The AMD Trinity Review (A10-4600M): A New Hope
by Jarred Walton on May 15, 2012 12:00 AM ESTImproved Turbo
Trinity features a much improved version of AMD's Turbo Core technology compared to Llano. First and foremost, both CPU and GPU turbo are now supported. In Llano only the CPU cores could turbo up if there was additional TDP headroom available, while the GPU cores ran no higher than their max specified frequency. In Trinity, if the CPU cores aren't using all of their allocated TDP but the GPU is under heavy load, it can exceed its typical max frequency to capitalize on the available TDP. The same obviously works in reverse.
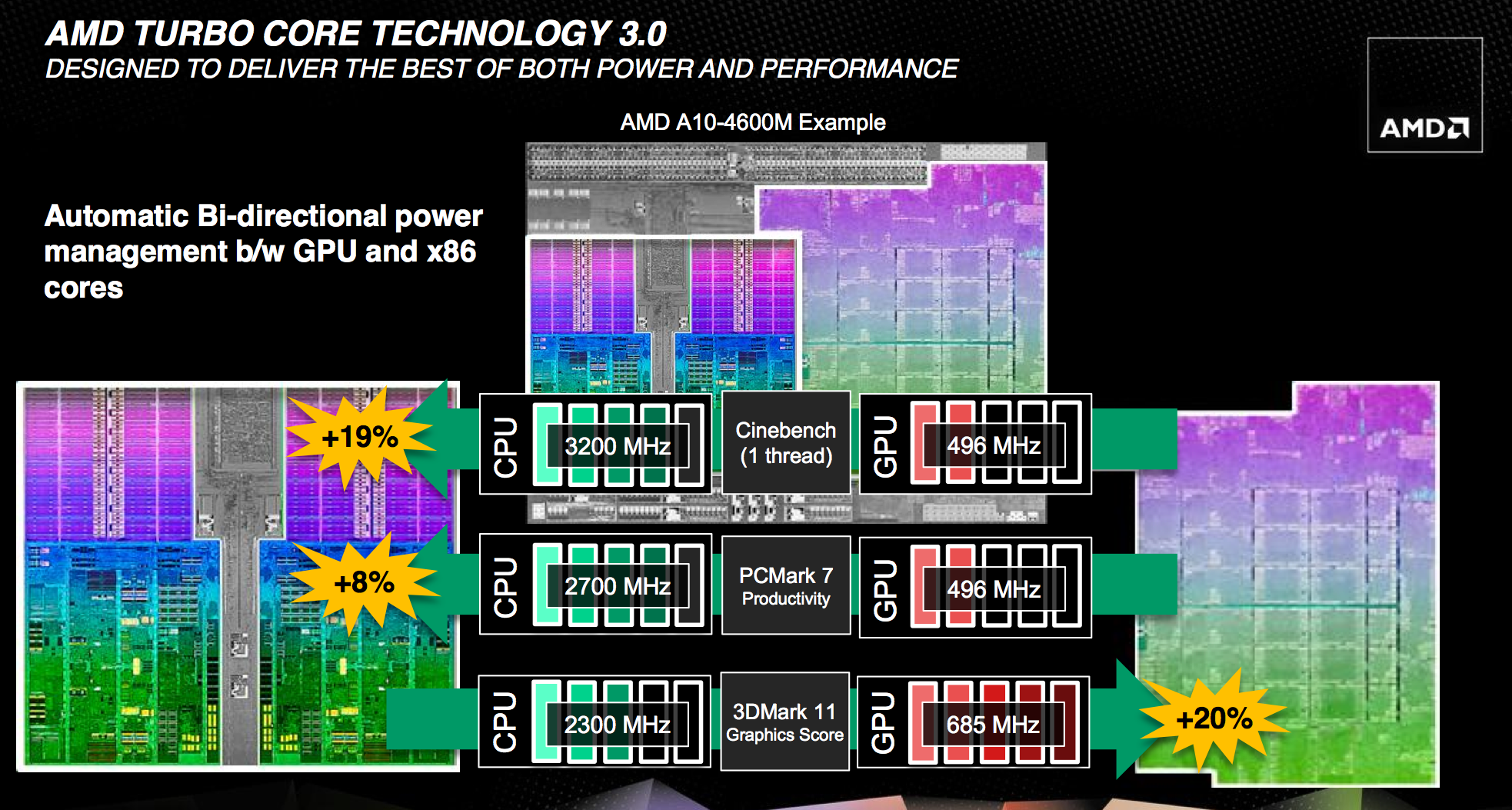
Under the hood, the microcontroller that monitors all power consumption within the APU is much more capable. In Llano, the Turbo Core microcontroller looked at activity on the CPU/GPU and performed a static allocation of power based on this data. In Trinity, AMD implemented a physics based thermal calculation model using fast transforms. The model takes power and translates it into a dynamic temperature calculation. Power is still estimated based on workload, which AMD claims has less than a 1% error rate, but the new model gets accurate temperatures from those estimations. The thermal model delivers accuracy at or below 2C, in real time. Having more accurate thermal data allows the turbo microcontroller to respond quicker, which should allow for frequencies to scale up and down more effectively.
At the end of the day this should improve performance, although it's difficult to compare directly to Llano since so much has changed between the two APUs. Just as with Llano, AMD specifies nominal and max turbo frequencies for the Trinity CPU/GPU.
A Beefy Set of Interconnects
The holy grail for AMD (and Intel for that matter) is a single piece of silicon with CPU and GPU style cores that coexist harmoniously, each doing what they do best. We're not quite there yet, but in pursuit of that goal it's important to have tons of bandwidth available on chip.
Trinity still features two 64-bit DDR3 memory controllers with support for up to DDR3-1866 speeds. The controllers add support for 1.25V memory. Notebook bound Trinities (Socket FS1r2 and Socket FP2) support up to 32GB of memory, while the desktop variants (Socket FM2) can handle up to 64GB.
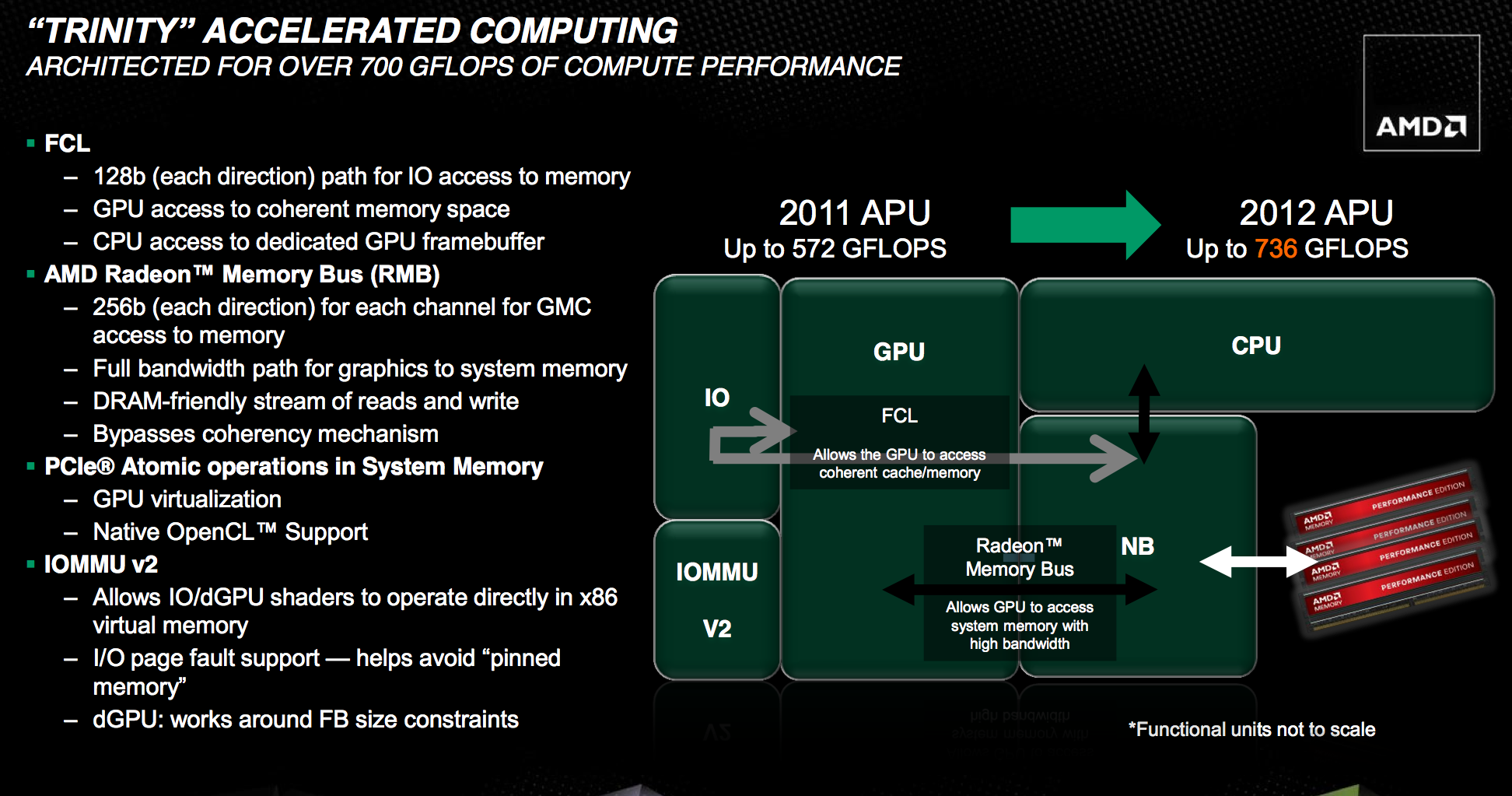
Hyper Transport is gone as an external interconnect, leaving only PCIe for off-chip IO. The Fusion Control Link is a 128-bit (each direction) interface giving off-chip IO devices access to system memory. Trinity also features a 256-bit (in each direction, per memory channel) Radeon Memory Bus (RMB) direct access to the DRAM controllers. The excessive width of this bus likely implies that it's also used for CPU/GPU communication as well.
IOMMU v2 is also supported by Trinity, giving supported discrete GPUs (e.g. Tahiti) access to the CPU's virtual memory. In Llano, you used to take data from disk, copy it to memory, then copy it from the CPU's address space to pinned memory that's accessible by the GPU, then the GPU gets it and brings it into its frame buffer. By having access to the CPU's virtual address space now the data goes from disk, to memory, then directly to the GPU's memory—you skip that intermediate mem to mem copy. Eventually we'll get to the point where there's truly one unified address space, but steps like these are what will get us there.
The Trinity GPU
Trinity's GPU is probably the most well understood part of the chip, seeing as how its basically a cut down Cayman from AMD's Northern Islands family. The VLIW4 design features 6 SIMD engines, each with 16 VLIW4 arrays, for a total of up to 384 cores. The A10 SKUs get 384 cores while the lower end A8 and A6 parts get 256 and 192, respectively. FP64 is supported but at 1/16 the FP32 rate.
As AMD never released any low-end Northern Islands VLIW4 parts, Trinity's GPU is a bit unique. It technically has fewer cores than Llano's GPU, but as we saw with AMD's transition from VLIW5 to VLIW4, the loss didn't really impact performance but rather drove up efficiency. Remember that most of the time that 5th unit in AMD's VLIW5 architectures went unused.
The design features 24 texture units and 8 ROPs, in line with what you'd expect from what's effectively 1/4 of a Cayman/Radeon HD 6970. Clock speeds are obviously lower than a full blown Cayman, but not by a ton. Trinity's GPU runs at a normal maximum of 497MHz and can turbo up as high as 686MHz.
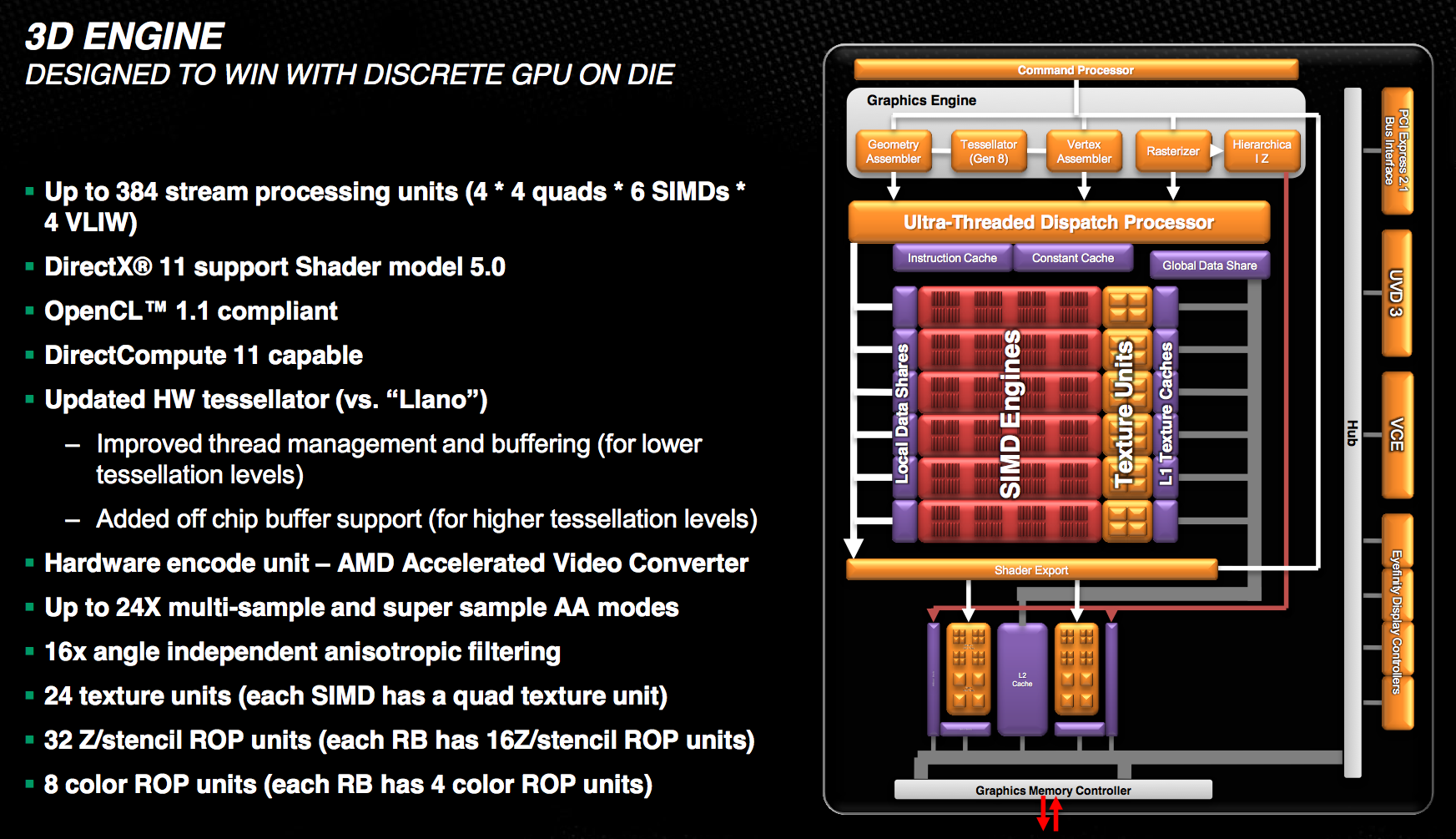

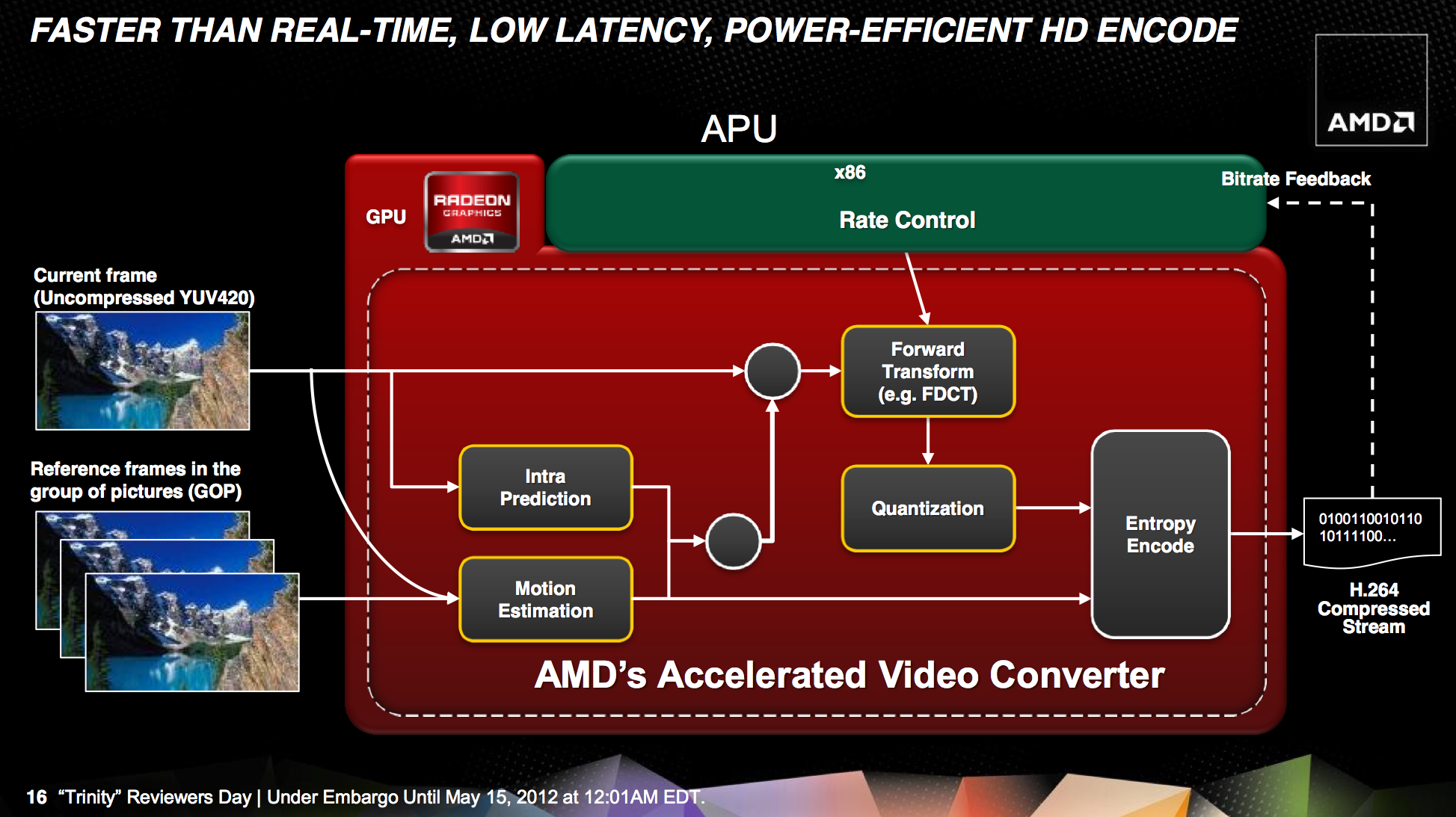
Trinity includes AMD's HD Media Accelerator, which includes accelerated video decode (UVD3) and encode components (VCE). Trinity borrows Graphics Core Next's Video Codec Engine (VCE) and is actually functional in the hardware/software we have here today. Don't get too excited though; the VCE enabled software we have today won't take advantage of the identical hardware in discrete GCN GPUs. AMD tells us this is purely a matter of having the resources to prioritize Trinity first, and that discrete GPU VCE support is coming.








271 Comments
View All Comments
mdeo - Tuesday, May 15, 2012 - link
" For some of these applications, we don’t have any good way of measuring performance across a wide selection of hardware, and for some of those where benchmarks are possible I’ve run out of time to try to put anything concrete together"Please wait and spend the required time before you post results.
Also, where are the graphs for WinZip, GIMP filters (19 of them ..you deemed 5 that you would use). Graphs make it easy to read that Trinity beats Intel chips in GIMP and equals in WinZip.
This makes me wonder why should I trust Anandtech more then tomshardware reviews ...
JarredWalton - Tuesday, May 15, 2012 - link
You apparently have no idea how much time goes into putting together a review and running all the benchmarks. Let's just say that after running (and rerunning) benchmarks for much of the last month on a variety of laptops, I finished a couple of graphs right at the 12:01 AM NDA time. That was after getting about ten hours of sleep total over the weekend, and never mind the fact that I've had a horrible cold the past week.Every new benchmark needs to be created and evaluated to see if it's useful. GIMP's new "Noise Reduction" and "Blur" functions can use OpenCL, but so can "Checkerboard". Um, really? We need OpenCL to fill an image with a checkerboard?
Here are a few GIMP numbers (from Noise Reduction):
A10 CPU: .396 MP/s
A10 OCL: 4.10 MP/s
IVB CPU: 1.49 MP/s
IVB OCL: 4.04 MP/s
SNB CPU: .689 MP/s
SNB OCL: 3.56 MP/s
DC SNB CPU: .586 MP/s
DC SNB OCL: 2.01 MP/s
Llano CPU: .321 MP/s
Llano OCL: 2.39 MP/s
I had a graph for WinZip, but then we pulled it because apparently WinZip's OpenCL performance is best using the legacy compression. I used their newer Zipx compression, which results in a smaller file but isn't as optimized (yet). So now I need to spend about two hours retesting WinZip and 7-zip. Thanks for understanding.
Beenthere - Tuesday, May 15, 2012 - link
As expected Trinity delivers in all areas and should meet most people's needs quite well. Good job AMD. You get my money!tipoo - Tuesday, May 15, 2012 - link
I wonder what causes these odd results? The 7660 winning by a wide margin in most games, but losing by a small margin in some? Is it whether the games are pixel fill vs pixel shader (hd4000 is good at the former, bad at the latter) bound, or is there a driver issue with the 4000, or what?Wolfpup - Tuesday, May 15, 2012 - link
That has to be the most surprising thing in the review to me. While I know technically today's GPUs are really CPUs geared towards less branchy, more parallel code, it still caught me off guard that someone had thought to run a file compression utility on it!Also surprised Intel has OpenCL drivers at all...not surprised they're bad though. I wonder what they do? Like is their "GPU" portion of Sandy/Ivy bridge actually capable of doing that type of work, or are they mostly just using the CPU?
Still hate "quicksync" and the graphics portion of those CPUs as it's wasting at least enough transistors for a 5th core.
jwcalla - Tuesday, May 15, 2012 - link
File compression can be parallelized, but there are some unfortunate limitations... final compressed size is generally less optimal with parallel compression, and compressing large volumes of data become memory-bound fairly quickly. But for "ordinary" compression tasks it's quite effective.The article didn't indicate if the CPU compression tests were single-threaded or multi-threaded.
Brazos - Tuesday, May 15, 2012 - link
Can I assume the improvements seen here will be implemented in the next version of Bulldozer (Vishera)?mikato - Wednesday, May 16, 2012 - link
Yes, it's supposed to use Piledriver modules, not Bulldozer.silverblue - Thursday, May 17, 2012 - link
Plus even the Piledriver implementation in Trinity should, clock for clock, be faster than Bulldozer even without L3 cache. This isn't a repeat of Llano vs. Phenom II where Husky cores were technically faster than Stars albeit lacked L3 cache which brought the performance back down again.Some information about the caches plus their latency would be really appreciated; if it bodes well here, Vishera might be a very decent chip.
jwcalla - Tuesday, May 15, 2012 - link
Is there really a large market for gaming on a lower-end laptop? I can see us techies being interested in that sort of thing, but what percentage of PC buyers is actually concerned about gaming performance, let alone on a laptop? In real world terms, I'm not seeing AMD's strategy giving it much of an advantage.I'm willing to entertain the reality that Intel has been "overselling performance" to casual users for some time now, and so maybe low-end is more than good enough... but, if true, AMD seems to be focusing on a segment that is going to have an enormous amount of competition in the next 2-3 years.