Bulldozer for Servers: Testing AMD's "Interlagos" Opteron 6200 Series
by Johan De Gelas on November 15, 2011 5:09 PM ESTConclusions
To help summarize the current situation in the server CPU market, we have drawn up a comparison table of the performance we have measured so far. We'll compare the new Interlagos Opteron 6276 against the outgoing Opteron 6174 as well as teh Xeon X5650.
|
Opteron 6276 vs. Opteron 6174 |
Opteron 6276 vs. Xeon X5650 |
|
| ESXi + Linux | -1% | -2% |
| ESXi + Windows | = | +3% |
| Cinebench | +2% | +9% |
| 3DS Max 2012 (iRay) | -9% to + 4% | -10% to +3% |
| Maxwell Render | +4% | +6% |
| Blender | -4% | -24% |
| Encryption/Decryption AES | +265% / +275% | +2% / +7% |
| Encryption/Decryption Twofish/Serpent | +25% / +25% | 31% / 46% |
| Compression/decompression | +10% / +10% | -33%/ +22% |
Let us first discuss the virtualization scene, the most important market. Unfortunately, with the current power management in ESXi, we are not satisfied with the Performance/watt ratio of the Opteron 6276. The Xeon needs up to 25% less energy and performs slightly better. So if performance/watt is your first priority, we think the current Xeons are your best option.
The Opteron 6276 offers a better performance per dollar ratio. It delivers the performance of $1000 Xeon (X5650) at $800. Add to this that the G34 based servers are typically less expensive than their Intel LGA 1366 counterparts and the price bonus for the new Opteron grows. If performance/dollar is your first priority, we think the Opteron 6276 is an attractive alternative.
And then there is Windows Server 2008 R2. Typically we found that under heavy load (benchmarking at 85-100% CPU load) the power consumption was between 3% (integer) to 7% (FP) higher on the Opteron 6276 than on the Xeons and Opteron 6100, a lot better than under ESXi. Add to this the fact that the new Opteron energy usage at low load is excellent and you understand that we feel that there is no reason to go for the Opteron 6100 anymore. Again, AMD still understands that it should price its CPUs more attractive than the competition, so from the price/performance/watt point of view, the Opteron 6276 is a good cost effective alternative to the Xeon...on the condition that you enable the "high performance" policy and that AMD keeps the price delta the same in the coming months.
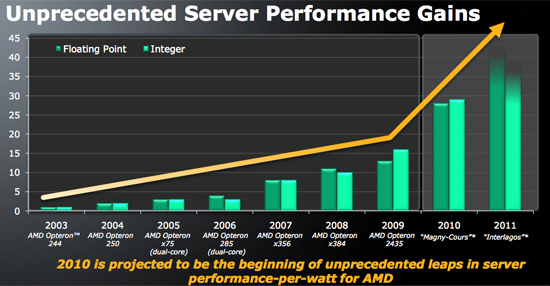
That is the good news. We cannot help but to feel a bit disappointed too. AMD promised us (in 2009/2010) that the Opteron 6200 would be significantly faster than the 6100: "unprecedented server performance gains". That is somewhat the case if you recompile your software with the latest and greatest optimized compiler as AMD's own SPEC CINT (+19%), CFP 2006 (+11%) and Linpack benchmarks (+32%) show.
One of the real advantages of a new processor architecture (prime examples where the K7 and K8) is if it performs well in older software too, without requiring a recompile. For some people of the HPC world, recompiling is acceptable and common, but for everybody else (that is probably >95% of the market!), it's best if existing binaries run faster. Administrators generally are not going to upgrade and recompile their software just to make better use of a new server CPU. Hopefully AMD's engineers have been looking into improving the legacy software performance of their latest chip the last few months, because it could use some help.
On the other side of the coin, it is clear that some of the excellent features of the new Opteron are not leveraged by the current software base. The deeper sleep and more advanced core gating is not working to its full potential, and the current operating systems frequently don't appear to know how to get the best from Turbo Core. The clock can be boosted by 39% when half of the cores are active, but an 18% boost was the best we saw (in a single-threaded app!). Simply turning the right knobs gave some tangible power savings (see ESXi) and some impressive performance improvements (see Windows Server 2008).
In short, we're going to need to do some additional testing and take this server out for another test drive, and we will. Stay tuned for a follow-up article as we investigate other options for improving performance.








{kind=link}
106 Comments
View All Comments
DigitalFreak - Tuesday, November 15, 2011 - link
Good to see that CPU-Z correctly reports the 6276 as 8 core, 16 thread, instead of falling for AMD's marketing BS.N4g4rok - Tuesday, November 15, 2011 - link
If each module possess two integer cores to a shared floating point core, what's to say that it can't be considered as a practical 16 core?phoenix_rizzen - Tuesday, November 15, 2011 - link
Each module includes 2x integer cores, correct. But the floating point core is "shared-separate", meaning it an be used as two separate 128-bit FPUs or as a single 256 FPU.Thus, each Bulldozer module can run either 3 or 4 threads simultaneously:
- 2x integer + 2x 128-bit FP threads, or
- 2x integer + 1x 256-bit FP threads
It's definitely a dual-core module. It's just that the number of threads it can run is flexible.
The thing to remember, though, is that these are separate hardware pipelines, not mickey-moused hyperthreaded pipelines.
JohanAnandtech - Tuesday, November 15, 2011 - link
You can get into a long discussion about that. The way that I see it, is that part of the core is "logical/virtual", the other part is real in Bulldozer . What is the difference between an SMT thread and CMT thread when they enter the fetch-decode stages? Nothing AFAIK, both instructions are interleaved, and they both have a "thread tag".The difference is when they are scheduled, the instructions enters a real core with only one context in the CMT Bulldozer. With SMT, the instructions enter a real core which still interleave two logical contexts. So the core still consists of two logical cores.
It is gets even more complicated when look at the FP "cores". AFAIK, the FP cores of Interlagos are nothing more than 8 SMT enabled cores.
alpha754293 - Tuesday, November 15, 2011 - link
I think that Johan is partially correct.The way I see it, the FPU on the Interlagos is this:
It's really a 256-bit wide FPU.
It can't really QUITE separate the ONE physical FPUs into two 128-bit wide FPUs, but it more probably in reality, interleaves them (which is really just code for "FPU-starved").
Intel's original HTT had this as a MAJOR problem, because the test back then can range from -30% to +30% performance increase. Floating-point intensive benchmarks have ALWAYS suffered mostly because suppose you're writing a calculator using ONLY 8-byte (64-bit) double precision.
NORMALLY, that should mean that you should be able to crunch through four DWORDs at the same time. And that's kinda/sorta true.
Now, if you are running two programs, really...I don't think that the CPU, the compiler (well..maybe), the OS, or the program knows that it needs to compile for 128-bit-wide FPUs if you're going to run two instances or two (different) calculators.
So it's resource starved in trying to do the calculation processes at the same time.
For non-FPU-heavy workloads, you can get away with that. For pretty much the entire scientific/math/engineering (SME) community; it's an 8-core processor or a highly crippled 16-core processor.
Intel's latest HTT seems to have addressed a lot of that, and in practical terms, you can see upwards of 30% performance advantage even with FPU-heavy workloads.
So in some cases, the definition of core depends on what you're going to be doing with it. For SME/HPC; it's good cuz it can do 12-actual-cores worth of work with 8 FPUs (33% more efficient), but sucks because unless they come out with a 32-thread/16-core monolithic die; as stated, it's only marginally better than the last. It's just cheaper. And going to get incrementally faster with higher clock speeds.
alpha754293 - Tuesday, November 15, 2011 - link
P.S. Also, like Anand's article about nVidia Optimus:Context switching even at the CPU level, while faster, is still costly. Perhaps maybe not nearly as costly as shuffling data around; but it's still pretty costly.
Samus - Wednesday, November 16, 2011 - link
Ouch, this is going to be AMD's Itanium. That is, it has architecture adoption problems that people simply won't build around. Maybe less substantial than IA64, but still a huge performance loss because of underutilized integer units.leexgx - Wednesday, November 16, 2011 - link
think they way CPU-z reporting it for BD cpus is correct each core has 2 FP, so 8 cores and 16 threads is correctto bad windows does not understand how to spread the load correctly on an amd cpu (windows 7 with HT cpus Intel works fine, spreads the load correctly, SP1 improves that more but for Intel cpus only)
windows 7 sp1 makes biger use of core parking and gives better cpu use on Intel cpus as i have been seeing on 3 systems most work loads now stay on the first 2 cores and the other 2 stay parked, on amd side its still broke with cool and quite enabled
Stuka87 - Tuesday, November 15, 2011 - link
So, what is your definition of a core?Bulldozers do not utilize hyper threading, which takes a single integer core and can at times put two threads into that single integer core. A Bulldozer core has actual hardware two run two threads at the same time. This would suggest there are two physical cores.
Does it perform like an intel 16 core (if there was such a thing), no. But that does not mean that it is not in fact a 16 core device. As the hardware is there. Yes they share an FPU, but that doesn't mean they are not cores.
Filiprino - Tuesday, November 15, 2011 - link
Actually, Bulldozer is 16 cores. It has two dedicated integer units and a float point unit which can act as two 128 bit units or one 256 bit unit for AVX. So, you can have 2 and 2 per module.Bulldozer does not use hyperthreading.