The Intel Xeon E7 v2 Review: Quad Socket, Up to 60 Cores/120 Threads
by Johan De Gelas on February 21, 2014 6:00 AM EST- Posted in
- IT Computing
- Intel
- Xeon
- Ivy Bridge EX
- server
- Brickland
Single-Threaded Performance
I admit, the following two benchmarks are almost irrelevant for anyone buying a Xeon E7 based machine. But still, we have to quench our curiosity: how much have the new cores been improved? There is a lot that can be said about all the sophisticated "uncore" improvements (cache coherency policies, low latency rings, and so on) that allow this multi-core monster to scale, but at the end of the day, good performance starts with a good core. And since we have listed the many subtle core improvements, we could not resist the opportunity to check how each core compares.
The results aren't totally meaningless either, as the profile of a compression algorithm is somewhat similar to many server workloads: hard to extract instruction level parallelism (ILP) and sensitive to memory parallelism and latency. The instruction mix is a bit different, but it's still somewhat similar to many server workloads. And as one more reason to test performance in this manner, the 7-zip source code is available under the GNU LGPL license. That allows us to recompile the source code on every machine with the -O2 optimization with gcc 4.8.1.
We've run an additional data point for this particular set of tests. The new Ivy Bridge EX was tested at 2.8GHz and downclocked to 2.4GHz, so that we can do a clock-for-clock comparison with Westmere EX. Since we're only testing single-threaded performance here, other than perhaps slight differences due to having more total L3 cache, it doesn't matter which particular E7 v2 chip we use.
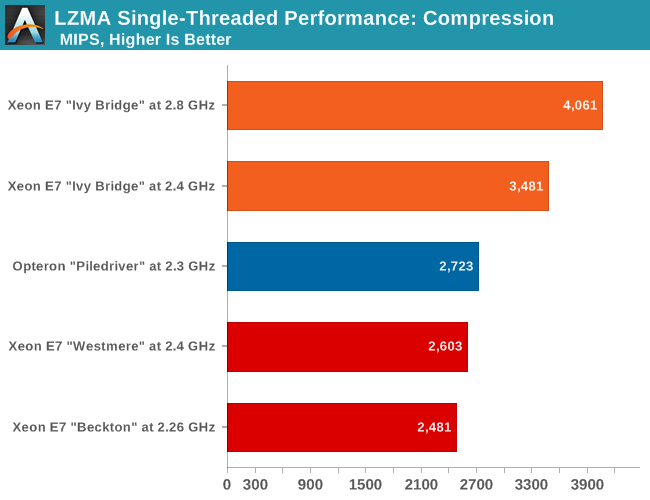
The latest Xeon E7 v2 "Ivy Bridge EX" is capable of extracting 33% more ILP out of the complex compression code than the older Xeon E7 "Westmere-EX" at the same clock speed. That is pretty amazing and shows how all the small micro-architecture improvements have accumulated into a large performance increase. The Opteron core is also better than most people think: at 2.4GHz it would deliver about 2481 MIPs. That is about 80% of Intel's best server core at the moment—not enough, but nothing to be ashamed about.
Also interesting to note is that the Westmere core was indeed a "tick": any performance increase over the Xeon X7560 (Codename "Beckton", 45nm Nehalem core) is simply the result of the higher clockspeed of the 32nm chip.
Let us see how the chips compare in decompression. Decompression is an even lower IPC (Instructions Per Clock) workload, as it is pretty branch intensive and depends on the latencies of the multiply and shift instructions.
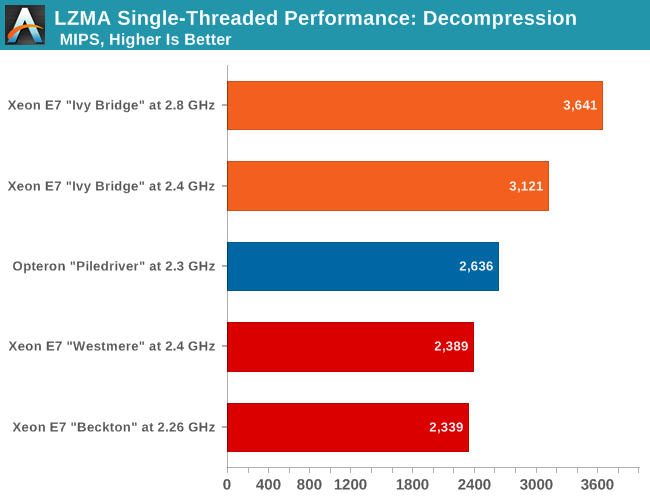
Again, we note a 30% improvement in integer performance going from the Xeon E7 "Westmere" (Xeon E7-4870 at 2.4GHz) to the Xeon E7 v2 "Ivy Bridge EX" (Xeon E7-4890 v2 clocked down to 2.4GHz).
To summarize: the new 15-core Xeon E7 v2 is built upon a strong core architecture that has improved significantly compared to the predecessor.








125 Comments
View All Comments
Kevin G - Monday, February 24, 2014 - link
Even with Itanium's poor performnace, it doesn't stop you from citing the Big Tux experiment to slander overall Linux performance.Brutalizer - Tuesday, February 25, 2014 - link
The reason I cite Big Tux, is because that is the only benchmarks I have seen for Linux running on 64 sockets. If you have other benchmarks, please link to them so I can stop refer to Big Tux.I have never attributed Linux bad performance on Big Tux, because the Itanium has poor performance. I attribute Linux bad performance on Big Tux, because of this: Linux had ~40% cpu utilization on 64 socket Big Tux Itanium server. This means every other cpu idles under full load when using Linux. Is this bad or not? This has nothing to do with Itanium. If Linux ran 64 socket SPARC or POWER - it would still idle ~40%.
Thus, my conclusion of Linux bad performance, is because of the low cpu utilization. It has nothing to do with how fast or slow the hardware. Instead, how good does Linux utilize all resources on large servers? Answer: very bad.
Talking about slandering Linux, have you read this from a prominent Linux kernel developer?
http://vger.kernel.org/~davem/cgi-bin/blog.cgi/200...
"...And here's the punch line, Solaris has never even run on a 1024 cpu system let alone one as big this new SGI system, and Linux has handled it just fine for years. Yet Mr. Bonwick feels compelled to imply that Linux doesn't scale and Solaris does. To claim that Solaris is more ready to scale on large multi-core systems is pure FUD, and I'm saddened to see someone as technically gifted as Jeff stoop to this level..."
Who is slandering who? Is it FUD to say that Linux has scalability problems over 8 sockets? Is it FUD to say that there has never been a 32 socket Linux server for sale? Or is it just that he is not aware of different types of scalability: clusters or SMP servers? Is it just pure ignorance, when he believes a 4096 core Linux cluster can replace a 32 socket SMP server? What do you think? Is it FUD when the ZFS creator claims that Linux does not scale on 32 socket servers, or is it in fact a true claim? Who is FUDing who?
Kevin G - Tuesday, February 25, 2014 - link
Linux scales just as well as Unix on large socket counts. Case in point are IBM's own benchmarks on their p795 systems with 32 sockets, 256 cores and 1024 threads: AIX only beats Linux by a mere 2.7% Source: http://www-03.ibm.com/systems/power/hardware/795/p...I should also point out that your link is 7 years old. Things have changed in the Linux kernel.
hoboville - Monday, February 24, 2014 - link
Well you're right, but it's not as bad for x86 as you make it sound. Systems like TITAN were examples of scale-out compute, if ever there was one. I'll grant it's not the same in terms of what they calculate (Titan is simulation focused and GPU focused) and less on pure RAS and rapid DB access like ERP (not transactional / real time). But that's essentially irrelevant. The point is how they scale in terms of number of nodes and the cost of nodes.Intel's newest chip is cool, but not practical in terms of price competition (why Titan used more Opteron nodes instead of Xeon, for example). What you're focused on is price competition at the ultimate upper end of the spectrum, where SPARC and Power live. And that, in turn, the price of the highest end single system. Intel may be trying to break into that space, but no, it doesn't make sense because x86 wasn't designed for it as an architecture. Their single systems won't compete, yet.
But that's not to say this new Xeon irrelevant. It isn't. It will, however, have problems because of the price-per-performance isn't competitive. In a scale-out design you want more, cheaper nodes and beat the competition by volume. These nodes are just too expensive when you want performance per dollar.
What most mid-to-large companies need is a scalable setup that grows with their business. A lot of IT is bean counting and cost cutting. If you want to start SMP, you start small and tack on additional systems, because your budget people won't let you get a SPARC system or Unix setup. Oracle just doesn't offer systems or prices that are reasonable, and because of this, many businesses that SMP won't give them a second glance. This is where x86 and Xeon fit into the picture, scale out, starting small and building up. But these new systems are asking too much and people aren't going to be interested.
Kevin G - Monday, February 24, 2014 - link
Intel has effectively killed off the Itanium. The original 22 nm Kitson has been scrapped and the successor to Poulson is going to be on 32 nm as well. After that, nothing appears on Intel's roadmap for the chip.HP, the largest Itanium customer, has already announced that their NonStop mainframe line is moving to x86:
Kevin G - Monday, February 24, 2014 - link
Forgot the link: http://h17007.www1.hp.com/us/en/enterprise/servers...Kevin G - Monday, February 24, 2014 - link
"So, instead of you telling me I am wrong, I suggest you just show us links with SMP workloads for the SGI UV2000 server... then you are right, and I am wrong. And I will shut up."United States Post Office running Oracle Data Warehouse software on a SGI UV1000 (the older sibling of the UV2000, still shared memory and cache coherent):
https://www.fbo.gov/index?s=opportunity&mode=f...
SGI and MarkLogic for Big Data:
http://www.v3.co.uk/v3-uk/news/2216603/sgi-and-mar...
I've also found passing references other government (No Such Agency?) installations of a UV2000 installation running Hadoop.
Brutalizer - Tuesday, February 25, 2014 - link
But please, Kevin G, dont you know that Hadoop is a clustered solution? Why do you think people are running clustered database solutiosn as Hadoop on a SGI UV2000 server? Is it because SGI says it is for clustered benchmarks only?And yes, there are clustered databases.
Kevin G - Tuesday, February 25, 2014 - link
Did you not see the link where the USPS is running Oracle workloads on a UV1000? I'll post it again so that you may see: https://www.fbo.gov/index?s=opportunity&mode=f...Kevin G - Tuesday, February 25, 2014 - link
There a couple of reasons why someone would have to run Hadoop on a UV2000: the UV2000 has a large global address space which data could directly reside (ie. no disks access necessary!). If the raw data can reside in 64 TB, performance should be very good. Secondly, Hadoop is free under the Apache license. Traditional database software like Oracle charge a premium the more sockets there are installed on a system. I'd imagine that 256 socket UV2000 system would incur an Oracle licensing fee in the tens of millions of US dollars. So between the choice of free or tens of millions of dollars, most organizations would at least try to work with the free solution.