SandForce TRIM Issue & Corsair Force Series GS (240GB) Review
by Kristian Vättö on November 22, 2012 1:00 PM ESTRandom Read/Write Speed
The four corners of SSD performance are as follows: random read, random write, sequential read and sequential write speed. Random accesses are generally small in size, while sequential accesses tend to be larger and thus we have the four Iometer tests we use in all of our reviews. Our first test writes 4KB in a completely random pattern over an 8GB space of the drive to simulate the sort of random access that you'd see on an OS drive (even this is more stressful than a normal desktop user would see).
We perform three concurrent IOs and run the test for 3 minutes. The results reported are in average MB/s over the entire time. We use both standard pseudo randomly generated data for each write as well as fully random data to show you both the maximum and minimum performance offered by SandForce based drives in these tests. The average performance of SF drives will likely be somewhere in between the two values for each drive you see in the graphs. For an understanding of why this matters, read our original SandForce article.
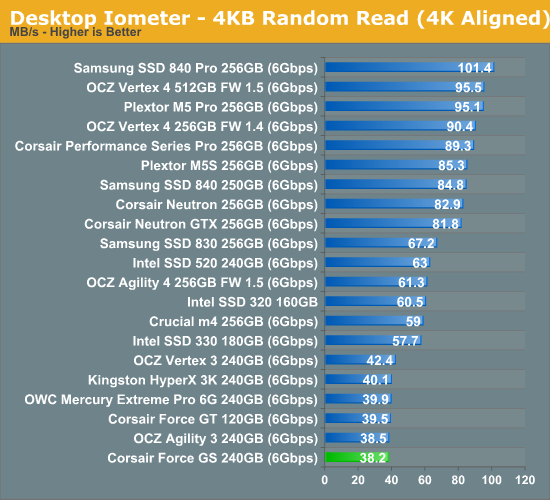
Random read speed has never been SandForce's strength and the Force GS is no exception. Real-time compression doesn't provide much benefit to read performance because reading from NAND has always been much faster than programming. Presumably SandForce's third generation controllers (SF-3000) will address random read and write performance, although it's way too early to tell how big of improvements we should expect.
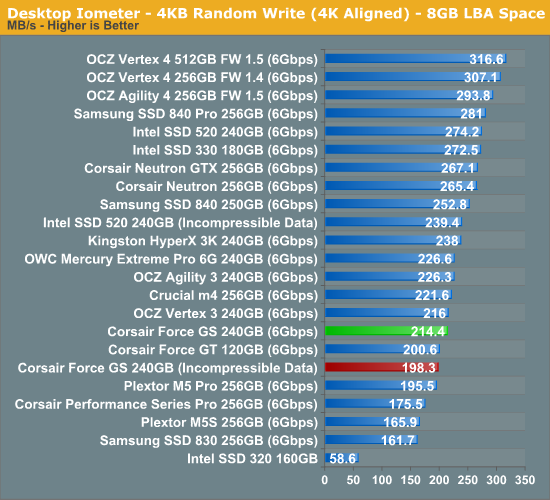
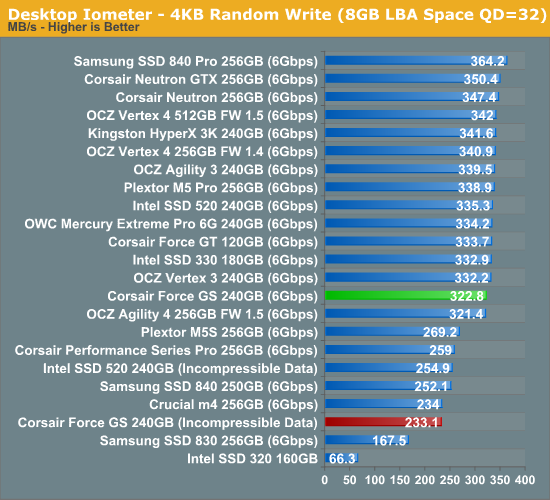
Random write performance is exceptionally low. At queue depth of 3 (the first random write graph), the Force GS manages to stay roughly on-par with other SF-2281 based SSDs, but at queue depth of 32 there is a more noticeable difference. While we are only talking about a difference of a few percents, it's still surprising that the Force GT doesn't achieve speeds similar to other SF-2281 SSDs.
Sequential Read/Write Speed
To measure sequential performance we ran a one minute long 128KB sequential test over the entire span of the drive at a queue depth of 1. The results reported are in average MB/s over the entire test length.
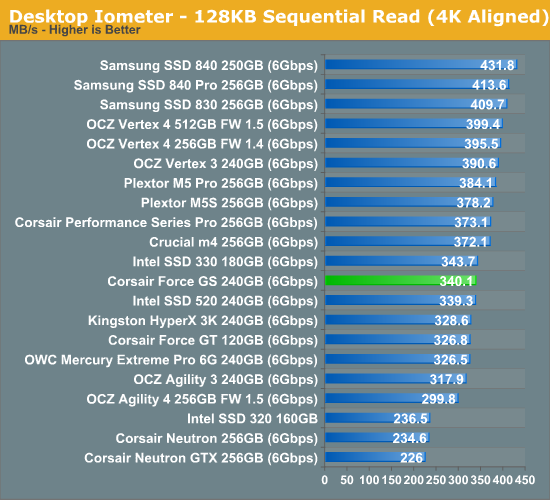

Sequential performance is typical SandForce. With highly compressible data, SandForce SSDs are still the fastest in sequential write speed, although OCZ Vertex 4 is getting very close.








56 Comments
View All Comments
FunnyTrace - Wednesday, November 28, 2012 - link
Yes, I did read an article on Tweaktown about this in August 2012.JellyRoll - Friday, November 23, 2012 - link
OMG...SandForce does not do dedupe (deduplication). It does not "has to check if the data is used by something else."!!The drive is unaware of the actual file usage above the device level. That is a host level responsibility.
I cannot believe that this article was not vetted before it was posted.
Kristian Vättö - Friday, November 23, 2012 - link
SandForce does deduplication at the device level. It doesn't look for actual files like the host does because it's all ones and zeros for the controller. However, what it does is look for similar data patterns.For example, if you have two very similar photos which are 5MB each, the controller may not write 10MB. Instead, it will only write let's say 8MB to the NAND because some of the data is duplicate and the whole idea of deduplication is to minimize NAND writes.
If you go and delete one of these photos, the OS sends a TRIM command that tells the LBA is no longer in use and it can be deleted. What makes SandForce more complicated is the fact that the photos don't necessarily have their own LBAs, so what you need to do is to check that the LBA you're about to erase is not mapped to any other LBA. Otherwise you might end up erasing a portion of the other photo as well.
JellyRoll - Friday, November 23, 2012 - link
I challenge you to offer one document that supports your assertion that sandforce does deduplication. There ins't any, as it does not. Feel free to link to the technical document to support your claims in your reply.SandForce supports compression, not deduplication.
Here is a link to documentation and product data sheets.
http://www.lsi.com/products/storagecomponents/Page...
Kristian Vättö - Friday, November 23, 2012 - link
SandForce/LSI has published very little about the technology behind DuraWrite and how it works, but a combination of technologies including compression and deduplication is what they have told us.http://www.anandtech.com/show/2899/3
JellyRoll - Friday, November 23, 2012 - link
Linking an Anandtech article is not proof that SandForce does deduplication. A quick Google will reveal that there is no other source, outside of Anandtech, that claims that they offer deduplication on the current series of processors.As a matter of fact, that article is the only other reference to deduplication and SandForce that can be found.
There was a mistake made in that article.
JellyRoll - Friday, November 23, 2012 - link
As a matter of fact, if deduplication were to apply to the SandForce series of processors then incompressible data would also experience decreases in write amplification. SandForce is very public that they have "top follow the same rules" with incompressible data as everyone else. IE, they suffer the same amount of write amplification.Since SandForce controllers only exhibit performance enhancing and endurance increasing benefits from compressible data, that alone indicates that deduplication is not in use.
Deduplication can be applied regardless of the compressibility of the data.
extide - Saturday, November 24, 2012 - link
Incompressible data generally doesnt have duplications in it... that's kinda what makes it incompressible... I mean the whole POINT of compression is removing duplications!JellyRoll - Saturday, November 24, 2012 - link
If you have two matching sets of data, be they incompressible or not, they would be subject to deduplicatioin. It would merely require mapping to the same LBA addresses.For instance, if you have two files that consist of largely incompressible data, but they are still carbon copies of each, they are still subject to data deduplication.
extide - Wednesday, November 28, 2012 - link
That could also be considered compression. Take 2 copies of the same MP3 file and put them into a zip file, how big is the zip file? Pretty close to the size of one copy...