AMD's Radeon HD 6970 & Radeon HD 6950: Paving The Future For AMD
by Ryan Smith on December 15, 2010 12:01 AM ESTCompute & Tessellation
Moving on from our look at gaming performance, we have our customary look at compute performance, bundled with a look at theoretical tessellation performance. This will give us our best chance to not only look at the theoretical aspects of AMD’s tessellation improvements, but to isolate shader performance to see whether AMD’s theoretical performance advantages and disadvantages from VLIW4 map out to real world scenarios.
Our first compute benchmark comes from Civilization V, which uses DirectCompute to decompress textures on the fly. Civ V includes a sub-benchmark that exclusively tests the speed of their texture decompression algorithm by repeatedly decompressing the textures required for one of the game’s leader scenes.

Civilization V’s compute shader benchmark has always benefitted NVIDIA, but that’s not the real story here. The real story is just how poorly the 6900 series does compared to the 5870. The 6970 barely does better than the 5850, meanwhile the 6950 is closest to NVIDIA’s GTX 460, the 768MB version. If what AMD says is true about the Cayman shader compiler needing some further optimization, then this is benchmark where that’s readily apparent. As an application of GPU computing, we’d expect the 6900 series to do at least somewhat better than the 5870, not notably worse.
Our second GPU compute benchmark is SmallLuxGPU, the GPU ray tracing branch of the open source LuxRender renderer. While it’s still in beta, SmallLuxGPU recently hit a milestone by implementing a complete ray tracing engine in OpenCL, allowing them to fully offload the process to the GPU. It’s this ray tracing engine we’re testing.

Unlike Civ 5, SmallLuxGPU’s performance is much closer to where things should be theoretically. Even with all of AMD’s shader changes both the 5870 and 6970 have a theoretical 2.7 TFLOPs of compute performance, and SmallLuxGPU backs up that number. The 5870 and 6970 are virtually tied, exactly where we’d expect our performance to be if everything is running under reasonably optimal conditions. Note that this means that the 6950 and 6970 both outperform the GTX 580 here, as SmallLuxGPU does a good job setting AMD’s drivers up to extract ILP out of the OpenCL kernel it uses.
Our final compute benchmark is Cyberlink’s MediaEspresso 6, the latest version of their GPU-accelerated video encoding suite. MediaEspresso 6 doesn’t currently utilize a common API, and instead has codepaths for both AMD’s APP and NVIDIA’s CUDA APIs, which gives us a chance to test each API with a common program bridging them. As we’ll see this doesn’t necessarily mean that MediaEspresso behaves similarly on both AMD and NVIDIA GPUs, but for MediaEspresso users it is what it is.
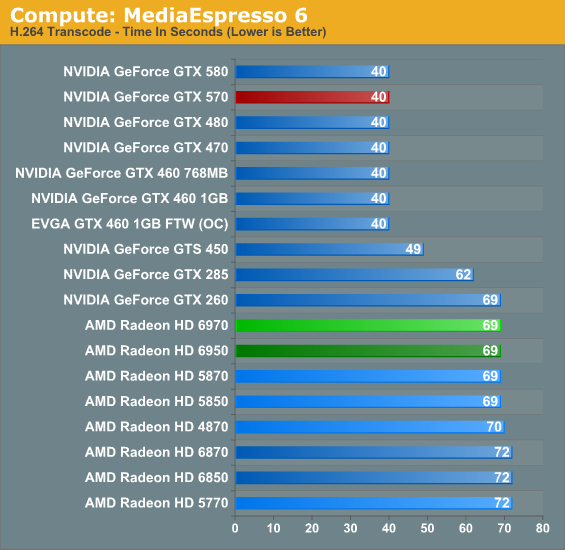
MediaEspresso 6 quickly gets CPU bottlenecked when paired with a faster GPU, leading to our clusters of results. For the 6900 series this mostly serves as a sanity check, proving that transcoding performance has not slipped even with AMD’s new architecture.
At the other end of the spectrum from GPU computing performance is GPU tessellation performance, used exclusively for graphical purposes. For the Radeon 6900 series, AMD significantly enhanced their tessellation by doubling up on tessellation units and the graphic engines they reside in, which can result in up to 3x the tessellation performance over the 5870. In order to analyze the performance of AMD’s enhanced tessellator, we’re using the Unigine Heaven benchmark and Microsoft’s DirectX 11 Detail Tessellation sample program to measure the tessellation performance of a few of our cards.
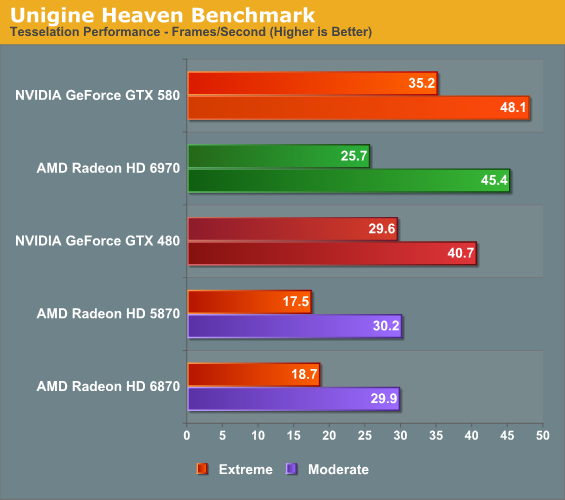
Since Heaven is a synthetic benchmark at the moment (the DX11 engine isn’t currently used in any games) we’re less concerned with performance relative to NVIDIA’s cards and more concerned with performance relative to the 5870. So with AMD’s tessellation improvements we see the 6970 shoot to life on this benchmark, coming in at nearly 50% faster than the 5870 at both moderate and extreme tessellation settings. This is actually on the low end of AMD’s theoretical tessellation performance improvements, but then even the geometrically overpowered GTX 580 doesn’t get such clear gains. But on that note while the 6970 does well at moderate tessellation levels, at extreme tessellation levels it still falls to the more potent GTX 400/500 series.

As for Microsoft’s DirectX 11 Detail Tessellation Sample program, a different story is going on. The 6970 once again shows significant gains over the 5870, but this time not against the 6870. With the 6870 implementing AMD’s tessellation factor optimized tessellator, most of the 6970’s improvements are already accounted for here. At the same time we can still easily see just how much of an advantage NVIDIA’s GTX 400/500 series still has in the theoretical tessellation department.








168 Comments
View All Comments
B3an - Thursday, December 16, 2010 - link
Very stupid uninformed and narrow-minded comment. People like you never look to the future which anyone should do when buying a graphics card, and you completely lack any imagination. Theres already tons of uses for GPU computing, many of which the average computer user can make use of, even if it's simply encoding a video faster. And it will be use a LOT more in the future.Most people, especially ones that game, dont even have 17" monitors these days. The average size monitor for any new computer is at least 21" with 1680 res these days. Your whole comment is as if everyone has the exact same needs as YOU. You might be happy with your ridiculously small monitor, and playing games at low res on lower settings, and it might get the job done, but lots of people dont want this, they have standards and large monitors and needs to make use of these new GPU's. I cant exactly see many people buying these cards with a 17" monitor!
CeepieGeepie - Thursday, December 16, 2010 - link
Hi Ryan,First, thanks for the review. I really appreciate the detail and depth on the architecture and compute capabilities.
I wondered if you had considered using some of the GPU benchmarking suites from the academic community to give even more depth for compute capability comparisons. Both SHOC (http://ft.ornl.gov/doku/shoc/start) and Rodinia (https://www.cs.virginia.edu/~skadron/wiki/rodinia/... look like they might provide a very interesting set of benchmarks.
Ryan Smith - Thursday, December 16, 2010 - link
Hi Ceepie;I've looked in to SHOC before. Unfortunately it's *nix-only, which means we can't integrate it in to our Windows-based testing environment. NVIDIA and AMD both work first and foremost on Windows drivers for their gaming card launches, so we rarely (if ever) have Linux drivers available for the launch.
As for Rodinia, this is the first time I've seen it. But it looks like their OpenCL codepath isn't done, which means it isn't suitable for cross-vendor comparisons right now.
IdBuRnS - Thursday, December 16, 2010 - link
"So with that in mind a $370 launch price is neither aggressive nor overpriced. Launching at $20 over the GTX 570 isn’t going to start a price war, but it’s also not so expensive to rule the card out. "At NewEgg right now:
Cheapest GTX 570 - $509
Cheapest 6970 - $369
$30 difference? What are you smoking? Try $140 difference.
IdBuRnS - Thursday, December 16, 2010 - link
Oops, $20 difference. Even worse.IdBuRnS - Thursday, December 16, 2010 - link
570...not 580.../hangsheadinshame
epyon96 - Thursday, December 16, 2010 - link
This was a very interesting discussion to me in the article.I'm curious if Anandtech might expand on this further in a future dedicated article comparing what NVIDIA is using to AMD.
Are they also more similar to VLIW4 or VLIW5?
Can someone else shed some light on it?
Ryan Smith - Thursday, December 16, 2010 - link
We wrote something almost exactly like you're asking for for our Radeon HD 4870 review.http://www.anandtech.com/show/2556
AMD and NVIDIA's compute architectures are still fundamentally the same, so just about everything in that article still holds true. The biggest break is VLIW4 for the 6900 series, which we covered in our article this week.
But to quickly answer your question, GF100/GF110 do not immediately compare to VLIW4 or VLIW5. NVIDIA is using a pure scalar architecture, which has a number of fundamental differences from any VLIW architecture.
dustcrusher - Thursday, December 16, 2010 - link
The cheap insults are nothing but a detriment to what is otherwise an interesting argument, even if I don't agree with you.As far as the intellect of Anandtech readers goes, this is one of the few sites where almost all of the comments are worth reading; most sites are the opposite- one or two tiny bits of gold in a big pan of mud.
I'm not going to "vastly overestimate" OR underestimate your intellect though- instead I'm going to assume that you got caught up in the moment. This isn't Tom's or Dailytech, a little snark is plenty.
Arnulf - Thursday, December 16, 2010 - link
When you launch an application (say a game), it is likely to be the only active thread running on the system, or perhaps one of very few active threads. CPU with Turbo function will clock up as high as possible to run this main thread. When further threads are launched by the application, CPU will inevitably increase its power consumption and consequently clock down.While CPU manufacturers don't advertise this functionality in this manner, it is really no different from PowerTune.
Would PowerTune technology make you feel any better if it was marketed the other way around, the way CPUs are ? (mentioning lowest frequencies and clock boost provided that thermal cap isn't met yet)