NVIDIA's GeForce GTX 580: Fermi Refined
by Ryan Smith on November 9, 2010 9:00 AM ESTCompute and Tessellation
Moving on from our look at gaming performance, we have our customary look at compute performance, bundled with a look at theoretical tessellation performance. Unlike our gaming benchmarks where NVIDIA’s architectural enhancements could have an impact, everything here should be dictated by the core clock and SMs, with shader and polymorph engine counts defining most of these tests.
Our first compute benchmark comes from Civilization V, which uses DirectCompute to decompress textures on the fly. Civ V includes a sub-benchmark that exclusively tests the speed of their texture decompression algorithm by repeatedly decompressing the textures required for one of the game’s leader scenes.

We previously discovered that NVIDIA did rather well in this test, so it shouldn’t come as a surprise that the GTX 580 does even better. Even without the benefits of architectural improvements, the GTX 580 still ends up pulling ahead of the GTX 480 by 15%. The GTX 580 also does well against the 5970 here, which does see a boost from CrossFire but ultimately falls short, showcasing why multi-GPU cards can be inconsistent at times.
Our second compute benchmark is Cyberlink’s MediaEspresso 6, the latest version of their GPU-accelerated video encoding suite. MediaEspresso 6 doesn’t currently utilize a common API, and instead has codepaths for both AMD’s APP (née Stream) and NVIDIA’s CUDA APIs, which gives us a chance to test each API with a common program bridging them. As we’ll see this doesn’t necessarily mean that MediaEspresso behaves similarly on both AMD and NVIDIA GPUs, but for MediaEspresso users it is what it is.

We throw MediaEspresso 6 in largely to showcase that not everything that’s GPU accelerated is GPU-bound, as ME6 showcases this nicely. Once we move away from sub-$150 GPUs, APIs and architecture become much more important than raw speed. The 580 is unable to differentiate itself from the 480 as a result.
Our third GPU compute benchmark is SmallLuxGPU, the GPU ray tracing branch of the open source LuxRender renderer. While it’s still in beta, SmallLuxGPU recently hit a milestone by implementing a complete ray tracing engine in OpenCL, allowing them to fully offload the process to the GPU. It’s this ray tracing engine we’re testing.

SmallLuxGPU is rather straightforward in its requirements: compute and lots of it. The GTX 580 attains most of its theoretical performance improvement here, coming in at a bit over 15% over the GTX 480. It does get bested by a couple of AMD’s GPUs however, a showcase of where AMD’s theoretical performance advantage in compute isn’t so theoretical.
Our final compute benchmark is a Folding @ Home benchmark. Given NVIDIA’s focus on compute for Fermi and in particular GF110 and GF100, cards such as the GTX 580 can be particularly interesting for distributed computing enthusiasts, who are usually looking for the fastest card in the coolest package. This benchmark is from the original GTX 480 launch, so this is likely the last time we’ll use it.
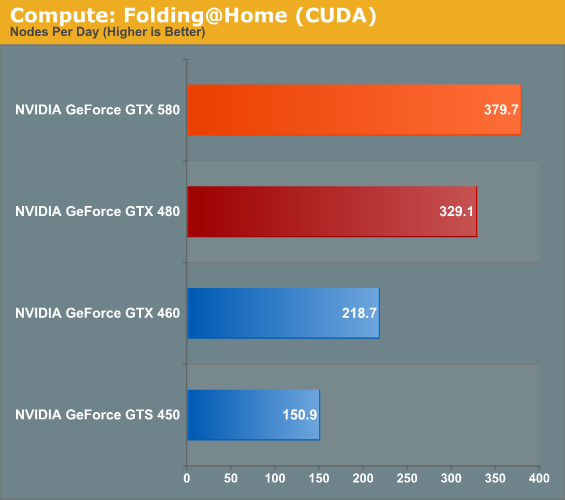
If I said the GTX 580 was 15% faster, would anyone be shocked? So long as we’re not CPU bound it seems, the GTX 580 is 15% faster through all of our compute benchmarks. This coupled with the GTX 580’s cooler/quieter design should make the card a very big deal for distributed computing enthusiasts.
At the other end of the spectrum from GPU computing performance is GPU tessellation performance, used exclusively for graphical purposes. Here we’re interesting in things from a theoretical architectural perspective, using the Unigine Heaven benchmark and Microsoft’s DirectX 11 Detail Tessellation sample program to measure the tessellation performance of a few of our cards.
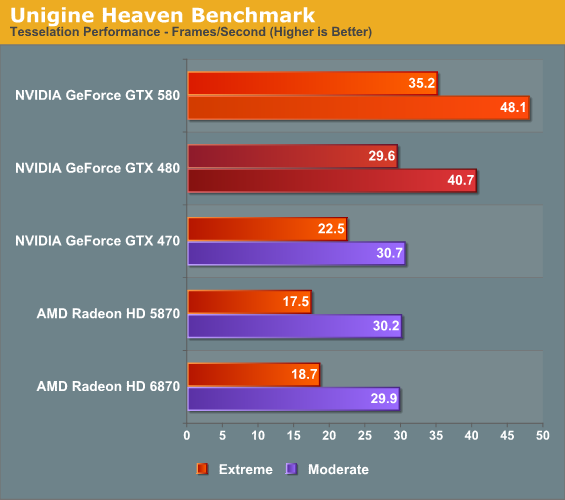
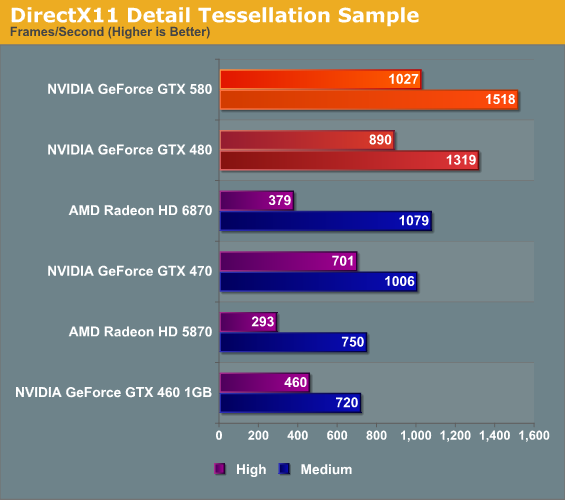
NVIDIA likes to heavily promote their tessellation performance advantage over AMD’s Cypress and Barts architectures, as it’s by far the single biggest difference between them and AMD. Not surprisingly the GTX 400/500 series does well here, and between those cards the GTX 580 enjoys a 15% advantage in the DX11 tessellation sample, while Heaven is a bit higher at 18% since Heaven is a full engine that can take advantage of the architectural improvements in GF110.
Seeing as how NVIDIA and AMD are still fighting about the importance of tessellation in both the company of developers and the public, these numbers shouldn’t be used as long range guidance. NVIDIA clearly has an advantage – getting developers to use additional tessellation in a meaningful manner is another matter entirely.








160 Comments
View All Comments
StevoLincolnite - Tuesday, November 9, 2010 - link
I would have called them the 6750/6770 personally... Or at the very least the 6830/6850.There were also some architectural changes in the GTX 580 as well.
slickr - Tuesday, November 9, 2010 - link
Whats real and whats not real for you?6850 and 6870 are essentially more shaders, rops and higher clocks with few architectural improvements.
It will be same for the 6900 series.
GTX 580 again is same as the above, few architectural improvements, higher shaders, textures and clocks.
Credit must be given where its due and even though this was supposed to be the 480, its still a great product by its own, its faster, cooler, quieter and less power hungry.
ninjaquick - Thursday, December 2, 2010 - link
Umm, 6850 and 6870 are DECREASES on all but ROPs and Clocks. The architecture is only similar and very much evolutionary:numbers are: Universal Shader : Texture Mapping Unit : Render Output unit.
5850: 1440:72:32
6850: 960:48:32
5870: 1600:80:32
6870: 1120:56:32
So, 5-10% slower and 33% component shrink, which is to say ~1.4x perf increase per shader. So a full blown (6970) NI at an assumed 1600 shaders like the previous gen would be the rough equivalent of a 2400 shader evergreen when it comes to raw performance, so 1.4 to 1.5 times faster. It can be safely assumed that the shader performance will be higher than 2 5830s in CFX. 2 5830s are about 30% faster than a GTX 580.
That is theoretical performance based on a lot of assumptions and Ideal drivers. My point is NI is not a ground up redesign but it is a vastly superior and vastly different architecture to Evergreen.
boe - Thursday, November 18, 2010 - link
I can't wait to see a comparison with the 6970. I don't know which will win but it will help me decide which to get - I'm still using a 4870 so I'm ready for something new!The other thing that will help me decide is card options. The 4870 had some very nice "pre-silenced" modified cards right after release. The 6870 already has some "pre-silenced" cards on the market. The factory standard 580 is pretty loud although it is quieter than the 480 by far. I'm hoping there will be some modified 580's on the market with much quieter but at least as effective cooling solutions.
Will Robinson - Tuesday, November 9, 2010 - link
This is a much better effort than GTX480.Cooler,quieter and faster.
AMD will have a tough fight on their hands with Cayman XT versus this new part.
StevoLincolnite - Tuesday, November 9, 2010 - link
Can't wait for a price war, something that seemed to be missing with Fermi and the 5xxx series.Sihastru - Tuesday, November 9, 2010 - link
Let's hope so. This way both fanbois camps will win when it comes to how much lighter their wallets will be after their purchase (in some cases their parents wallets - only children act like fanbois).B3an - Wednesday, November 10, 2010 - link
I -wish- only children acted like fanboys. The fact is that a lot of these guys are well into there 20's and 30's.They really are pathetic people.
mino - Tuesday, November 9, 2010 - link
Well not that it was hard to beat 480 ... that part was not ready for prime time in the first place.dragonsqrrl - Wednesday, March 18, 2015 - link
...lol, facepalm.