AMD’s Jaguar Architecture: The CPU Powering Xbox One, PlayStation 4, Kabini & Temash
by Anand Lal Shimpi on May 23, 2013 12:00 AM ESTKabini: Mainstream APU for Notebooks
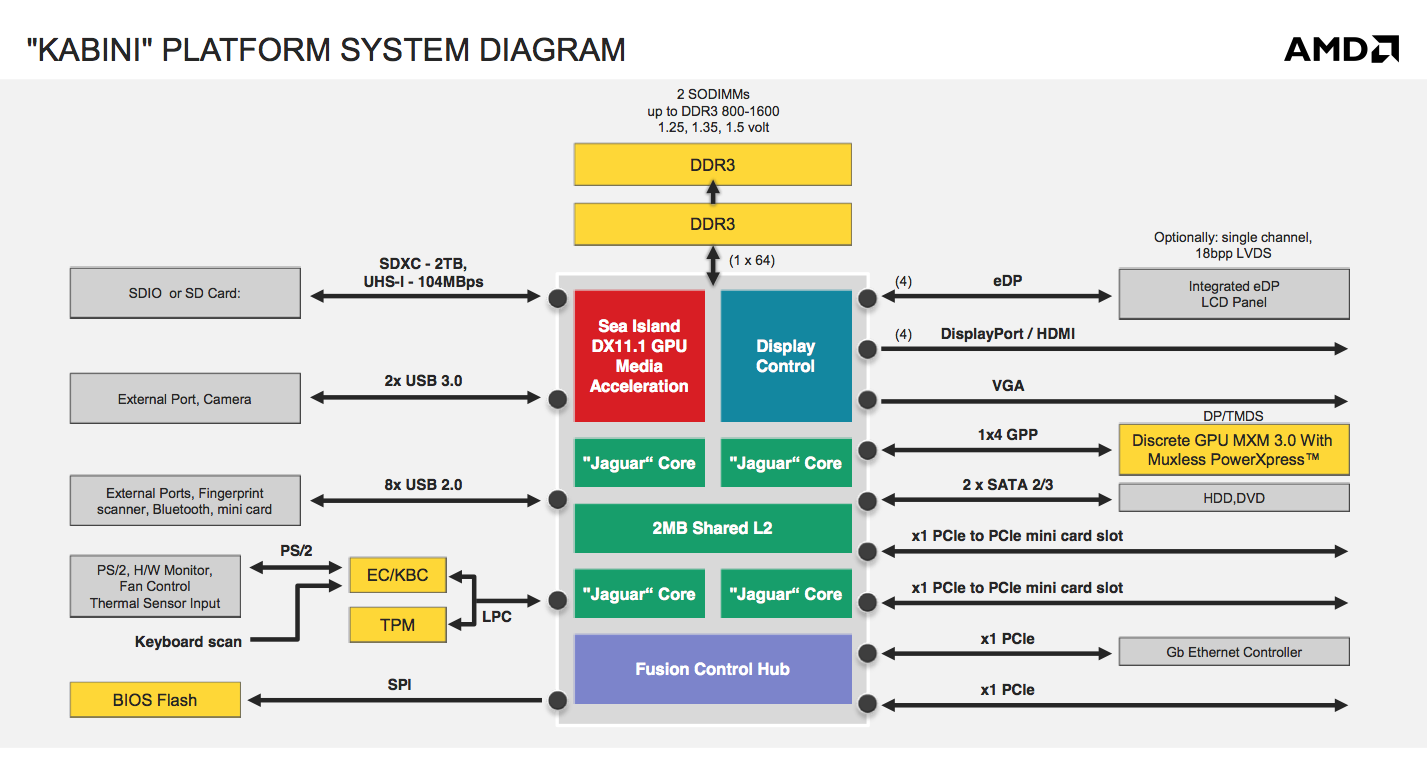
AMD will be building two APUs based on Jaguar: Kabini and Temash. Kabini is AMD’s mainstream APU, which you can expect to see in ultra-thin affordable notebooks. Note that both of these are full blown SoCs by conventional definitions - the IO hub is integrated into the monolithic die. Kabini ends up being the first quad-core x86 SoC if we go by that definition.
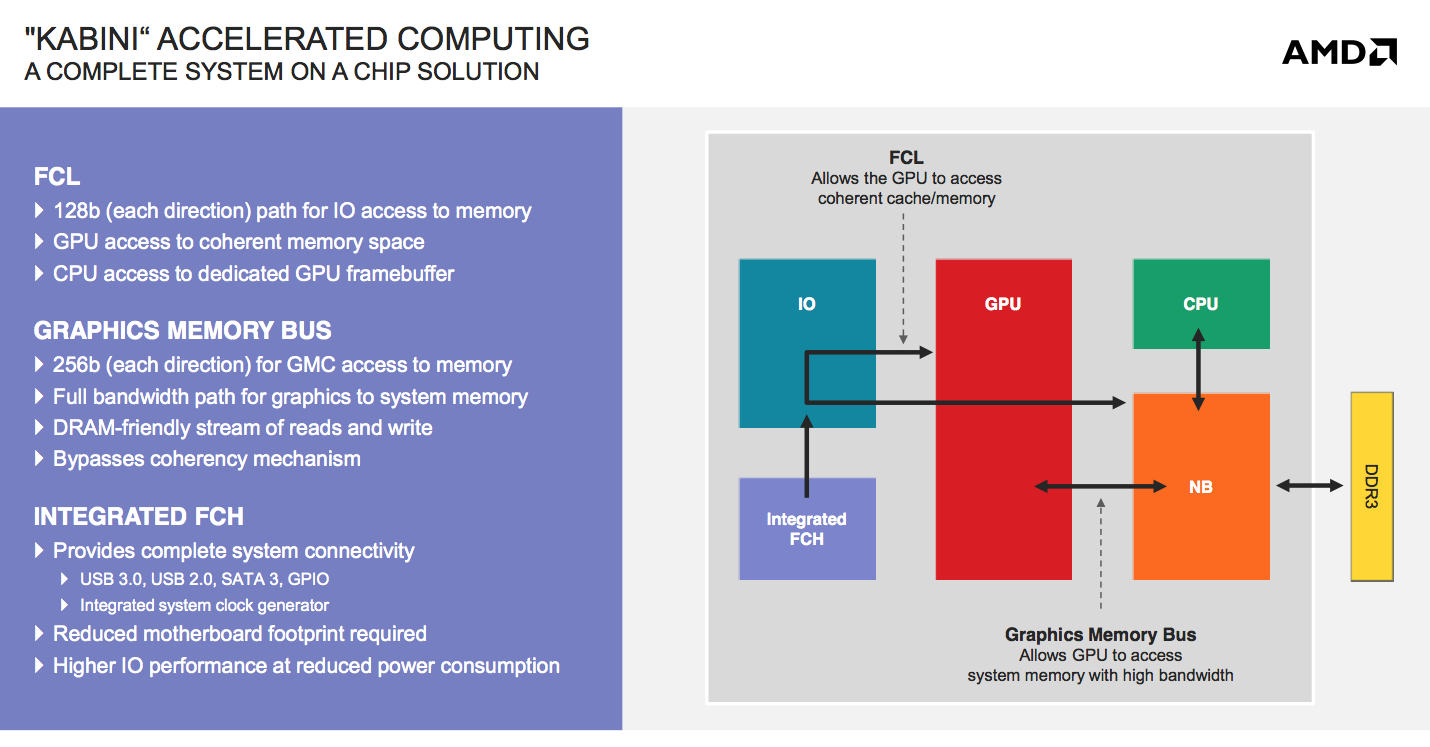
Kabini will carry A and E series branding, and will be available in a full quad-core version (A series) as well as dual-core (E series). The list of Kabini parts launching is below:
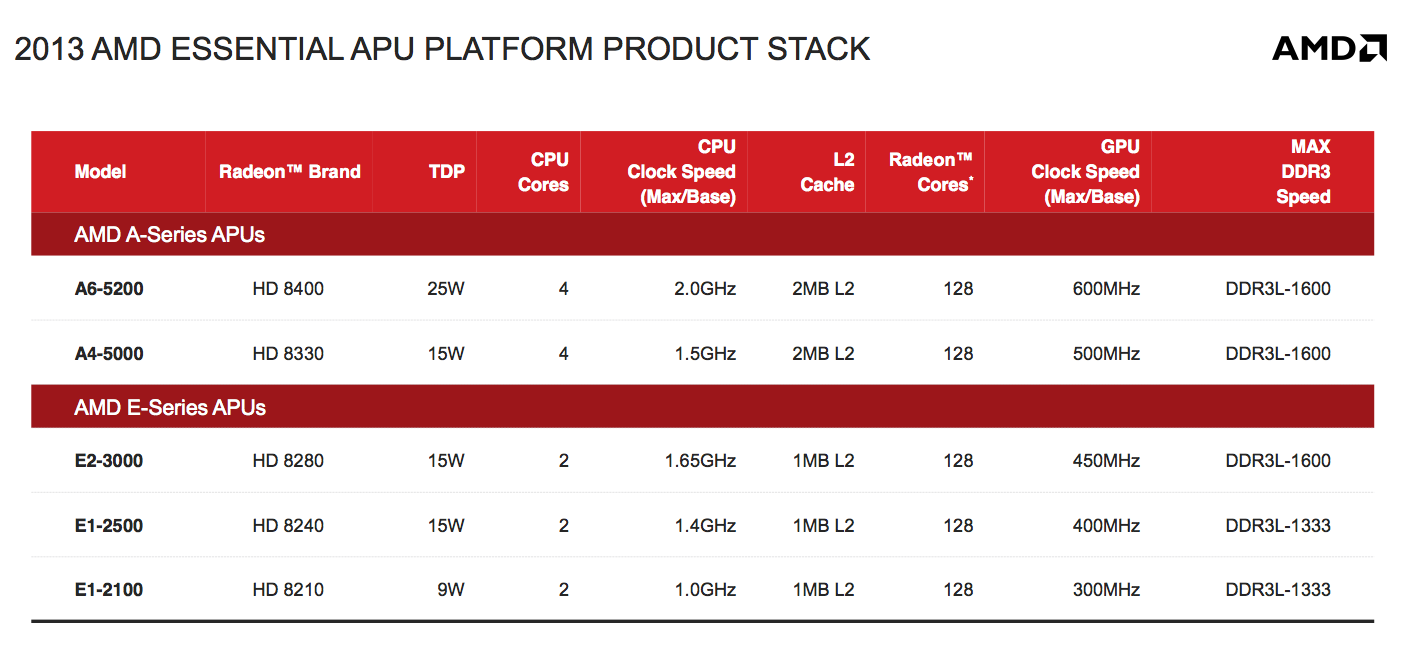
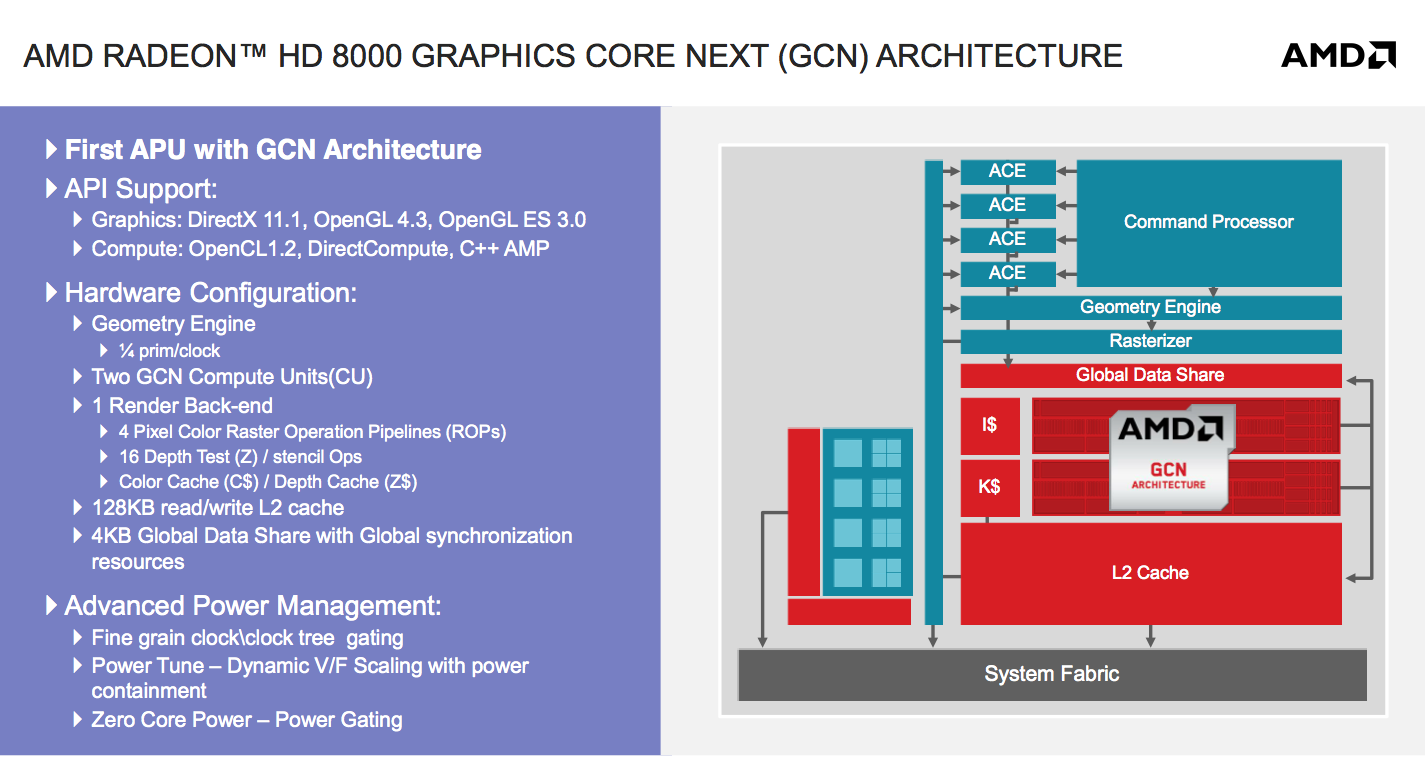
On the GPU side we have a 2 Compute Unit implementation of AMD’s Graphics Core Next architecture. The geometry engine has been culled a bit (1/4 primitive per clock) in order to make the transition into these smaller/low cost APUs. Double precision is supported at 1/16 rate, although adds and some muls will run at 1/8 the single precision rate.

Kabini features a single 64-bit DDR3 memory controller and ranges in TDPs from 9W to 25W. Although Jaguar supports dynamic frequency boosting (aka Turbo mode), the feature isn’t present/enabled on Kabini - all of the CPU clocks noted in the table above are the highest you’ll see regardless of core activity.
We have a separate review focusing on the performance of AMD’s A4-5000 Kabini APU live today as well.
Temash: Entry Level APU for Tablets
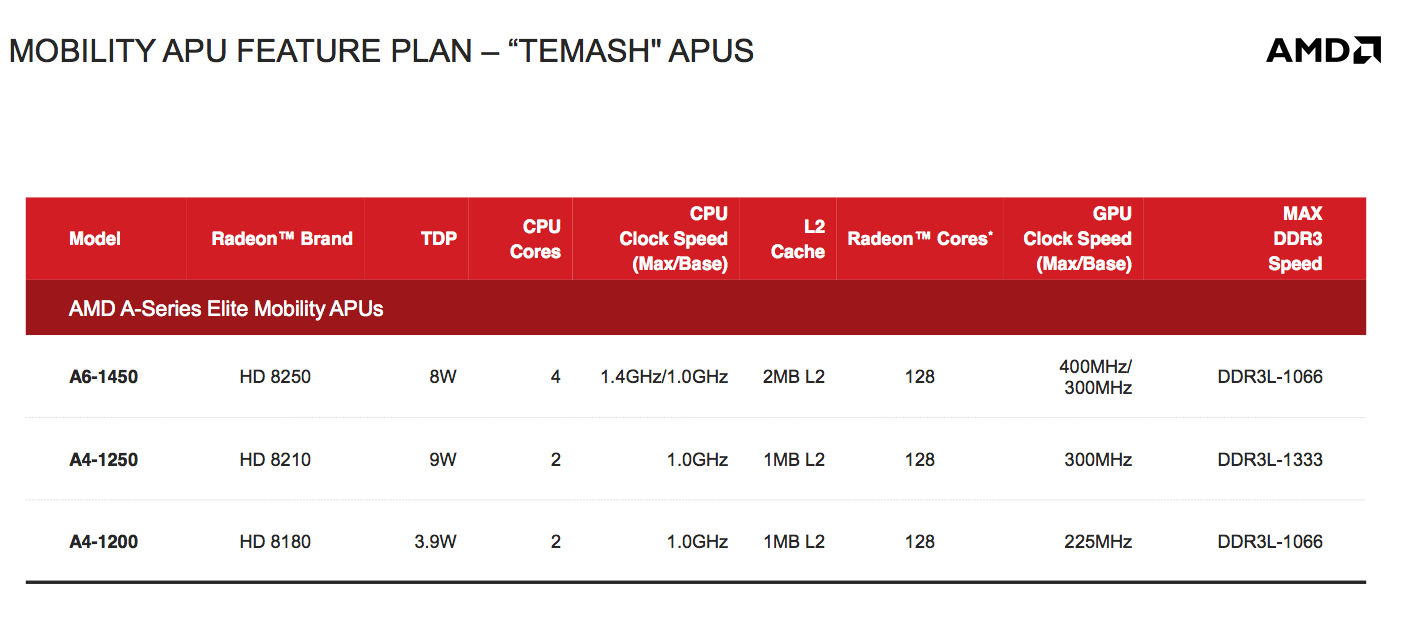
While Kabini will go into more traditional notebook designs, Temash will head down into the tablet space. The Temash TDPs range from 3.9W all the way up to 9W. Of the three Temash parts launching today, two are dual-core designs with the highest end A6-1450 boasting 4 cores as well as support for turbo core. The A6-1450’s turbo core implementation also enables TDP sharing between the CPU and GPU cores (idle CPUs can be power gated and their thermal budget given to the GPU, and vice versa).
The A4-1200 is quite interesting as it carries a sub-4W TDP, low enough to make it into an iPad-like form factor. It’s also important to note that AMD doesn’t actually reduce the number of GPU cores in any of the Temash designs, it just scales down clock speed.
Xbox One & PlayStation 4
In both our Xbox One and PS4 articles I referred to the SoCs as using two Jaguar compute units - now you can understand why. Both designs incorporate two quad-core Jaguar modules, each with their own shared 2MB L2 cache. Communication between the modules isn’t ideal, so we’ll likely see both consoles prefer that related tasks run on the same module.
Looking at Kabini, we have a good idea of the dynamic range for Jaguar on TSMC’s 28nm process: 1GHz - 2GHz. Right around 1.6GHz seems to be the sweet spot, as going to 2GHz requires a 66% increase in TDP.
The major change between AMD’s Temash/Kabini Jaguar implementations as what’s done in the consoles is really all of the unified memory addressing work and any coherency that’s supported on the platforms. Memory buses are obviously very different as well, but the CPU cores themselves are pretty much identical to what we’ve outlined here.








78 Comments
View All Comments
fluxtatic - Thursday, May 23, 2013 - link
Whoa - I think this is the first useful thing I've learned today. I've been wondering the same thing for a long time. Thanks!Ev1l_Ash - Wednesday, May 28, 2014 - link
Thanks for that quasi!Tuna-Fish - Thursday, May 23, 2013 - link
quasi was more accurate than his name implies, but just to expand on it:The count of custom macros is important because when you switch manufacturing processes, the work you have to re-do on the new process is the macros. Old cpus were "all custom macro", meaning that switching the manufacturing process meant re-doing all the physical design. A cpu that has a very limited amount of custom macros can be manufactured at different fabs without breaking the bank.
lmcd - Thursday, May 23, 2013 - link
Sorry, didn't see your post.lmcd - Thursday, May 23, 2013 - link
To suppliment quasi_accurate (as I understand) these are parts of the chip that need checked on, adjusted and corrected, and/or even replaced depending on the foundry.So, reducing these isn't a priority for Intel, but for AMD who wants portability (ability to use both GloFo and TMSC) it's a priority.
tiquio - Thursday, May 23, 2013 - link
Thanks quasi_accurate, Tuna-Fish and lmcd. Your answers were very clear.If I my understanding is correct, would it be safe to assume that Apple's A6 uses custom macros. Anand mentioned in his article that Apple used a custom layout of ARM to maximize performance. Is this one example of custom macros.
name99 - Friday, May 24, 2013 - link
You can customize a variety of things, from individual transistors (eg fast but leaky vs slow but non-leaky), to circuits, to layout.As I understand it the AMD issue is about customized vs automatic CIRCUITS. The Apple issue is about customized vs automatic LAYOUT (ie placement of items and the wiring connecting them).
Transistors are obviously most fab-specific, so you are really screwed if your design depends on them specifically (eg you can't build your finFET design at a non-finFET fab). Circuit design is still somewhat fab-specific --- you can probably get it to run on a different fab, but at lower frequency and higher power, so it's still not where you want to be. Layout, on the other hand, I don't think is very fab-specific at all (unless you do something like use 13 metal layers and then want to move to a fab than can only handle a maximum of 10 metal layers).
I'd be happy to be corrected on any of this, but I think that's the broad outline of the issues.
iwodo - Thursday, May 23, 2013 - link
Really want this to be in Servers. Storage Servers, Home based NAS, caching / front end servers etc.JohanAnandtech - Thursday, May 23, 2013 - link
agree. With a much downsized graphics core, and higher clocks for the CPU.Alex_Haddock - Thursday, May 23, 2013 - link
We will certainly have Kyoto in Moonshot :-) . http://h30507.www3.hp.com/t5/Hyperscale-Computing-...