Rendering and HPC Benchmark Session Using Our Best Servers
by Johan De Gelas on September 30, 2011 12:00 AM ESTInvestigating the Opteron Performance Mystery
What really surprised us was the Opteron's abysmal performance in Stars Euler3D CFD. We did not believe the results and repeated the benchmark at least 10 times on the quad Opteron system. Let us delve a little deeper.
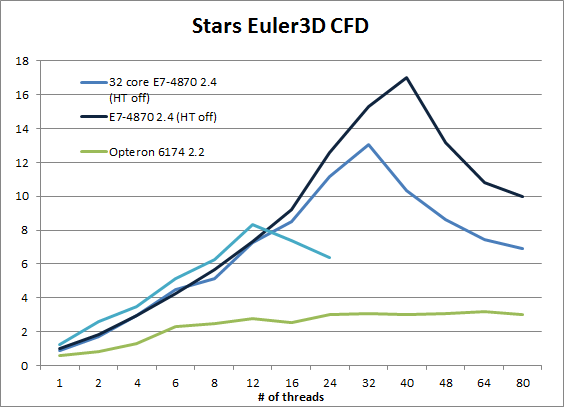
Notice that the Intel Xeons scale very well until the number of threads is higher than the physical core count. The performance of the 40 core E7-4870 only drops when we use 48 threads (with HT off). The Opteron however only scales reasonably well from 1 to 6 threads. Between 6 and 12 threads scaling is very mediocre, but at least performance increases. From there, the performance curve is essentially flat.
The Opteron Performance Remedy?
We contacted Charles of Caselab with our results. He gaves us a few clues:
1. The Euler3d CFD solver uses an unstructured grid (spider web appearance with fluid states stored at segment endpoints). Thus, adjacent physical locations do not (cannot!) map to adjacent memory locations.
2. The memory performance benchmark relevant to Euler3D appears to be the random memory recall rate and NOT the adjacent-memory-sweep bandwidth.
3. Typical memory tests (e.g. Stream) are sequential "block'' based. Euler3D effectively tests random access memory performance.
So sequential bandwidth is not the answer. In fact, in most "Streamish" benchmarks (including our own compiled binaries), the Quad Opteron was close to 100GB/s while the Quad Xeon E7 got only between 37 and 55GB/s. So far it seems that only the Intel compiled stream binaries are able to achieve more than 55GB/s. So we have a piece of FP intensive software that performs a lot of random memory accesses.
On the Opteron, performance starts to slow down when we use more than 12 threads. With 24 or even better 48 threads the application spawns more threads than the available cores within the local socket. This means that remote memory accesses cannot be avoided. Could it be that the performance is completely limited by the threads that have to go the furthest (2 hops)? In others words, some threads working on local memory finish much faster, but the whole test cannot complete until the slowest threads (working on remote memory) finish.
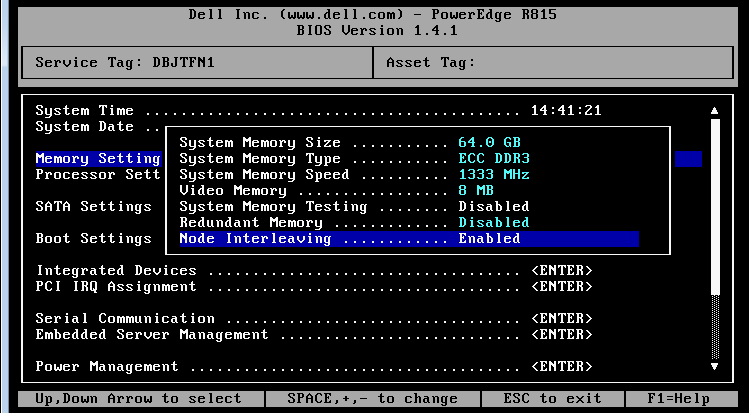
We decided to enable "Node Interleaving" in the BIOS of our Dell R815. This means that data is striped across all four memory controllers. Interleaved accesses are slower than local-only accesses because three out of four operations traverse the HT link. However, all threads should now experience a latency that is more or less the same. We prevent the the worst-case scenario where few threads are seeing 2-hop latency. Let us see if that helped.








52 Comments
View All Comments
MrSpadge - Friday, September 30, 2011 - link
Agreed - performance of a single i7 2600 can be hard to beat, depending on the application. My Matlab code uses all physical cores through the Intel Math Kernel Library, yet is ~30% slower on 2 x X5570 (wich is about the difference in clock speed, incidently).MrS
JohanAnandtech - Friday, September 30, 2011 - link
http://www.anandtech.com/show/4486/server-renderin...the core i970 3.2 GHz is included. But indeed, it has been some time since we have used backburner.
Is this the kind of bench you are looking for?
http://www.anandtech.com/show/2240/7
Backburner scales extremely well, so I suspect that especially the Quad MC Dell is a very good choice compared to a workstation.
JoeKan - Friday, September 30, 2011 - link
Yes - the backburner test is it. Although I use different rendering software, that test would be appropriate as the visualization rendering can properly represent real life usage and can stress the hardware at the same time.The test linked uses frames 20-29. I'd like to see a longer frame sequence.
The reason I asked that a workstation be used as a base reference is because that gives us, the readers, a point of reference to compare against. I define a workstation as a single CPU box anyone can build with off the shelf components, like a i7-2600K, or a i7-970 - a performance CPU in the $300+ to $600 range. That allows one to compare performance on a per $ basis.
Not a true 'workstation' as it does not use a Xeon, but it gives the ability to compare 'performance' to 'performance per buck' basis.
By using a $1000+ class CPU for comparison the 'bang for the buck' comparison is distorted.
xxtypersxx - Friday, September 30, 2011 - link
I love reading about the high end server hardware, its like F1 compared to road cars.As for benchmarks, may I suggest the linux x64 Folding at Home client? We know it scales past at least 128 cores without issue and as many of us that fold are running server hardware anyway, it will attract a new audience to the reviews.
rehm - Friday, September 30, 2011 - link
Hello,for CFD benchmarking you could also consider the code OpenFOAM. It scales very well and is gaining a lot of interest in industry and academia. Memory behaviour should be comparable to Fluent and it can be compiled with gcc and icc.
Regards
JohanAnandtech - Friday, September 30, 2011 - link
Very nice suggestion... but is there a sample solution/ benchmark we can measure? It is a bit hard for a hardware reviewer to come up with very specialized realworld tests :-).ozztheforester - Friday, September 30, 2011 - link
I am currently using a bunch of 2600k's for rendering in the past I used some dual xeon setups but only found those being extremely inefficient on cost/performance ratio. Can you please let us know the cost and power consumption of this system?currently getting around 8.72 points on cinebench 11.5 on a 2600k pc @4.5ghz which is consuming less than 200 watts at full load and costing a bit less than 800usd
also I would suggest using vray for multi thread benchmarks
sicofante - Friday, September 30, 2011 - link
Why didn't you set up a scene in Maya or Softimage and then render it with Mental Ray? THAT would be a professional test, Cinebench is not.BTW, no matter how powerful, these Xeon E7 systems are a no-go for studios. They are plainly anti-economical. You can have a much sensibler setup by putting ordinary Xeons or overclocked Core i7s in many racks, i.e., a rendering farm.
(Note: I build rendering farms for studios. Since 3D rendering grows almost linearly with frequency, what matters in the end is Euros/GHz, that is normalized GHz)
Phynaz - Friday, September 30, 2011 - link
What studio renders on overclocked desktop cpu's?confusis - Friday, September 30, 2011 - link
My studio does. We can't yet step up to a higher end multi-socket rendering server (finances, start-up company) so we make do with Phenom II x4's. A desktop box is good value for money at our end of the company scale. Once we grow we'll be looking at Interlagos however