AMD Discloses Bobcat & Bulldozer Architectures at Hot Chips 2010
by Anand Lal Shimpi on August 24, 2010 1:33 AM ESTA Real Redesign
When we first met Phenom we were disappointed that it didn’t introduce the major architectural changes AMD needed to keep up with Intel. The front end and execution hardware remained largely unchanged from the K8, and as a result Intel pulled ahead significantly in performance per clock over the past few years. With Bulldozer, we finally got the redesign that we’ve been asking for.
If we look at Westmere, Intel has a 4-issue architecture that’s shared among two threads. At the front end, a single Bulldozer module is essentially the same. The fetch logic in Bulldozer can grab instructions from two threads and send it to the decoder. Note that either thread can occupy the full width of the front end if necessary.
The instruction fetcher pulls from a 64KB 2-way instruction cache, unchanged from the Phenom II.
The decoder is now 4-wide an increase from the 3-wide front end that AMD has had since the K7 all the way up to Phenom II. AMD can now fuse x86 branch instructions, similar to Intel’s macro-ops fusion to increase the effective width of the machine as well. At a high level, AMD’s front end has finally caught up to Intel, but here’s where AMD moves into the passing lane.
The 4-wide decode engine feeds three independent schedulers: two for the integer cores and one for the shared floating point hardware.
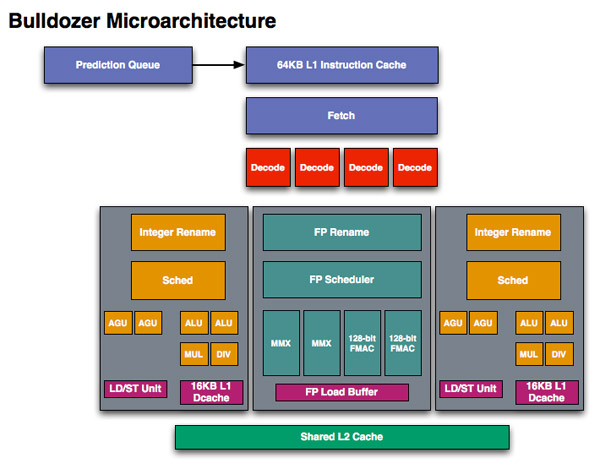
Bullddozer, 2 threads per module
Each integer scheduler is now unified. In the Phenom II and previous architectures AMD had individual schedulers for math and address operations, but with Bulldozer it’s all treated as one.
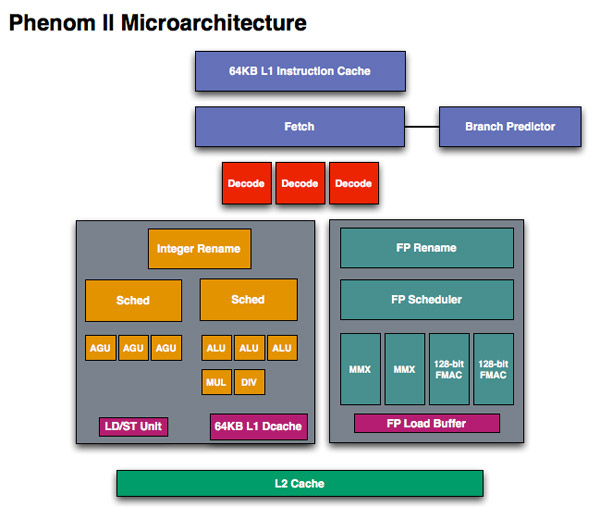
Phenom II, 1 thread per core
Each scheduler has four ports that feed a pair of ALUs and a pair of AGUs. This is down one ALU/AGU from Phenom II (it had 3 ALUs and 3 AGUs respectively and could do any mix of 3). AMD insists that the 3rd address generation unit wasn’t necessary in Phenom II and was only kept around for symmetry with the ALUs and to avoid redesigning that part of the chip - the integer execution core is something AMD has kept around since the K8. The 3rd ALU does have some performance benefits, and AMD canned it to reduce die size, but AMD mentioned that the 4-wide front end, fusion and other enhancements more than make up for this reduction. In other words, while there’s fewer single thread integer execution resources in Bulldozer than Phenom II, single threaded integer performance should still be higher.
Each integer core has its own 16KB L1 data cache. The L1 caches are segmented by thread so the shared FP core chooses which L1 cache to pull from depending on what thread it’s working on.
I asked AMD if the small L1 data cache was going to be a problem for performance, but it mentioned that in modern out of order machines it’s quite easy to hide the latency to L2 and thus this isn’t as big of an issue as you’d think. Given how aggressive AMD has been in the past with ramping up L1 cache sizes, this is a definite change of pace which further indicates how significant of a departure Bulldozer is from the norm at AMD.

While there are two integer schedulers in a single Bulldozer module (one for each thread), there’s only one FP scheduler. There’s some hardware duplication at the FP scheduler to allow two threads to share the execution resources behind it. While each integer core behaves like an independent core, the FP resources work as they would in a SMT (Hyper Threading) system.
The FP scheduler has four ports to its FPUs. There are two 128-bit FMAC pipes and two 128-bit packed integer pipes. Like Sandy Bridge, AMD’s Bulldozer will support SSE all the way up to 4.2 as well as Intel’s new AVX instructions. The 256-bit AVX ops will be handled by the two 128-bit FMAC units in each Bulldozer module.
Each Bulldozer module has its own private L2 cache shared by both integer cores and the FP execution hardware.








76 Comments
View All Comments
Dustin Sklavos - Tuesday, August 24, 2010 - link
Comments like this really bother me. You may not care about netbooks, but a lot of people do. Current ones don't pass the grandma test - your grandmother can do whatever task she needs to on them, like check e-mail, browse the internet, watch HD video - and any advance here is welcome.Generally speaking a netbook is not supposed to be your main machine, but something you can chuck into your bag and take with you and do a little work on here and there. I write a lot, and have to work on other peoples' computers from time to time, so a netbook that doesn't completely suck is invaluable to me. Netbook performance is dismal right now, but Bobcat could successfully fix this market segment.
So no, you're not interested in netbooks and you'd rather be raked through hot coals than purchase one. But that just means they're not useful - TO YOU. There are a lot of people here interested in what Bobcat can do for these portables, and I count myself among them.
Lonbjerg - Wednesday, August 25, 2010 - link
I don't care that many people care for mediocore performance in a crappy format.Not matter what you do with a netbook, it will alway be lacking.
I don't care what gandma wants (she will buy intel BTW, due to Intel's brand recognition)
I don't care for Atom either.
Or i3
Or i5
Or Phenom
I do care about a replacement for my i7 @ 3.5GHz...
Dustin Sklavos - Wednesday, August 25, 2010 - link
I'm trying to figure out why you're commenting on any of this at all.flipmode - Tuesday, August 24, 2010 - link
Seriously Anand, it is crummy that I cannot find a whole section of your website. I hate to spam an entirely separate article, but how completely lame it is to have to spend 15 minutes doing a Google advanced search to find the Anandtech article I'm looking for.One of the very, very few truly Class A+ hardware sites on the internet - you can count all the members of that class on one hand - and you make it seriously hard to find past articles and you completely OMIT a link to an entire category of your reviews. Insane.
Please put a link to the "System" section somewhere. Please!
JarredWalton - Tuesday, August 24, 2010 - link
Our system section hasn't had a lot of updates, but you can get there via:http://www.anandtech.com/tag/systems
In fact, most common tags can be put there (i.e. /AMD, /Intel, /NVIDIA, /HP, /ASUS, etc.) The only catch is that many of the tags will only bring up articles since the site redesign, so you'll want to stick with the older main topics for some areas. Hope that helps.
mino - Tuesday, August 24, 2010 - link
"so I’m wondering if we’ll see Bulldozer adopt a 3 - 4 channel DDR3 memory controller"Bulldozer will use current G34 platform. Hoe that answers your wonder :)
VirtualLarry - Tuesday, August 24, 2010 - link
BullDozer sounds like amazing stuff. I wonder, if the way that they have arranged int units into modules, if that means that we will be getting more cores for our dollars, compared to Intel. More REAL cores, I mean. I'm just a little disappointed that the int pipelines went from 3 ALU to 2 ALU, I hope that doesn't affect performance too much.gruffi - Thursday, August 26, 2010 - link
Integer instruction pipelines are increased from 3 to 4. That's 33% more peak throughput. The number of ALUs/AGUs to keep these pipelines busy is meaningless without knowing details. K10 has 3 ALUs and 3 AGUs, but they are bottlenecked and partially idling most of the time. Bulldozer can do more operations per cycle while drawing less power, even with only 2 ALUs and 2 AGUs. How can that be disappointing?ezodagrom - Tuesday, August 24, 2010 - link
I think Bulldozer has the potential to be really competitive, mainly because Sandy Bridges looks quite unimpressive.In a recent leaked powerpoint from Intel, apparently until Q3 2011 the best Intel CPU is still going to be Gulftown based, possibly Core i7 990X. According to Intel benchmarks on the leaked powerpoint, the best Sandy Bridge, that is, Core i7 2600, apparently will be around 15% to 25% better than the i7 870, with the i7 980X being 25% to 35% better than the i7 2600.
Mat3 - Tuesday, August 24, 2010 - link
I have a question.. it was earlier speculated that BD would have four ALU pipelines per integer core. It was thought that one way they could make use of them was to send a branch down two pipes and take the correct result. Obviously this isn't the case, but my question is, why not? Wouldn't it be better to do that and just discard the branch predictors entirely? Why isn't that better?