Gigabyte GA-7PESH1 Review: A Dual Processor Motherboard through a Scientist’s Eyes
by Ian Cutress on January 5, 2013 10:00 AM EST- Posted in
- Motherboards
- Gigabyte
- C602
Brownian Motion
When chemicals move around in the air, or dissolved in a liquid, or even travelling through a solid, they diffuse from an area of high concentration to low concentration, or follow Le Chatelier’s principle if an external force is applied. Typically this movement is described via an overall statistical shift, expressed as a partial differential equation. However, if we were to pick out an individual chemical and observe its movements, we would see that it moves randomly according to thermal energy – at every step it moves in a random direction until an external force (such as another chemical gets in the way) is encountered. If we sum up the movements of millions or billions of such events, we get the gradual motion explained by statistics.
The purpose of Brownian motion simulation is to calculate what happens to individual chemicals in circumstances where the finite motion is what dictates the activity occurring. For example, experiments dealing with single molecule detection rely on how a single molecule moves, or during deposition chemistry, the movement of individual chemicals will dictate how a surface achieves deposition in light of other factors. The movement of the single particle is often referred to a Random Walk (of which there are several types).
There are two main differences between a random-walk simulation and the finite difference methods used over the previous pages. The first difference is that in a random walk simulation each particle in the simulation is modelled as a point particle, completely independent in its movement with respect to other particles in the simulation (the diffusion coefficient in this context is indirectly indicative of the medium through which the particle is travelling through). With point particles, the interactions at boundaries can be quantized with respect to the time in simulation. From the perspective of independent particles, we can utilise various simulation techniques designed for parallel problems, such as multi-CPU analysis or using GPUs. To an extent, this negates various commentaries which criticise the random-walk method for being exceedingly slow.
The second difference is the applicability to three dimensional simulations. Previous methods for tackling three dimensional diffusion (in the field I was in) have relied on explicit finite difference calculation of uncomplicated geometries, which result in large simulation times due to the unstable nature of the discretisation method. The alternating direction implicit finite difference method in three dimensions has also been used, but can suffer from oscillation and stability issues depending on the algorithm method used. Boundary element simulation can be mathematically complex for this work, and finite element simulation can suffer from poor accuracy. The random-walk scenario is adaptable to a wide range of geometries and by simple redefinition of boundaries and/or boundary conditions, with little change to the simulation code.
In a random walk simulation, each particle present in the simulation moves in a random direction at a given speed for a time step (determined by the diffusion coefficient). Two factors computationally come into play – the generation of random numbers, and the algorithm for determining the direction in which the particle moves.
Random number generation is literally a minefield when first jumped into. Anyone with coding experience should have come across a rand() function that is used to quickly (and messily) generate a random number. This number as a function of the language library repeats itself fairly regularly, often within 2^15 (32768) steps. If a simulation is dealing with particles doing 100,000 steps, or billions of particles, this random number generator is not sufficient. For both CPU and GPU there are a number of free random number generators available, and ones like the Mersenne Twister are very popular. We use the Ranq1 random number generator found in Numerical Recipes 3rd Edition: The Art of Scientific Computing by Press et al., which features a quick generation which has a repeated stepping of ~1.8 x 10^19. Depending on the type of simulation contraints, in order to optimize the speed of the simulation, the random numbers can be generated in an array before the threads are issued and the timers started then sent through the function call. This uses additional memory, but is observed to be quicker than generating random numbers on the fly in the movement function itself.
Random Movement Algorithms
Trying to generate random movement is a little trickier than random numbers. To move a certain distance from an original point, the particle could end up anywhere on the surface of a sphere. The algorithm to generate such movement is not as trivial as a random axial angle followed by a random azimuth angle, as this generates movement biased at the poles of a sphere. By doing some research, I published six methods I had found for generating random points on the surface of a sphere.
For completeness, the notation x ~ U(0,1] means that x is a uniformly generated single-ended random number between 0 and 1.
(i) Cosine Method
In spherical polar coordinates, the solid angle of a sphere, Ω, is defined as the area A covered by that angle divided by the square of the radius, re, as shown in equation 14. The rate of change of this angle with respect to the area at constant radius gives the following set of equations:
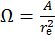 [14]
[14]
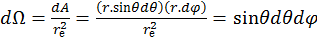 [15]
[15]
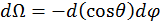 [16]
[16]
Thus Θ has a cosine weighting. This algorithm can then be used by following these steps:
Generate 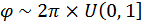 [17]
[17]
Generate 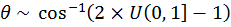 [18]
[18]
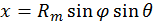 [19]
[19]
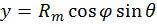 [20]
[20]
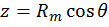 [21]
[21]
Computationally, 2π can be predefined as a constant, and thus does not require a multiplication every time it is used.
(ii) Normal-Deviate Method
As explained by Knuth, each x, y and z coordinate is randomly generated from a normal distribution with a mean of 0 and variance of 1. The result is normalised to the surface of the sphere to obtain a uniform distribution on the surface. The following equations describe this method, where λis the normalisation factor:
Let u, v, w ~ N(0,1), λ = Rm / sqrt(u2+v2+w2) [22]
x = uλ, y = vλ, z = wλ [23]
It should be noted that the generation of normally distributed random numbers requires an element of rejection, and thus generating normal random numbers takes significantly longer than generating uniform random numbers.
(iii) Hypercube rejection method
Similar to the normal-deviate method, but each ordinate is uniformly randomly distributed on [-1, 1] (calculated as 2 x U(0,1]-1). Compute the square root of the sum of squares, and if this value is greater than 1, the triplet is rejected. If this value is below 1, the vector is normalised and scaled to Rm.
Generate u, v, w ~ 2 * U(0,1] - 1 [24]
Let s2 = u2 + v2 + w2; if s>1, reject, else λ = Rm/s [25]
x = uλ, y = vλ, z = wλ [26]
As this method requires comparison and rejection, the chance of a triplet being inside the sphere as required is governed by the areas of a cube and sphere, such that 6/3.141 ≈ 1.910 triplets are required to achieve one which passes comparison.
(iv) Trigonometric method
This method is based on the fact that particles will be uniformly distributed on the sphere in one axis. The proof of this has been published in peer reviewed journals. The uniform direction, in this case Z, is randomly generated on [-Rm, Rm] to find the circle cross section at that point. The particle is then distributed at a random angle on the XY plane due to the constraint in Z.
Generate z ~ 2 x Rm x U(0,1] - Rm [27]
Generate α ~ 2π x U(0,1] [28]
Let r = sqrt(Rm2 – z2) [29]
x = r cos(α) [30]
y = r sin(α) [31]
(v) Two-Dimensional rejection method
By combining methods (iii) and (iv), a form of the trigonometric method can be devised without the use of trigonometric functions. Two random numbers are uniformly distributed along [-1, 1]. If the sum of squares of the two numbers is greater than 1, reject the doublet. If accepted, the ordinates are calculated based on the proof that points in a single axis are uniformly distributed:
Generate u, v ~ 2 x U(0,1] - 1 [32]
Let s = u2 + v2; if s > 1, reject. [33]
Let a = 2 x sqrt(1-s); k = a x Rm [34]
x = ku, y = kv, z = (2s-1)Rm [35]
Use of this method over the trigonometric method described in (iii) is dependent on whether the trigonometric functions of the system are slower than the combined speed of rejection and regeneration of the random numbers.
(vi) Bipyramidal Method
For completeness, the bipyramidal diffusion modelis also included. This method generates a random whole number between 0 and 5 inclusive, which dictates a movement in an axis, either positive or negative relative to the starting position. As a result, the one-dimensional representation of the random-walk, as shown in Figure 3, is played out in each of the three dimensions, and any particles that would have ended up outside the bipyramid from methods (i-v) would now be inside the pyramid.
The method for bipyramidal diffusion is shown below:
Generate 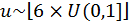 where
where 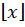 is the floor function
is the floor function
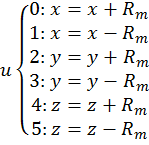 [36]
[36]
This method is technically the computationally least expensive in terms of mathematical functions, but due to equation [36], requires a lot of ‘if’ type comparison statements and the speed of these will determine how fast the algorithm is.
Results
The Brownian motion tests are something I have been doing with motherboard reviews for over twelve months in the form of my 3DPM (Three-Dimensional Particle Movement) test in both single threaded and multithreaded form. The simulation generates a number of particles, iterates them through a number of steps, and then checks the time to see if 10 seconds have passed. If the 10 seconds are not up, it goes through another loop. Results are then expressed in the form of million particle movements per second.
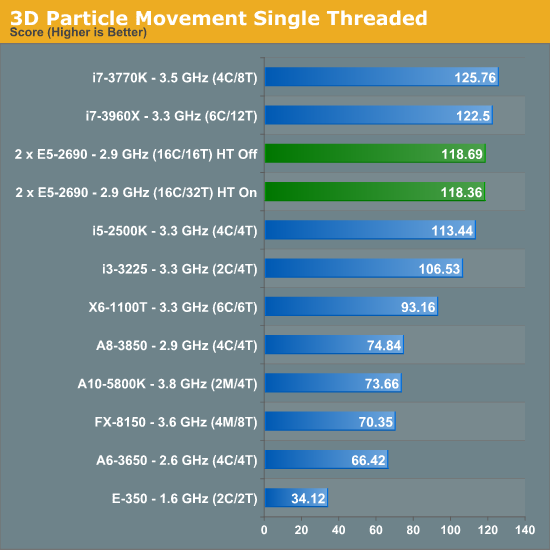
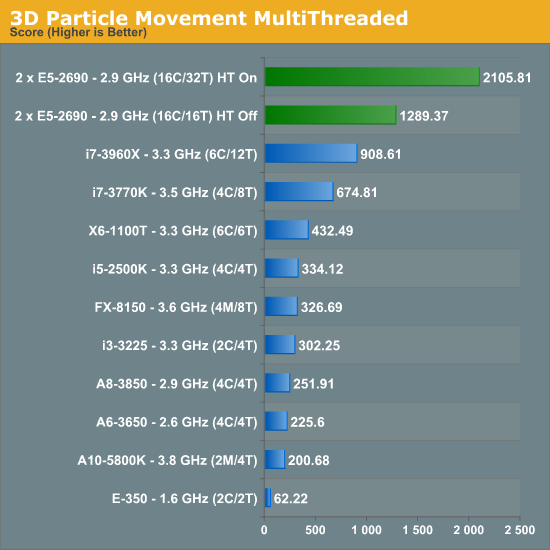
Due to the nature of the simulation, absolutely no memory access are needed during computation - there is a small element at the end for addition. This makes the DP system excellent for this type of work. Perhaps unsurprisingly we see no change in our single threaded version with HyperThreading on or off. However with the multithreaded version, HyperThreading gets a massive 63.3% boost.
Abusing GPUs
Back when I was researching these methods and implementing them on GPUs, for method (iv), the fastest method, the following results were achieved:
Athlon X2 5050e, 2.6 GHz (2C/2T): 32.38
Dual Xeon E5520, 2.23 GHz (8C/16T): 230.63
NVIDIA Quadro 580, 32 CUDA Cores: 1041.80
NVIDIA GTX 460, 336 CUDA Cores: 13602.94
When the simulation is embarrassingly parallel like this one, GPUs make a lot of difference. I recently rewrote method (iv) in C++ AMP and ran it on a i7-3770K at stock with a HD7970 also at stock, paired with 2400 C9 memory. It gave a result of 73654.32.








64 Comments
View All Comments
JonnyDough - Tuesday, January 8, 2013 - link
I don't know if I speak for everyone, but I would really love to see some gaming benchmarks.I realize that this system is not designed or optimized for gaming, but it would be interesting nonetheless to see what two processors does, or does not do for gaming. :)
npcomplete - Tuesday, January 8, 2013 - link
...it just gets to the meat of computing!Thanks for this article. It woke up the scientist in me.
esung - Wednesday, January 9, 2013 - link
I'm very curious as the result. Have you tried to bench 1 2690 vs 2 2690s? It almost like the benchmark are limited by CPU frequency instead of threads/cores it has.CodeToad - Saturday, January 19, 2013 - link
Ian - I really enjoyed reading your effort here. There is a large, and I think underserved, community of scientific users who need this kind of information. Digging through IEEE/ASM communications is often just too much. Doing the work here - or anywhere - is a real help.I'm a retired economist (PhD Chicago, '81) and (in my case) thankfully haven't done physical, much less computational, chemistry since undergrad. Never the less, we have similar technical needs.
I've become a huge fan of open source software. In my "home lab," which my wife calls The Frat House, some grad students and I have been diligently working with the R Language (statistics), nascent risk and optimization tools, and a mash-up of database, data warehouse, and "business intelligence" tools, all open source. The goal someday -- beat SAS silly and obviate that $100-300K price tag!
The more demure and do-able daily work is just cleaning up and optimizing open source code, contributing that back as individual packages. The "hits" and email indicates a good adoption rate.
Ian, CUDA is of big interest to the people we're in communication with, and I have to admit some real fascination personally. As you have real-world experience, how about a series of articles. I hope ANDATECH would support that work!!
Very best to you - hope to be "reading" you soon!!