NVIDIA's GeForce GTX 580: Fermi Refined
by Ryan Smith on November 9, 2010 9:00 AM ESTGF110: Fermi Learns Some New Tricks
We’ll start our in-depth look at the GTX 580 with a look at GF110, the new GPU at the heart of the card.
There have been rumors about GF110 for some time now, and while they ultimately weren’t very clear it was obvious NVIDIA would have to follow up GF100 with something else similar to it on 40nm to carry them through the rest of the processes’ lifecycle. So for some time now we’ve been speculating on what we might see with GF100’s follow-up part – an outright bigger chip was unlikely given GF100’s already large die size, but NVIDIA has a number of tricks they can use to optimize things.
Many of those tricks we’ve already seen in GF104, and had you asked us a month ago what we thought GF110 would be, we were expecting some kind of fusion of GF104 and GF100. Primarily our bet was on the 48 CUDA Core SM making its way over to a high-end part, bringing with it GF104’s higher theoretical performance and enhancements such as superscalar execution and additional special function and texture units for each SM. What we got wasn’t quite what we were imagining – GF110 is much more heavily rooted in GF100 than GF104, but that doesn’t mean NVIDIA hasn’t learned a trick or two.
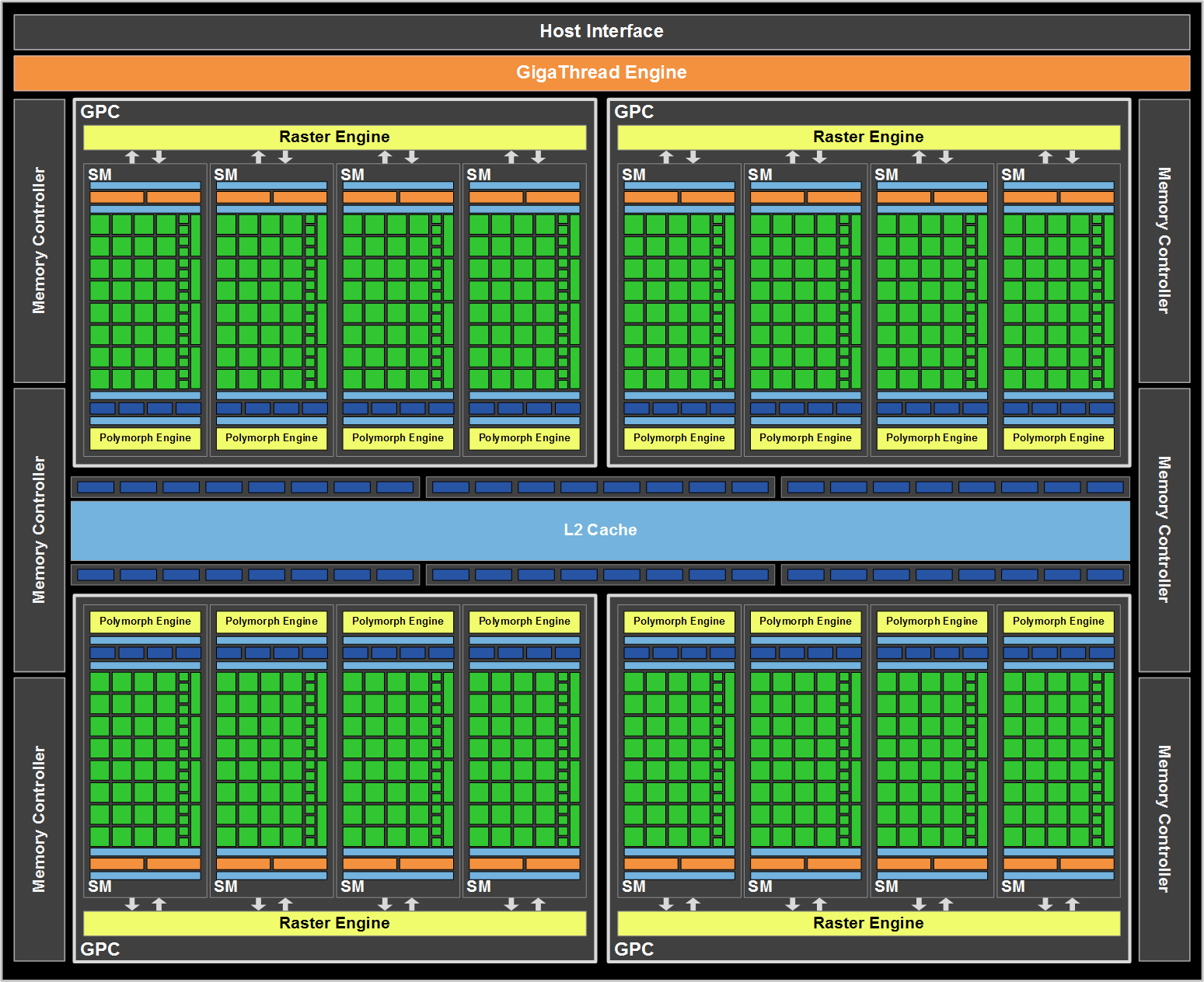
Fundamentally GF110 is the same architecture as GF100, especially when it comes to compute. 512 CUDA Cores are divided up among 4 GPCs, and in turn each GPC contains 1 raster engine and 4 SMs. At the SM level each SM contains 32 CUDA cores, 16 load/store units, 4 special function units, 4 texture units, 2 warp schedulers with 1 dispatch unit each, 1 Polymorph unit (containing NVIDIA’s tessellator) and then the 48KB+16KB L1 cache, registers, and other glue that brought an SM together. At this level NVIDIA relies on TLP to keep a GF110 SM occupied with work. Attached to this are the ROPs and L2 cache, with 768KB of L2 cache serving as the guardian between the SMs and the 6 64bit memory controllers. Ultimately GF110’s compute performance per clock remains unchanged from GF100 – at least if we had a GF100 part with all of its SMs enabled.
On the graphics side however, NVIDIA has been hard at work. They did not port over GF104’s shader design, but they did port over GF104’s texture hardware. Previously with GF100, each unit could compute 1 texture address and fetch 4 32bit/INT8 texture samples per clock, 2 64bit/FP16 texture samples per clock, or 1 128bit/FP32 texture sample per clock. GF104’s texture units improved this to 4 samples/clock for 32bit and 64bit, and it’s these texture units that have been brought over for GF110. GF110 can now do 64bit/FP16 filtering at full speed versus half-speed on GF100, and this is the first of the two major steps NVIDIA took to increase GF110’s performance over GF100’s performance on a clock-for-clock basis.
| NVIDIA Texture Filtering Speed (Per Texture Unit) | |||||
| GF110 | GF104 | GF100 | |||
| 32bit (INT8) | 4 Texels/Clock | 4 Texels/Clock | 4 Texels/Clock | ||
| 64bit (FP16) | 4 Texels/Clock | 4 Texels/Clock | 2 Texels/Clock | ||
| 128bit (FP32) | 1 Texel/Clock | 1 Texel/Clock | 1 Texel/Clock | ||
Like most optimizations, the impact of this one is going to be felt more on newer games than older games. Games that make heavy use of 64bit/FP16 texturing stand to gain the most, while older games that rarely (if at all) used 64bit texturing will gain the least. Also note that while 64bit/FP16 texturing has been sped up, 64bit/FP16 rendering has not – the ROPs still need 2 cycles to digest 64bit/FP16 pixels, and 4 cycles to digest 128bit/FP32 pixels.
It’s also worth noting that this means that NVIDIA’s texture:compute ratio schism remains. Compared to GF100, GF104 doubled up on texture units while only increasing the shader count by 50%; the final result was that per SM 32 texels were processed to 96 instructions computed (seeing as how the shader clock is 2x the base clock), giving us 1:3 ratio. GF100 and GF110 on the other hand retain the 1:4 (16:64) ratio. Ultimately at equal clocks GF104 and GF110 widely differ in shading, but with 64 texture units total in both designs, both have equal texturing performance.
Moving on, GF110’s second trick is brand-new to GF110, and it goes hand-in-hand with NVIDIA’s focus on tessellation: improved Z-culling. As a quick refresher, Z-culling is a method of improving GPU performance by throwing out pixels that will never be seen early in the rendering process. By comparing the depth and transparency of a new pixel to existing pixels in the Z-buffer, it’s possible to determine whether that pixel will be seen or not; pixels that fall behind other opaque objects are discarded rather than rendered any further, saving on compute and memory resources. GPUs have had this feature for ages, and after a spurt of development early last decade under branded names such as HyperZ (AMD) and Lightspeed Memory Architecture (NVIDIA), Z-culling hasn’t been promoted in great detail since then.

Z-Culling In Action: Not Rendering What You Can't See
For GF110 this is changing somewhat as Z-culling is once again being brought back to the surface, although not with the zeal of past efforts. NVIDIA has improved the efficiency of the Z-cull units in their raster engine, allowing them to retire additional pixels that were not caught in the previous iteration of their Z-cull unit. Without getting too deep into details, internal rasterizing and Z-culling take place in groups of pixels called tiles; we don’t believe NVIDIA has reduced the size of their tiles (which Beyond3D estimates at 4x2); instead we believe NVIDIA has done something to better reject individual pixels within a tile. NVIDIA hasn’t come forth with too many details beyond the fact that their new Z-cull unit supports “finer resolution occluder tracking”, so this will have to remain a mystery for another day.
In any case, the importance of this improvement is that it’s particularly weighted towards small triangles, which are fairly rare in traditional rendering setups but can be extremely common with heavily tessellated images. Or in other words, improving their Z-cull unit primarily serves to improve their tessellation performance by allowing NVIDIA to better reject pixels on small triangles. This should offer some benefit even in games with fewer, larger triangles, but as framed by NVIDIA the benefit is likely less pronounced.
In the end these are probably the most aggressive changes NVIDIA could make in such a short period of time. Considering the GF110 project really only kicked off in earnest in February, NVIDIA only had around half a year to tinker with the design before it had to be taped out. As GPUs get larger and more complex, the amount of tweaking that can get done inside such a short window is going to continue to shrink – and this is a far cry from the days where we used to get major GPU refreshes inside of a year.








160 Comments
View All Comments
RussianSensation - Wednesday, November 10, 2010 - link
Very good point techcurious. Which is why the comment in the review about having GTX580 not being a quiet card at load is somewhat misleading. I have lowered my GTX470 from 40% idle fan speed to 32% fan speed and my idle temperatures only went up from 38*C to 41*C. At 32% fan speed I can not hear the car at all over other case fans and Scythe S-Flex F cpu fan. You could do the same with almost any videocard.Also, as far as FurMark goes, the test does test all GPUs beyond their TDPs. TDP is typically not the most power the chip could ever draw, such as by a power virus like FurMark, but rather the maximum power that it would draw when running real applications. Since HD58/68xx series already have software and hardware PowerPlay enabled which throttles their cards under power viruses like FurMark it was already meaningless to use FurMark for "maximum" power consumption figures. Besides the point, FurMark is just a theoretical application. AMD and NV implement throttling to prevent VRM/MOSFET failures. This protects their customers.
While FurMark can be great for stability/overclock testing, the power consumption tests from it are completely meaningless since it is not something you can achieve in any videogame (can a videogame utilize all GPU resources to 100%? Of course not since there are alwasy bottlenecks in GPU architectures).
techcurious - Wednesday, November 10, 2010 - link
How cool would it be if nVidia added to it's control panel a tab for dynamic fan speed control based on 3 user selectable settings.1) Quiet... which would spin the fan at the lowest speed while staying just enough below the GPU temperature treshold at load and somewhere in the area of low 50 C temp in idle.
2) Balanced.. which would be a balance between moderate fan speed (and noise levels) resulting in slightly lower load temperatures and perhaps 45 C temp in idle.
3) Cool.. which would spin the fan the fastest, be the loudest setting but also the coolest. Keeping load temperatures well below the maximum treshold and idle temps below 40 C. This setting would please those who want to extend the life of their graphics card as much as possible and do not care about noise levels, and may anyway have other fans in their PC that is louder anyway!
Maybe Ryan or someone else from Anandtech (who would obviously have much more pull and credibility than me) could suggest such a feature to nVidia and AMD too :o)
BlazeEVGA - Wednesday, November 10, 2010 - link
Here's what I dig about you guys at AnandTech, not only are your reviews very nicely presented but you keep it relevant for us GTX 285 owners and other more legacy bound interested parties - most other sites fail to provide this level of complete comparison. Much appreciated. You charts are fanatastic, your analysis and commentary is nicely balanced and attention to detail is most excellent - this all makes for a more simplified evaluation by the potential end user of this card.Keep up the great work...don't know what we'd do without you...
Robaczek - Thursday, November 11, 2010 - link
I really liked the article but would like to see some comparison with nVidia GTX295..massey - Wednesday, November 24, 2010 - link
Do what I did. Lookup their article on the 295, and compare the benchmarks there to the ones here.Here's the link:
http://www.anandtech.com/show/2708
Seems like Crysis runs 20% faster at max res and AA. Is a 20% speed up worth $500? Maybe. Depends on how anal you are about performance.
lakedude - Friday, November 12, 2010 - link
Someone needs to edit this review! The acronym "AMD" is used several places when it is clear "ATI" was intended.For example:
"At the same time, at least the GTX 580 is faster than the GTX 480 versus AMD’s 6800/5800 series"
lakedude - Friday, November 12, 2010 - link
Never mind, looks like I'm behind the times...Nate007 - Saturday, November 13, 2010 - link
In the end we ( the gamers) who purchase these cards NEED to be be supporting BOTH sides so the AMD and Nvidia can both manage to stay profitable.Its not a question of who Pawns who but more importantly that we have CHOICE !!
Maybe some of the people here ( or MOST) are not old enough to remember the days when mighty
" INTEL" ruled the landscape. I can tell you for 100% fact that CPU's were expensive and there was no choice in the matter.
We can agree to disagree but in the END, we need AMD and we need NVIDIA to keep pushing the limits and offering buyers a CHOICE.
God help us if we ever lose one or the other, then we won't be here reading reviews and or jousting back and forth on who has the biggest stick. We will all be crying and complaining how expense it will be to buy a decent Video card.
Here's to both Company's ..............Long live NVIDIA & AMD !
Philip46 - Wednesday, November 17, 2010 - link
Finally, at the high end Nvidia delivers a much cooler and quiter, one GPU card, that is much more like the GTX 460, and less like the 480, in terms of performance/heat balance.I'm one where i need Physx in my games, and until now, i had to go with a SLI 460 setup for one pc and for a lower rig, a 2GB 460 GTX(for maxing GTA:IV out).
Also, i just prefer the crisp Nvidia desktop quality, and it's drivers are more stable. (and ATI's CCC is a nightmare)
For those who want everything, and who use Physx, the 580 and it's upcoming 570/560 will be the only way to go.
For those who live by framerate only, then you may want to see what the next ATI lineup will deliver for it's single GPU setup.
But whatever you choose, this is a GREAT thing for the industry..and the gamer, as Nvidia delivered this time with not just performance, but also lower temps/noise levels, as well.
This is what the 480, should have been, but thankfully they fixed it.
swing848 - Wednesday, November 24, 2010 - link
Again, Anand is all over the place with different video cards, making judgements difficult.He even threw in a GTS 450 and an HD 4870 here and there. Sometimes he would include the HD 5970 and often not.
Come on Anand, be consistent with the charts.