AMD’s Jaguar Architecture: The CPU Powering Xbox One, PlayStation 4, Kabini & Temash
by Anand Lal Shimpi on May 23, 2013 12:00 AM ESTCompute Unit
Bobcat was pretty simple from a multi-core standpoint. Each Bobcat core had its own private 512KB L2 cache, and all core-to-core communication happened via a bus interface on each of the cores. The cache hierarchy was exclusive, as has been the case with all of AMD’s previous architectures.
Jaguar changes everything. AMD defines a Jaguar compute unit as up to four cores with a single, large, shared L2 cache. The L2 cache can be up to 2MB in size and is 16-way set associative. The L2 cache is also inclusive, a first in AMD’s history. In the past AMD always implemented exclusive caches as the inclusive duplicating of L1 data in L2 meant a smaller effective L2 cache. The larger shared L2 cache is responsible for up to another 5-7% increase in IPC over Bobcat (totaling ~22%).
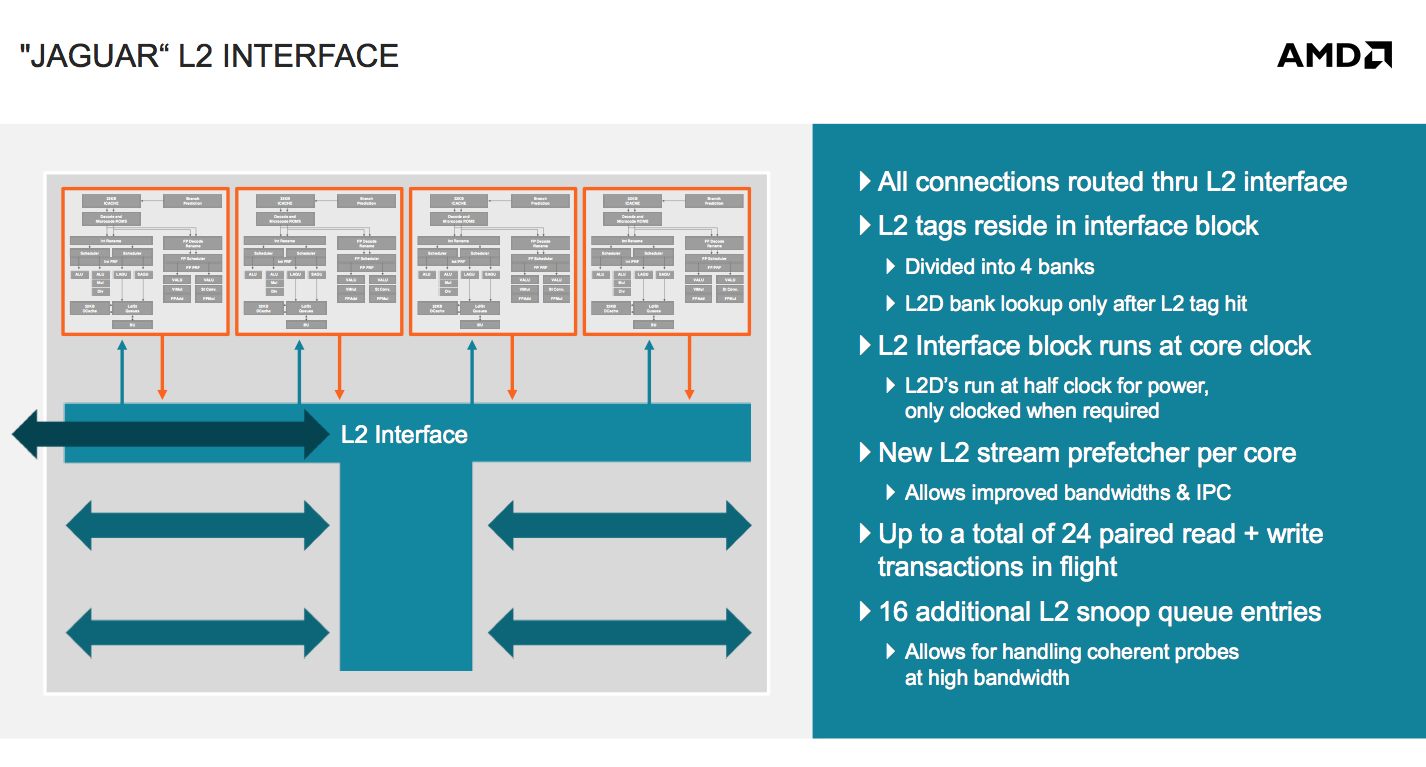
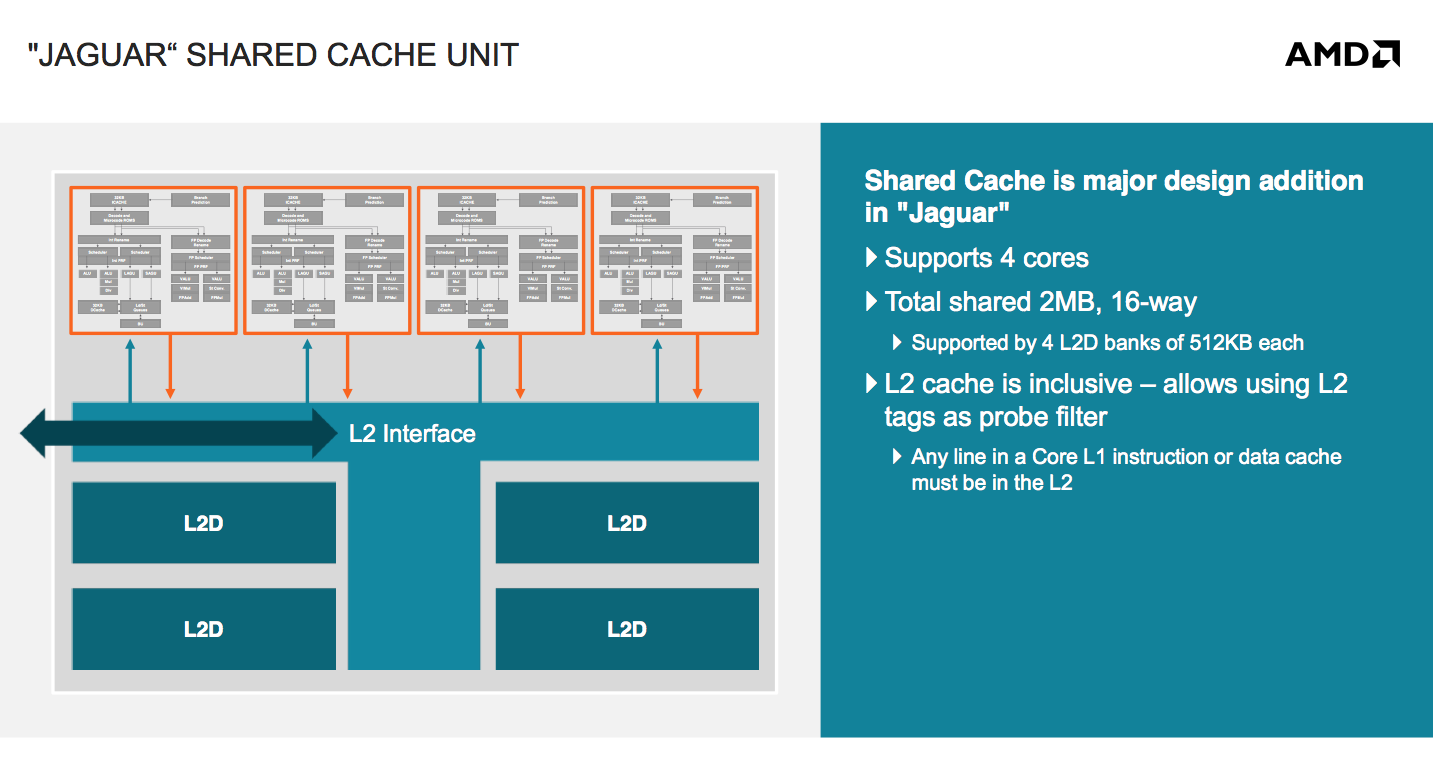
AMD’s new cache architecture and lower latency core-to-core communication within a Jaguar compute unit means an even greater performance advantage over Bobcat in multithreaded workloads:
| Multithreaded Performance Comparison | ||||||||||||||||
| # of Cores | Cinebench 11.5 (Single Threaded) | Cinebench 11.5 (Multithreaded) | ||||||||||||||
| AMD A4-5000 (1.5GHz Jaguar x 4) | 4 | 0.39 | 1.5 | |||||||||||||
| AMD E-350 (1.6GHz Bobcat x 2) | 2 | 0.32 | 0.61 | |||||||||||||
| Advantage | 100% | 21.9% | 145.9% | |||||||||||||
The L1 caches remain unchanged at 32KB/32KB (I/D cache) per core.
Physical Layout and Synthesis
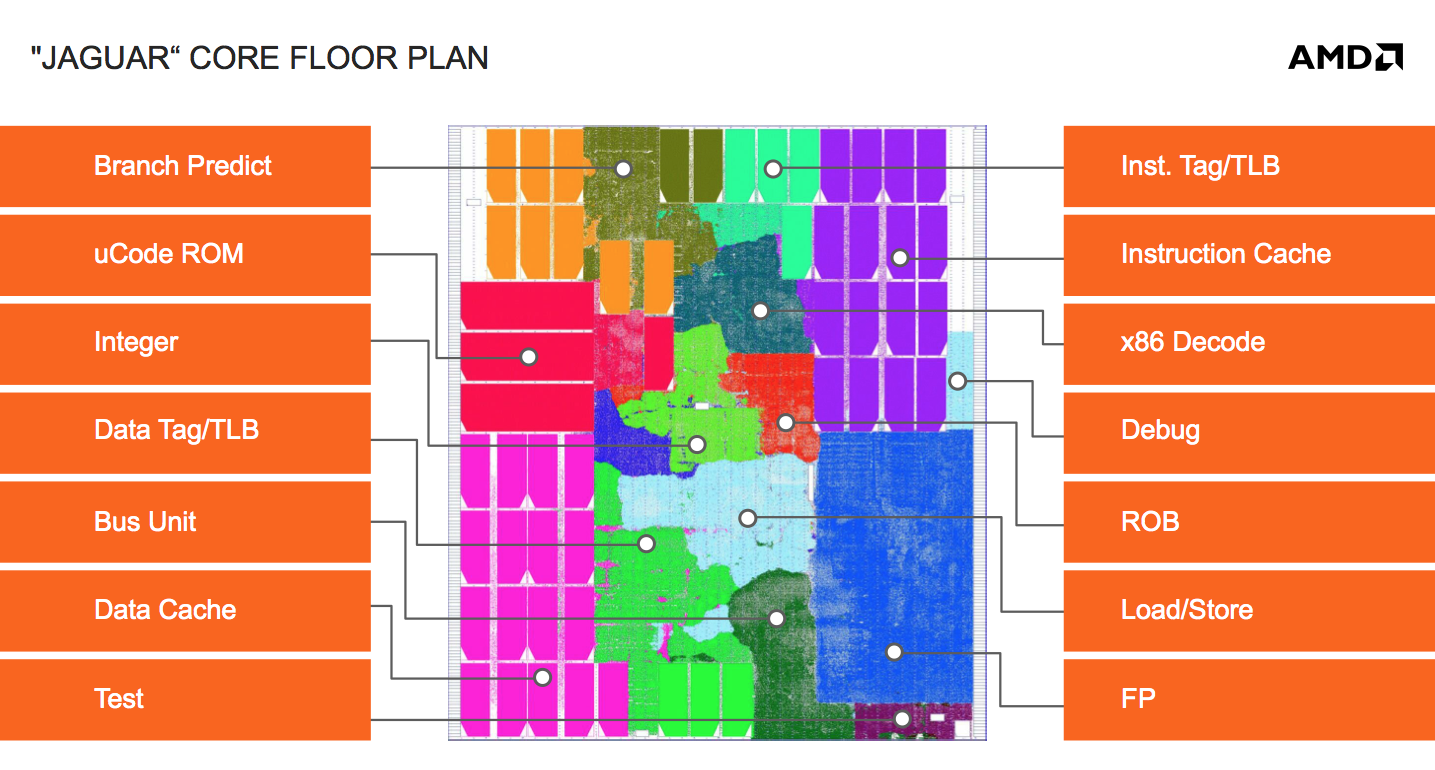
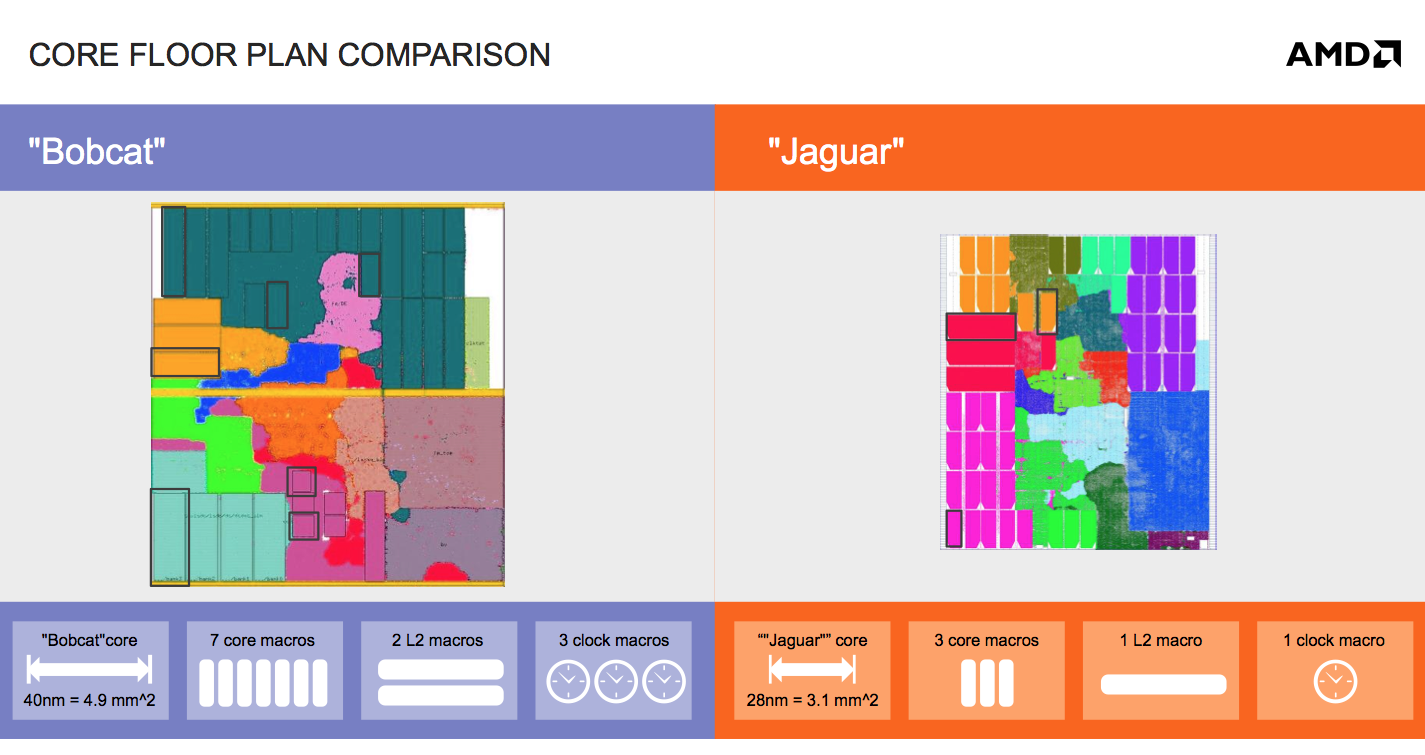
Bobcat was AMD’s first easily synthesized CPU core, it was a direct result of the ATI acquisition years before. With Jaguar, AMD made a conscious effort to further reduce the number of unique macros required by the design. The result was a great simplification, which helped AMD port Jaguar between foundries. There’s of course an area tradeoff when moving away from custom macros to more general designs but it was deemed worthwhile. Looking at the results, you really can’t argue. A single Jaguar core measures only 3.1mm^2 at 28nm compared to 4.9mm^2 for a 40nm Bobcat.








78 Comments
View All Comments
vision33r - Thursday, May 23, 2013 - link
Real shame is that AMD has not gotten into the mobile market at all. APUs like this would've been great for tablets.jeffkibuule - Thursday, May 23, 2013 - link
Even if AMD makes the chip, and OEM has to be willing to use it.duploxxx - Thursday, May 23, 2013 - link
exactly the problem, current atom is a horrible cpu in wathever device, whatever frequency you put it. have used them in notebooks and even now in a tablet. Bobcat on the other hand was awesome in the netbook range. THe temash would be way better suited for all these devices but as usual OEM focus on the blue brand with market jingles and dominancy and in the end its the end consumer (WE) that suffer from it and if it continues like this we will even suffer more. (less innovative, higher prices, dominant predefined design (something already horrible today) but many people fail to see that........as if they think there Intel system they just bought is a better suited device for everything...mganai - Thursday, May 23, 2013 - link
Intel's been going easy on AMD these past few years.Plus, Atom is finally due for its big update this year, following which we'll be seeing a more frequent update schedule in line with their Core processors.
The heterogeneous solution was what won the PS4 and XB1 for AMD.
thebeastie - Saturday, May 25, 2013 - link
Simple, Money! Why roll as fast as you can when your already the fastest and aren't going to be bringing any more money then you are now.Bobs_Your_Uncle - Saturday, May 25, 2013 - link
I'd read an interesting perspective on why Intel refrained from "kicking AMD to the curb & on down into the storm sewer" (sorry; can't recall the source). In essence, given the scope of Intel's unquestioned dominance in their chosen markets, (& mobile's on the radar), were they to act with any obvious & direct intent to further weaken, (or even try & finish off), AMD, Intel would find themselves in an extremely difficult, exceedingly complex & decidedly unpleasant set of circumstances.By decimating their only possible source of true competition, Intel would be responsible for invoking upon themselves intense anti-trust scrutiny; a result that would be inevitable assuming regulatory agencies were functioning properly.
By backing off a bit, Intel may well cede some amount of business to AMD, but they retain a legitimate market competitor & at the same time continue collecting very healthy margins. The premiums charged on sales can then be used to continue funding aggressive Intel R&D, and, uh, marketing related expenditures, too.
spartaman64 - Wednesday, June 4, 2014 - link
for a company that could "kick amd to the curb" intel is awfully nervous about amd's kaveriWolfpup - Wednesday, June 12, 2013 - link
Yeah, but regardless AMD's had the FAR better CPU now for years. I've been running the lowest end version of it for a couple of years in a tiny notebook, and from the beginning wished people were using it for tablets.Flunk - Friday, June 6, 2014 - link
When you say current Atom, are you referring to Baytrail? Previous Atoms were pretty bad for Windows boxes, in my personal experience. But the new generation is significantly more powerful (About on par with a Core 2 Duo on benchmarks). They seem pretty reasonable for basic office tasks, this may not include all the lowest-end versions.Flunk - Friday, June 6, 2014 - link
NVM, followed the wrong link and didn't see the date. Thought this was about something else. May 2013 Atoms sucked.