Memory Performance: 16GB DDR3-1333 to DDR3-2400 on Ivy Bridge IGP with G.Skill
by Ian Cutress on October 18, 2012 12:00 PM EST- Posted in
- Memory
- G.Skill
- Ivy Bridge
- DDR3
Portal 2
A stalwart of the Source engine, Portal 2 is the big hit of 2011 following on from the original award-winning Portal. In our testing suite, Portal 2 performance should be indicative of CS:GO performance to a certain extent. Here we test Portal 2 at 1920x1080 with High/Very High graphical settings.
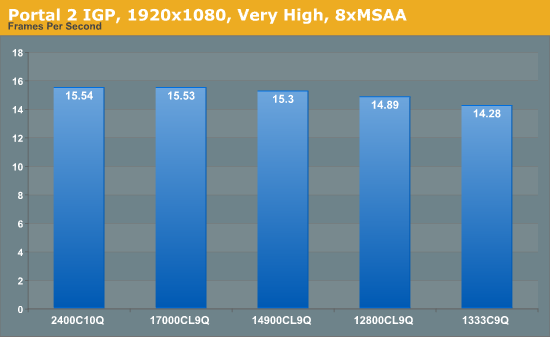
Portal 2 mirrors previous testing, albeit our frame rate increases as a percentage are not that great – 1333 to 1600 is a 4.3% increase, but 1333 to 2400 is only an 8.8% increase.
Batman Arkham Asylum
Made in 2009, Batman:AA uses the Unreal Engine 3 to create what was called “the Most Critically Acclaimed Superhero Game Ever”, awarded in the Guinness World Record books with an average score of 91.67 from reviewers. The game boasts several awards including a BAFTA. Here we use the in-game benchmark while at the lowest specification settings without PhysX at 1920x1080. Results are reported to the nearest FPS, and as such we take 4 runs and take the average value of the final three, as the first result is sometimes +33% more than normal.
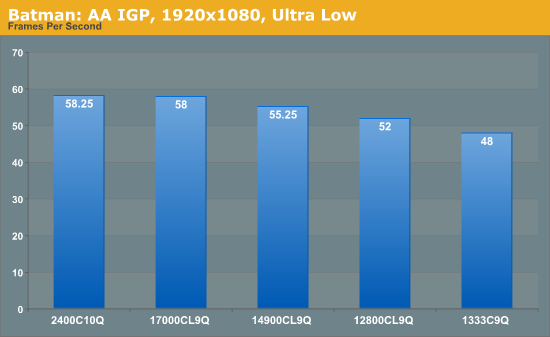
Batman: AA represents some of the best increases of any application in our testing. Jumps from 1333 C9 to 1600 C9 and 1866 C9 gives an 8% then another 7% boost, ending with a 21% increase in frame rates moving from 1333 C9 to 2400 C10.
Overall IGP Results
Taking all our IGP results gives us the following graph:
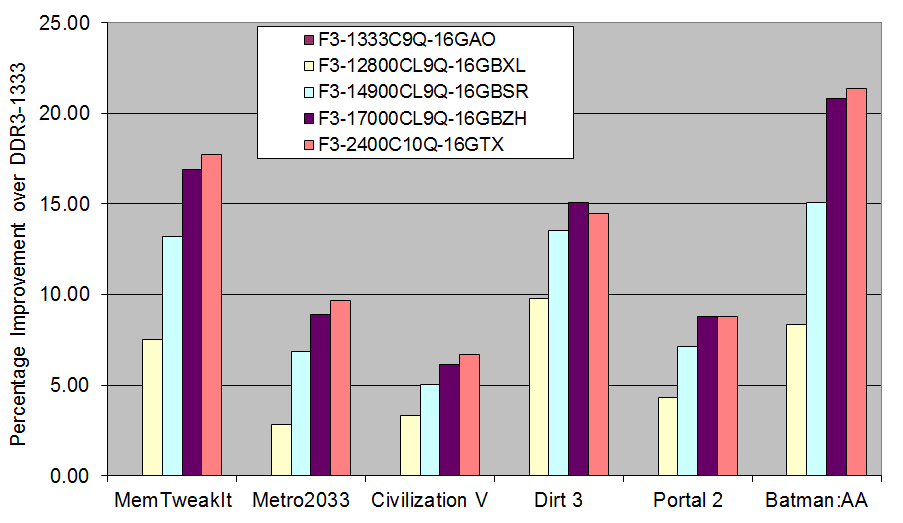
The only game that beats the MemTweakIt predictions is Batman: AA, but most games follow the similar shape of increases just scaled differently. Bearing in mind the price differences between the kits, if IGP is your goal then either the 1600 C9 or 1866 C9 seem best in terms of bang-for-buck, but 2133 C9 will provide extra performance if the budget stretches that far.








114 Comments
View All Comments
frozentundra123456 - Thursday, October 18, 2012 - link
While interesting from a theoretical standpoint. I would have been more interested in a comparison in laptops using HD4000 vs A10 to see if one is more dependent on fast memory than others. To be blunt, I dont really care much about the IGP on a 3770K. It would have been a more interesting comparison in laptops where the igp might actually be used for gaming. I guess maybe it would have been more difficult to do with changing memory around so much in a laptop though.The other thing is I would have liked to see the difference in games at playable frame rates. Does it really matter if you get 5.5 or 5.9 fps? It is a slideshow anyway. My interest is if using higher speed memory could have moved a game from unplayable to playable at a particular setting or allowed moving up to higher settings in a game that was playable.
mmonnin03 - Thursday, October 18, 2012 - link
RAM by definition is Random Access which means no matter where the data is on the module the access time is the same. It doesn't matter if two bytes are on the same row or on a different bank or on a different chip on the module, the access time is the same. There is no sequential or random difference with RAM. The only difference between the different rated sticks are short/long reads, not random or sequential and any reference to random/sequential reads should be removed.Olaf van der Spek - Thursday, October 18, 2012 - link
You're joking right? :pmmonnin03 - Thursday, October 18, 2012 - link
Well if the next commenter below says their memory knowledge went up by 10x they probably believe RAM reads are different depending on whether they are random or sequential.nafhan - Thursday, October 18, 2012 - link
"Random access" means that data can be accessed randomly as opposed to just sequentially. That's it. The term is a relic of an era where sequential storage was the norm.Hard drives and CD's are both random access devices, and they are both much faster on sequential reads. An example of sequential storage would be a tape backup drive.
mmonnin03 - Thursday, October 18, 2012 - link
RAM is direct access, no sequential or randomness about it. Access time is the same anywhere on the module.XX reads the same as
X
X
Where X is a piece of data and they are laid out in columns/rows.
Both are separate commands and incure the same latencies.
extide - Thursday, October 18, 2012 - link
No, you are wrong. Period. nafhan's post is correct.menting - Thursday, October 18, 2012 - link
no, mmonnin03 is more correct.DRAM has the same latency (relatively speaking.. it's faster by a little for the bits closer to the address decoder) for anywhere in the memory, as defined by the tAA spec for reads. For writes it's not as easy to determine since it's internal, but can be guessed from the tRC spec.
The only time that DRAM reads can be faster for consecutive reads, and considered "sequential" is if you open a row, and continue to read all the columns in that row before precharging, because the command would be Activate, Read, Read, Read .... Read, Precharge, whereas a "random access" will most likely be Activate, Read, Precharge most of the time.
The article is misleading, using "sequential reads" in the article. There is really no "sequential", because depending if you are sequential in row, column, or bank, you get totally different results.
jwilliams4200 - Thursday, October 18, 2012 - link
I say mmonnin03 is precisely wrong when he claims that " no matter where the data is on the module the access time is the same".The read latency can vary by about a factor of 3 times whether the read is from an already open row, or whether the desired read comes from a different row than one already open.
That makes a big difference in total read time, especially if you are reading all the bytes in a page.
menting - Friday, October 19, 2012 - link
no. he is correct.if every read has the conditions set up equally (ie the parameters are the same, only the address is not), then the access time is the same.
so if address A is from a row that is already open, the time to read that address is the same as address B, if B from a row that is already open
you cannot have a valid comparison if you don't keep the conditions the same between 2 addresses. It's almost like saying the latency is different between 2 reads because they were measured at different PVT corners.