AMD's Radeon HD 5870: Bringing About the Next Generation Of GPUs
by Ryan Smith on September 23, 2009 9:00 AM EST- Posted in
- GPUs
Cypress: What’s New
With our refresher out of the way, let’s discuss what’s new in Cypress.
Starting at the SPU level, AMD has added a number of new hardware instructions to the SPUs and sped up the execution of other instruction, both in order to improve performance and to meet the requirements of various APIs. Among these changes are that some dot products have been reduced to single-cycle computation when they were previously multi-cycle affairs. DirectX 11 required operations such as bit count, insert, and extract have also been added. Furthermore denormal numbers have received some much-needed attention, and can now be handled at full speed.
Perhaps the most interesting instruction added however is an instruction for Sum of Absolute Differences (SAD). SAD is an instruction of great importance in video encoding and computer vision due to its use in motion estimation, and on the RV770 the lack of a native instruction requires emulating it in no less than 12 instructions. By adding a native SAD instruction, the time to compute a SAD has been reduced to a single clock cycle, and AMD believes that it will result in a significant (>2x) speedup in video encoding.
The clincher however is that SAD not an instruction that’s part of either DirectX 11 or OpenCL, meaning DirectX programs can’t call for it, and from the perspective of OpenCL it’s an extension. However these APIs leave the hardware open to do what it wants to, so AMD’s compiler can still use the instruction, it just has to know where to use it. By identifying the aforementioned long version of a SAD in code it’s fed, the compiler can replace that code with the native SAD, offering the native SAD speedup to any program in spite of the fact that it can’t directly call the SAD. Cool, isn’t it?
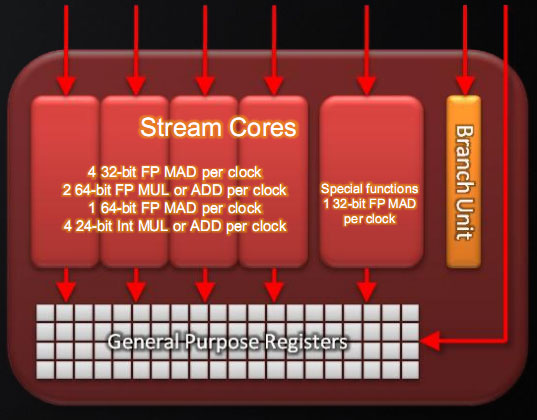
Last, here is a breakdown of what a single Cypress SP can do in a single clock cycle:
- 4 32-bit FP MAD per clock
- 2 64-bit FP MUL or ADD per clock
- 1 64-bit FP MAD per clock
- 4 24-bit Int MUL or ADD per clock
- SFU : 1 32-bit FP MAD per clock
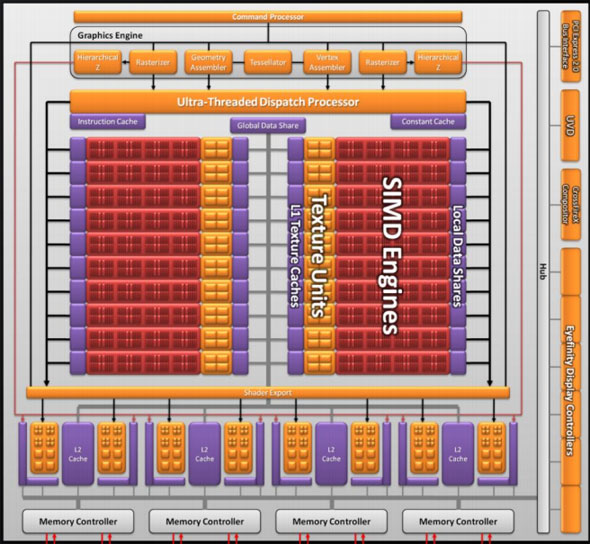
Moving up the hierarchy, the next thing we have is the SIMD. Beyond the improvements in the SPs, the L1 texture cache located here has seen an improvement in speed. It’s now capable of fetching texture data at a blistering 1TB/sec. The actual size of the L1 texture cache has stayed at 16KB. Meanwhile a separate L1 cache has been added to the SIMDs for computational work, this one measuring 8KB. Also improving the computational performance of the SIMDs is the doubling of the local data share attached to each SIMD, which is now 32KB.

At a high level, the RV770 and Cypress SIMDs look very similar
The texture units located here have also been reworked. The first of these changes are that they can now read compressed AA color buffers, to better make use of the bandwidth they have. The second change to the texture units is to improve their interpolation speed by not doing interpolation. Interpolation has been moved to the SPs (this is part of DX11’s new Pull Model) which is much faster than having the texture unit do the job. The result is that a texture unit Cypress has a greater effective fillrate than one under RV770, and this will show up under synthetic tests in particular where the load-it and forget-it nature of the tests left RV770 interpolation bound. AMD’s specifications call for 68 billion bilinear filtered texels per second, a product of the improved texture units and the improved bandwidth to them.
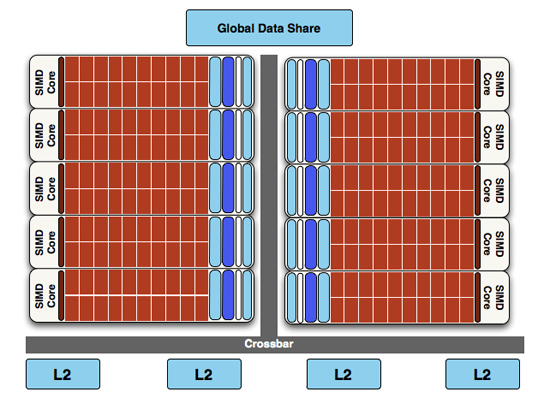
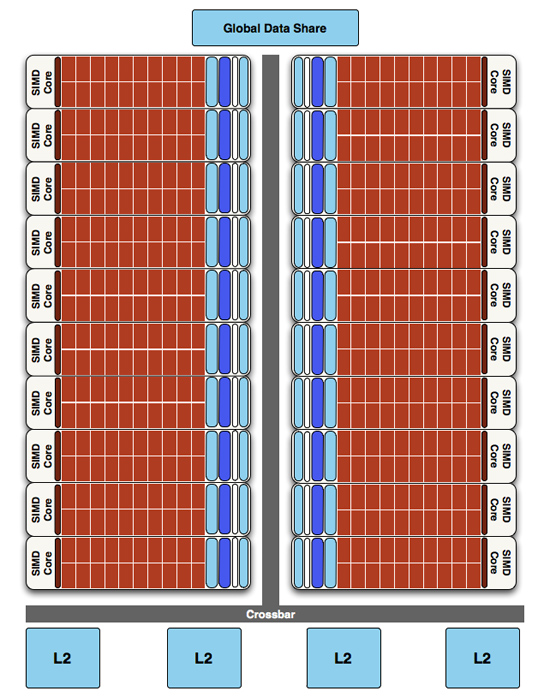
Finally, if we move up another level, here is where we see the cause of the majority of Cypress’s performance advantage over RV770. AMD has doubled the number of SIMDs, moving from 10 to 20. This means twice the number of SPs and twice the number of texture units; in fact just about every statistic that has doubled between RV770 and Cypress is a result of doubling the SIMDs. It’s simple in concept, but as the SIMDs contain the most important units, it’s quite effective in boosting performance.
However with twice as many SIMDs, there comes a need to feed these additional SIMDs, and to do something with their products. To achieve this, the 4 L2 caches have been doubled from 64KB to 128KB. These large L2 caches can now feed data to L1 caches at 435GB/sec, up from 384GB/sec in RV770. Along with this the global data share has been quadrupled to 64KB.
RV770 vs...
Cypress
Next up, the ROPs have been doubled in order to meet the needs of processing data from all of those SIMDs. This brings Cypress to 32 ROPs. The ROPs themselves have also been slightly enhanced to improve their performance; they can now perform fast color clears, as it turns out some games were doing this hundreds of times between frames. They are also responsible for handling some aspects of AMD’s re-introduced Supersampling Anti-Aliasing mode, which we will get to later.
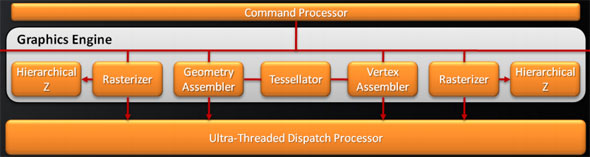
Last, but certainly not least, we have the changes to what AMD calls the “graphics engine”, primarily to bring it into compliance with DX11. RV770’s greatly underutilized tessellator has been upgraded to full DX11 compliance, giving it Hull Shader and Domain Shader capabilities, along with using a newer algorithm to reduce tessellation artifacts. A second rasterizer has also been added, ostensibly to feed the beast that is the 20 SIMDs.








327 Comments
View All Comments
avaughan - Wednesday, September 23, 2009 - link
Ryan,When you review the 5850 can you please specify memory size for all the comparison cards. At a guess the GTS 250 had 1GB and the 9800GT had 512 ?
Thanks
ThePooBurner - Wednesday, September 23, 2009 - link
With a full double the power and transistors and everything else including optimizations that should get more band for buck out of each one of those, why are we not seeing a full double the performance in games compared to the previous generation of cards?SiliconDoc - Wednesday, September 23, 2009 - link
Umm, because if you actually look at the charts, it's not "double everything".In fact, it's not double THE MOST IMPORTANT THING, bandwidth.
For pete sakes an OC'ed GTX260 core 192 get's to 154+ bandwidth rather easily, surpassing the 153.6 of ati's latest and greatest.
So, you have barely increased ram speed, same bus width... and the transistors on die are used up in "SHADERS" and ROPS....etc.
Where is all that extra shader processing going to go ?
Well, it goes to SSAA useage for instance, which provides ZERO visual quality improvement.
So, it goes to "cranking up the eye candy settings" at "not a very big framerate improvement".
--
So they just have to have a 384 or a 512 bus they are holding back. I dearly hope so.
They've already been losing a BILLION a year for 3+ years in a row, so the cost excuse is VERY VERY LAME.
I mean go check out the nvidia leaked stats, they've been all over for months - DDR5 and a 512 bit, with Multiple IMD, instead of the 5870 Single IMD.
If you want DOUBLE the performance wait for Nvidia. From DDR3 to DDR5, like going from 4850 to 4890, AND they (NVIDIA) have a whole new multiple instruction super whomp coming down the pike that is never done before, on their hated "gigantic brute force cores" (even bigger in the 40nm shrink -lol) that generally run 24C to 15C cooler than ati's electromigration heat generators.
---
So I mean add it up. Moving to DDR5, moving to multiple data, moving to 40nm, moving with 512 bit bus and AWESOME bandwidth, and the core is even bigger than the hated monster GT200. LOL
We're talking EPIC palmface.
--
In closing, buh bye ati !
silverblue - Thursday, September 24, 2009 - link
Let's wait for GT300 before we make any sweeping generalisations. The proof is in the pudding and it won't be long before we see it.And don't let the door hit you on the way out.
SiliconDoc - Thursday, September 24, 2009 - link
Oh mister, if we're waiting, that means NO BUYING the 5870, WAIT instead.Oh, yeah, no worries, it's not available.
---
Now, when my statements prove to be true, and your little crybaby snark with NO FACTS used for rebuttal are proven to be wasted stupidity, WILL YOU LEAVE AS YOU STATED YOU WANT ME TO ?
That's what I want to know. I want to know if your little wish applies to YOU.
Come on, I'll even accept a challenge on it. If I turn out to be wrong, I leave, if not you're gone.
If I'm correct, anyone waiting because of what I've pointed out, has been given an immense helping hand.
Which BY THE WAY, the entire article FAILED TO POINT OUT, because the red love goes so deep here.
-
But, you, the little red rooster ati fanner, wants me out.
ROFL - you people are JUST INCREDIBLE, it is absolutely incredible the crap you pull.
NOW, LET US KNOW WHAT LEAKED NVIDIA STATS I GOT INCORRECT WON'T YOU!?
No of course you won't !
silverblue - Friday, September 25, 2009 - link
Another problem I have with people like you is the unerring desire to rant and rave without reading things through. I said wait for GT300 before doing a proper comparison. Have you already forgotten the mess that was NV30? Paper specs do not necessarily equal reality. When the GT300 is properly previewed, even with an NDA in place, we can all judge for ourselves. People have a choice to buy what they like regardless of what you or I say.I'm not an ATI fanboy. I expended plenty of thought on what parts to get when I upgraded a few months back and that didn't just include CPU but motherboard and graphics. I was very close to getting a higher end Core2 Duo along with an nVidia graphics card; at the very least I considered an nVidia graphics card even when I decided on an AMD CPU and motherboard. In the end I felt I was getting better value by choosing an ATI solution. Doesn't make me a fanboy just because my money didn't end up on the nVidia balance sheet.
I'll take back the little comment about letting the door hit you on the way out. It wasn't designed to tell you to go away and not come back again, so my bad. I was annoyed at your ability to just attack a specific brand without any apparent form of objectivity. If you hate ATI, then you hate ATI, but do we really need to hear it all the time?
If the information you've posted about the GT300 is indeed accurate and comparable to what we've been told about the 58x0 series, then that's great, but you're going to need to lay it out in a more structured format so people can digest it more readily, as well as lay off the constant anti-ATI stance because appearing biased is not going to make people more receptive to your viewpoint. I remain sceptical that your leaked specs will end up being correct but in the end, GT300 is on its way and it'll be a monster regardless of whatever information you've posted here. I'm not going to pretend I know anything technical about GT300, but you must realise that what you've essentially done in this article is slate a working, existing product line that is being distributed to vendors as we speak in a manner that's much slower than ATI had intended yet you're attacking people for being interested in it over the GT300 which hasn't been reviewed yet, partly because you think the product is vapourware (which isn't really the case as people are getting hold of the 5870 but at a lower rate than ATI would like). Some people will choose to wait, some people will jump on the 58x0 bandwagon right now, but it's not for you to decide for them what they should buy.
Now relax, you're going to have a heart attack.
SiliconDoc - Wednesday, September 30, 2009 - link
What a LOAD OF CRAP.I don't have to outline anything, remember, ALL YOU PEOPLE cARE ABOUT IS GAMING FRAMERATE.
And that at "your price point" that doesn't include "the NVIDIA BALANCE SHEET". - which io of course, the STRANGEST WAY for a reddie to put it.
YOU JUST WANT ME TO SHUT UP. YOU DON'T WANT IT SAID. WE'LL I'M SAYING IT AGAIN, AND YOU FAILED TO ACCEPT MY CHALLENGE BECAUSE YOU'RE A CHICKEN, AND CENSOR !
---
Oh, do we have to hear it... blah blah blah blah...
--
YES SINCE THIS VERY ARTICEL WAS ABSOLUTELY IRRESPONSIBLE IN NOT PROPERLY ASSESSING THE COMPETITION.
CarrellK - Wednesday, September 23, 2009 - link
If a game ran almost entirely on the GPU, the scaling would be more of what you expect. You can put in a new GPU, but the CPU is no faster, main memory is no faster of bigger, the hard disk is no faster, PCIE is no faster, etc.The game code itself also limits scaling. For example the texture size can exceed the card's memory footprint, which results in performance sapping texture swaps. Each game introduces different bottlenecks (we can't solve them all).
We do our best to get linear scaling, but the fact is that we address less than a third of the game ecosystem. That we do better than 33% out of a possible 100% improvement is I think a testimony to our engineers.
BlackbirdCaD - Wednesday, September 23, 2009 - link
Why no load temp of 5870 in Crossfire??Load temp is much more important than idle temp.
There is lots of uninteresting stuff like soundlevel at idle with 5870 in crossfire, but the MOST IMPORTANT is missing: load temp with 5870 in crossfire.
SiliconDoc - Wednesday, September 23, 2009 - link
I just pulled up the chart on the 4870 CF, and although the 4870x2 was low 400's on load system power useage, the 4870 CF was 722 watts !So, I think your question may have some validity. I do believe the cards get a bit hotter in CF, and then you have the extra items on the PCB, the second slot used, the extra ram via the full amount on each card - all that adds up to more power useage, more heat in the case, and higher temps communicating with eachother. (resends for data on bus puases waitings, etc. ).
So there is something to your question.
---
Other than all that the basic answer is "red fan review site".
The ATI cards are HOTTER than the nvidia under load as a very, very wide general statement, that covers almost every card they both make, with FEW exceptions.