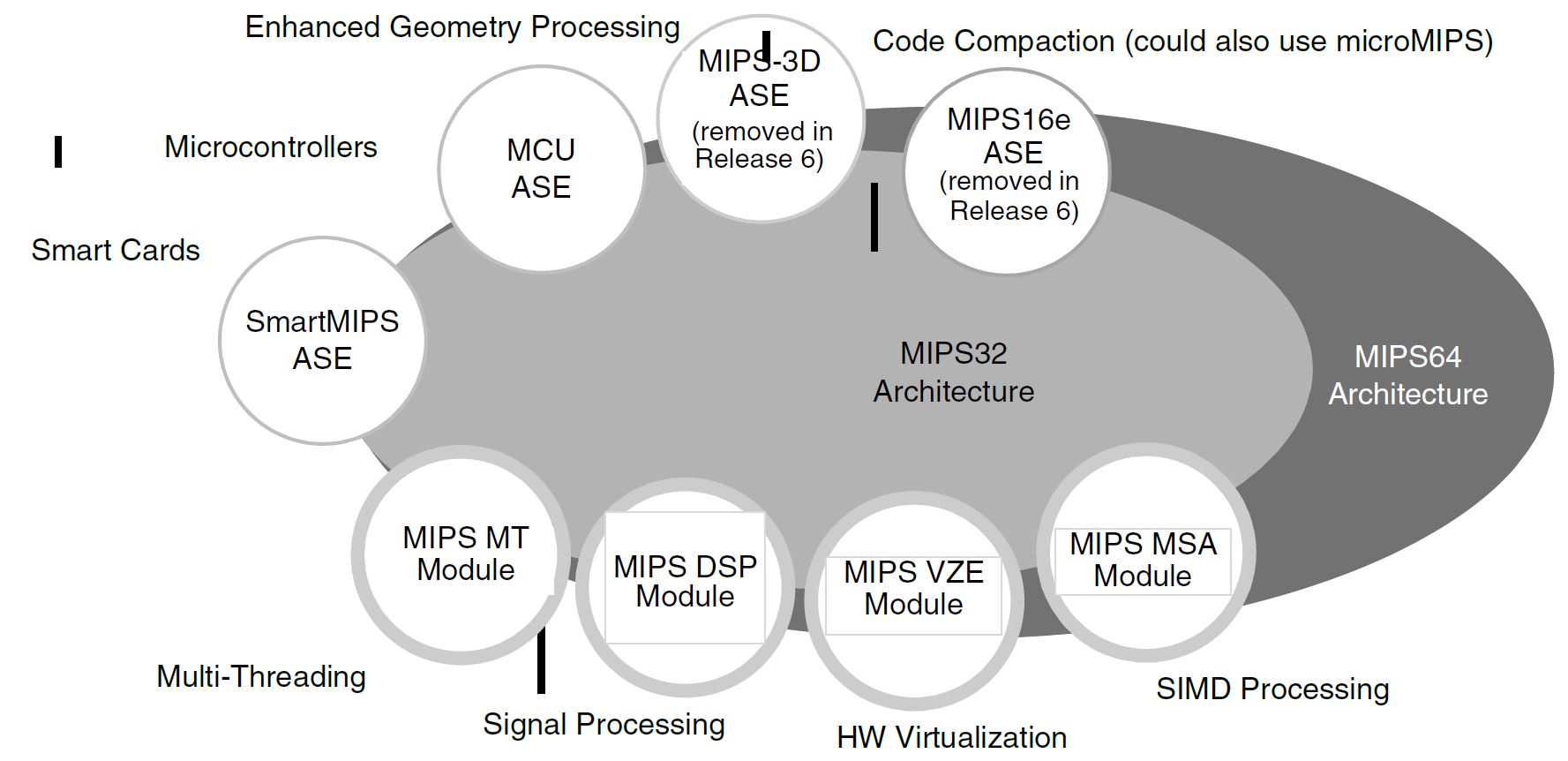
The MIPS ISA contains several optional instructions called Application Specific Extensions. These rely on optional portions of the CPU core that a licensee may or may not implement. Additionally, a MIPS CPU has optional modules that can enhance performance when paired with certain instructions.
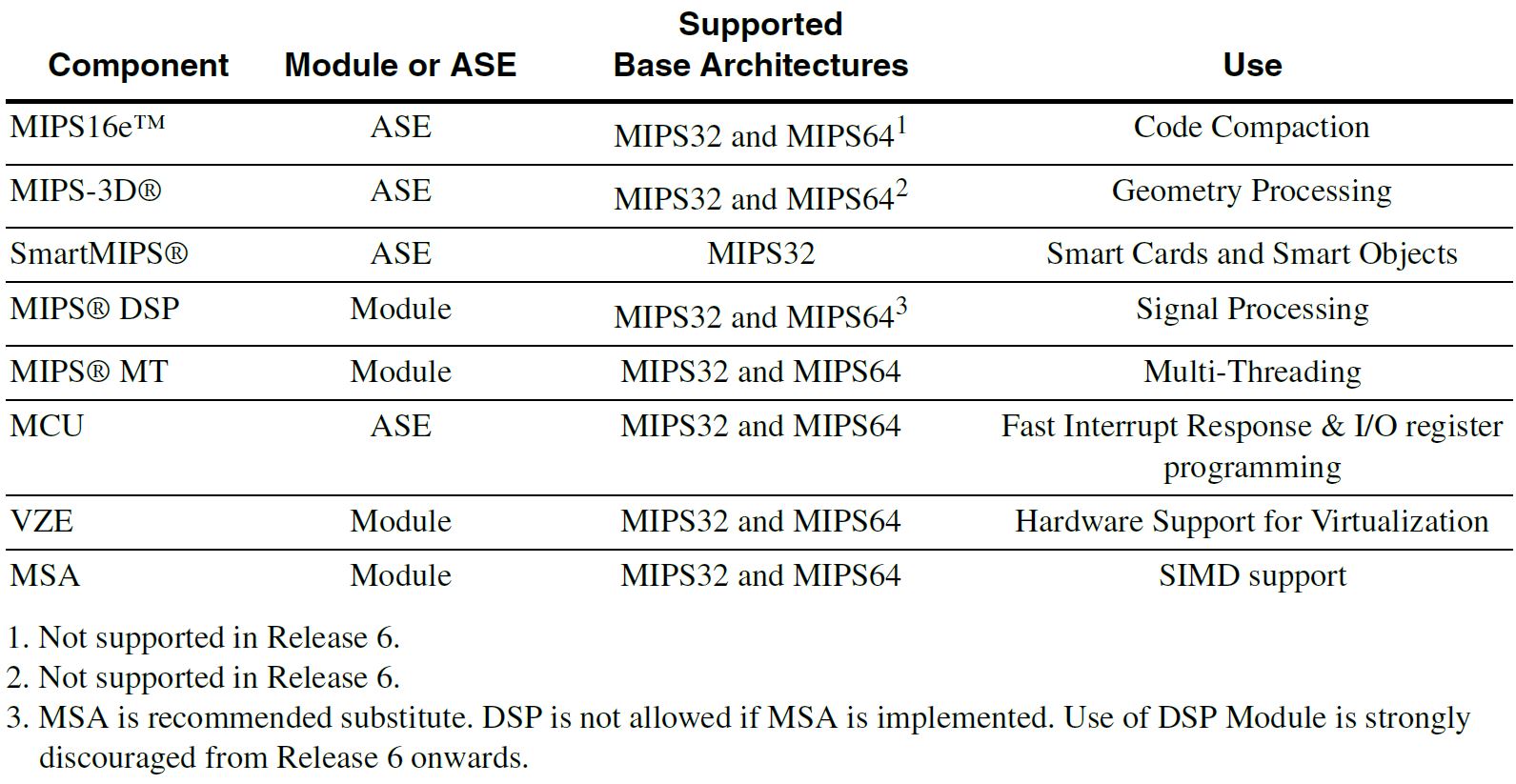
Release 6 drops the legacy MIPS16e ASE as well as the redundant 3D ASE now that Imagination offers GPUs alongside MIPS CPUs.
MIPS CPUs in Mobile Devices
While MIPS CPUs are quite popular in networking equipment and many other embedded industries, consumers will likely only experience one firsthand when it's integrated into an Android handset. Since Android 4.0, Google has supported three ISAs: x86, ARM, and MIPS. Several devices have shipped running MIPS processors, most notably the low-cost Novo 7 tablet. MIPS devices will continue to be low cost alternative devices for now, but low cost devices have the largest volume. The volume should eventually help MIPS push app developers to address their #1 problem: compatibility.
Android applications are either written in Java, then compiled on the device to the specific required ISA before running (a processes called JIT compilation), or written in the Android Native Development Kit (NDK) to target a specific ISA. Apps written in Java can therefore run on any ISA that Android itself supports, including MIPS. Apps written with the NDK (many of which exist, especially games) cannot run on anything but the specific ISA they were written for. The Android NDK does allows packaging multiple ISA specific binaries into a single app, but with the vast majority of Android devices using ARM processors and therefore the ARM ISA, a multiple NDK Android app is simply uncommon.
What does this mean for an end user? There are many Android apps that simply won’t run if you have a MIPS processor in your device. Intel has the same NDK compatibility problem, but with their considerably larger engineering resources, Intel implemented a layer that translates ARM ISA applications to the Intel x86 ISA (albeit at a performance penalty). Until MIPS implements the same or ships enough volume to convince Android app developers to put in some extra work, a MIPS Android device will unfortunately be a second class experience.
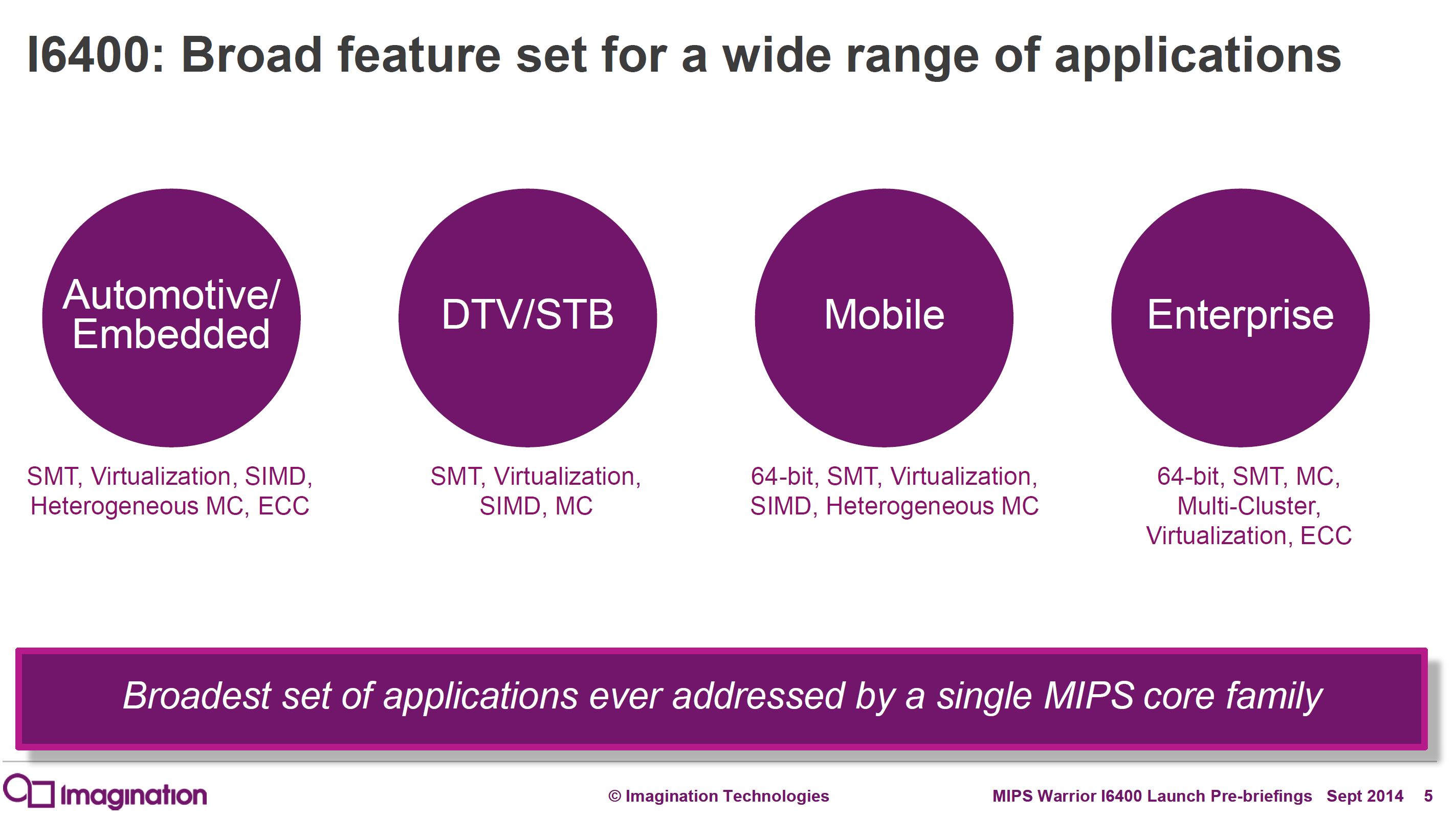

Despite some existing Android app compatibility woes, the MIPS I6400 CPU contains some interesting technology designed to address many more markets than handsets. In fact, Android usage of MIPS processors is really a minor part of the MIPS business. A few slides from the MIPS announcement indicate just how many other markets they are targeting.








84 Comments
View All Comments
alexvoica - Tuesday, September 2, 2014 - link
You've (almost too) carefully forgot to mention the trap-and-emulate feature described in the spec.DMStern - Tuesday, September 2, 2014 - link
The documentation also says that only a subset can be trapped, and that some encodings have been re-used. I haven't studied the instruction encoding tables closely enough to know how many, and how serious the conflicts are. Presumably, as more instructions are added in later revisions, the less useful trapping will be.Daniel Egger - Tuesday, September 2, 2014 - link
Finally! I've been waiting a long time for new decent MIPS processors to show up as I've never quite warmed up with the ARM ISA.However the introduction is missing a couple of important facts (probably even more):
1) RISC is usually a load-and-store architecture, meaning there're registers in abundance and the only way to work with data is to load it into registers and store it back if the result is needed later
2) ... and that's also the reason why the instruction set is much simpler because there're less instruction variants because source and targets are known to be registers and in few cases immediates but almost never those funky combinations of different memory access types one can find in CISC
3) This also means that instruction size is constant on RISC vastly simplifying instruction fetching and decoding
4) Whether the code size increases or decreases compared to CISC very much depends on how the application and compiler can utilize the available registers because most of the bloat in RISC is actually caused by loads and stores, however thanks to register starvation on x86 there might be lots of cases where the addressing causes lots of bloat
I would say if there's a comparison between RISC and CISC it should be more detailed on the important differences. Otherwise, why bother at all?
darkich - Tuesday, September 2, 2014 - link
Great, but unfortunately for Imagination, ARM have already started licensing the successors to Cortex A53 and A57.They are codenamed Artemis and Maya
darkich - Tuesday, September 2, 2014 - link
..a bit of clarification, the Artemis refers to the big core while Maya is the small onetuxRoller - Tuesday, September 2, 2014 - link
Great article Stephen.Could you, at some point, go into a bit more depth on the relationships between out of order, superscalar and simultaneous multithreading? Your description of the dispatcher, and classification of this core as in-order, makes me wonder if I understand it at all. In particular, I didn't realise that superscalar is just a special case of out of order, as your text seems to imply (though you do say that it is not out of order, so it is puzzling).
heartinpiece - Tuesday, September 2, 2014 - link
Some inaccurate information:Snoop coherence protocol doesn't connect cores to other cores, or one core doesn't monitor cache lines of another core.
Instead coherence messages are broadcast to all cores of the system, and each core checks whether it has the cache that was broadcasted, and takes appropriate actions.
If 8 cores use snooping, they don't 'connect' to the other 7, but rather the amount of broadcasted coherence messages increases. (Which may clog the interconnect)
In the directory protocol, when a data is updated, the directory notifies the other cores which hold the data to the same address to invalidate the corresponding cache lines (instead of filling the other cores with the updated value).
The reason for such action is because sending the actual value would be too large, and also, even if it is updated in the other cores, if the other cores don't access the newly updated cacheline, then we have sent the updated value for no reason.
Rather, the invalidated approach takes a lazier approach and only fetches the updated value upon read/write to the cacheline.
Exophase - Wednesday, September 3, 2014 - link
More on snooping in Cortex-A53:"Each core has tag and dirty RAMs that contain the state of the cache line. Rather than access these for each snoop request the SCU contains a set of duplicate tags that permit each coherent data request to be checked against the contents of the other caches in the cluster. The duplicate tags filter coherent requests from the system so that the cores and system can function efficiently even with a high volume of snoops from the system."
Stephen Barrett - Wednesday, September 3, 2014 - link
Interesting! Thank you for this detail. I tried to find info about the SCU but I couldn't and my ARM contacts had not gotten back to me yet. I've added a paragraph about thistuxRoller - Wednesday, September 3, 2014 - link
You might also want to update this sentence as the reasoning no longer seems to apply:"This is likely a contributing factor in why the I6400 can be used in SMP clusters of 6, whereas the A53 is limited to SMP clusters of 4."