ADATA XPG V2 Review: 2x8 GB at DDR3-2400 C11-13-13 1.65 V
by Ian Cutress on November 11, 2013 1:00 PM ESTIGP Compute
One of the touted benefits of Haswell is the compute capability afforded by the IGP. For anyone using DirectCompute or C++ AMP, the compute units of the HD 4600 can be exploited as easily as any discrete GPU, although efficiency might come into question. Shown in some of the benchmarks below, it is faster for some of our computational software to run on the IGP than the CPU (particularly the highly multithreaded scenarios).
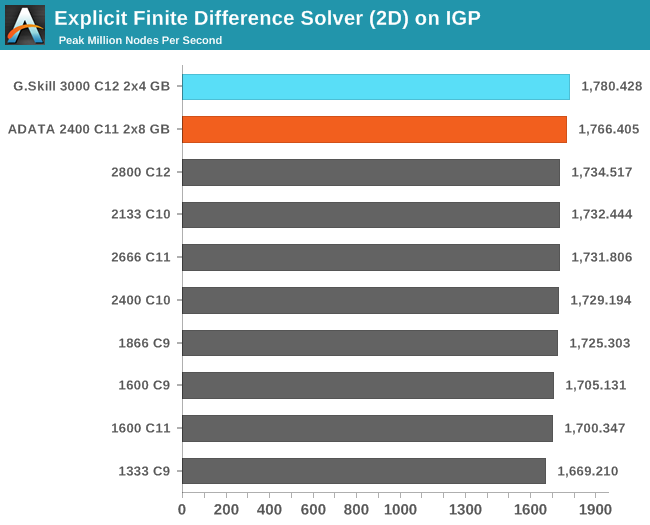
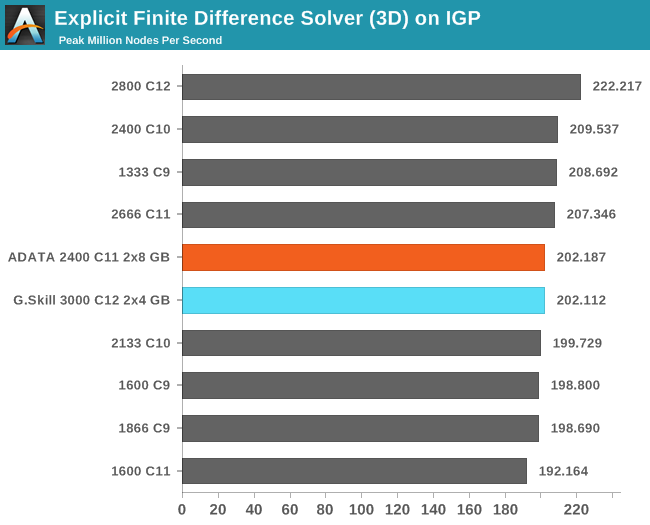
Grid Solvers - Explicit Finite Difference on IGP
As before, we test both 2D and 3D explicit finite difference simulations with 2n nodes in each dimension, using OpenMP as the threading operator in single precision. The grid is isotropic and the boundary conditions are sinks. We iterate through a series of grid sizes, and results are shown in terms of ‘million nodes per second’ where the peak value is given in the results – higher is better.
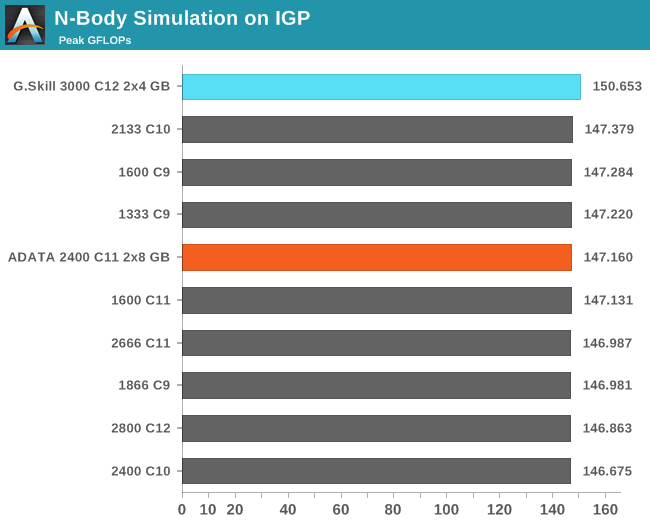
N-Body Simulation on IGP
As with the CPU compute, we run a simulation of 10240 particles of equal mass - the output for this code is in terms of GFLOPs, and the result recorded was the peak GFLOPs value.
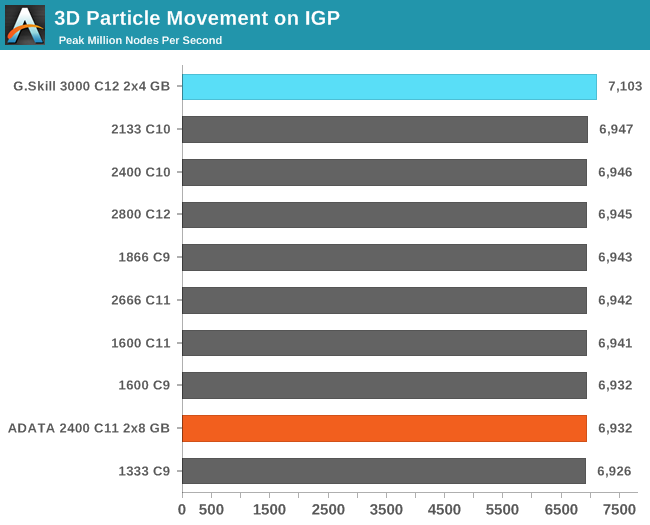
3D Particle Movement on IGP
Similar to our CPU Compute algorithm, we calculate the random motion in 3D of free particles involving random number generation and trigonometric functions. For this application we take the fastest true-3D motion algorithm and test a variety of particle densities to find the peak movement speed. Results are given in ‘million particle movements calculated per second’, and a higher number is better.
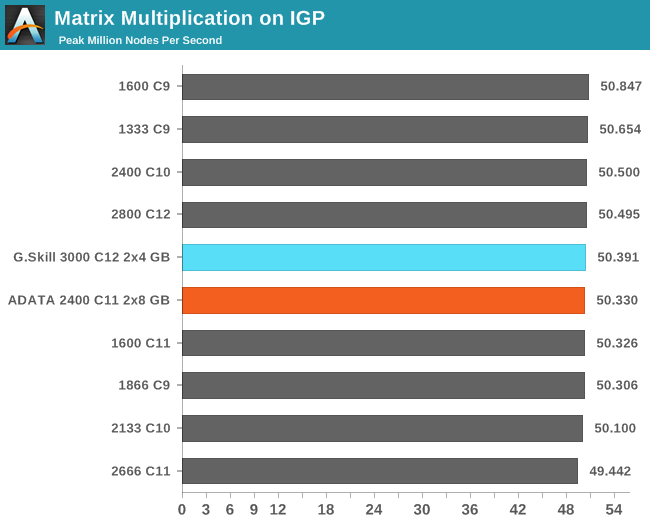
Matrix Multiplication on IGP
Matrix Multiplication occurs in a number of mathematical models, and is typically designed to avoid memory accesses where possible and optimize for a number of reads and writes depending on the registers available to each thread or batch of dispatched threads. He we have a crude MatMul implementation, and iterate through a variety of matrix sizes to find the peak speed. Results are given in terms of ‘million nodes per second’ and a higher number is better.








23 Comments
View All Comments
IanCutress - Tuesday, November 12, 2013 - link
BF4 will hopefully be part of my 2014 test bed, I'm still getting equipment arranged to make it relevant and trying to decide a consistent benchmark. Running through an empty server atm is the only consistent way, but it might not be considered a true representation of what's possible.d9ssk02md - Tuesday, November 12, 2013 - link
Well, on my sandy bridge it only took a year or two of running memory at 1.65V to develop random freezes. Lowering the voltage (and the speed) to 1.5V made the issue completely disappear.Gen-An - Tuesday, November 12, 2013 - link
A bit surprising these couldn't go higher, considering they are likely using Hynix H5TQ4G83MFR ICs. I have some sticks of the same bin (2400C11 2x8GB) but a different brand (Silicon Power) and I've been able to push them to 2933.