Arm's Cortex-A76 CPU Unveiled: Taking Aim at the Top for 7nm
by Andrei Frumusanu on May 31, 2018 3:01 PM EST- Posted in
- CPUs
- Arm
- Smartphones
- Mobile
- SoCs
- Cortex-A76
Performance & Power Projections
Now that we’ve had more insight into the A76’s microarchitecture – there’s always a disconnect between theoretical performance based on overlying µarch and how it ends up in practice. We’re first going to look at ISO-process and ISO-frequency comparisons which means the generational performance improvements between the cores with otherwise identical factors such as memory subsystems.
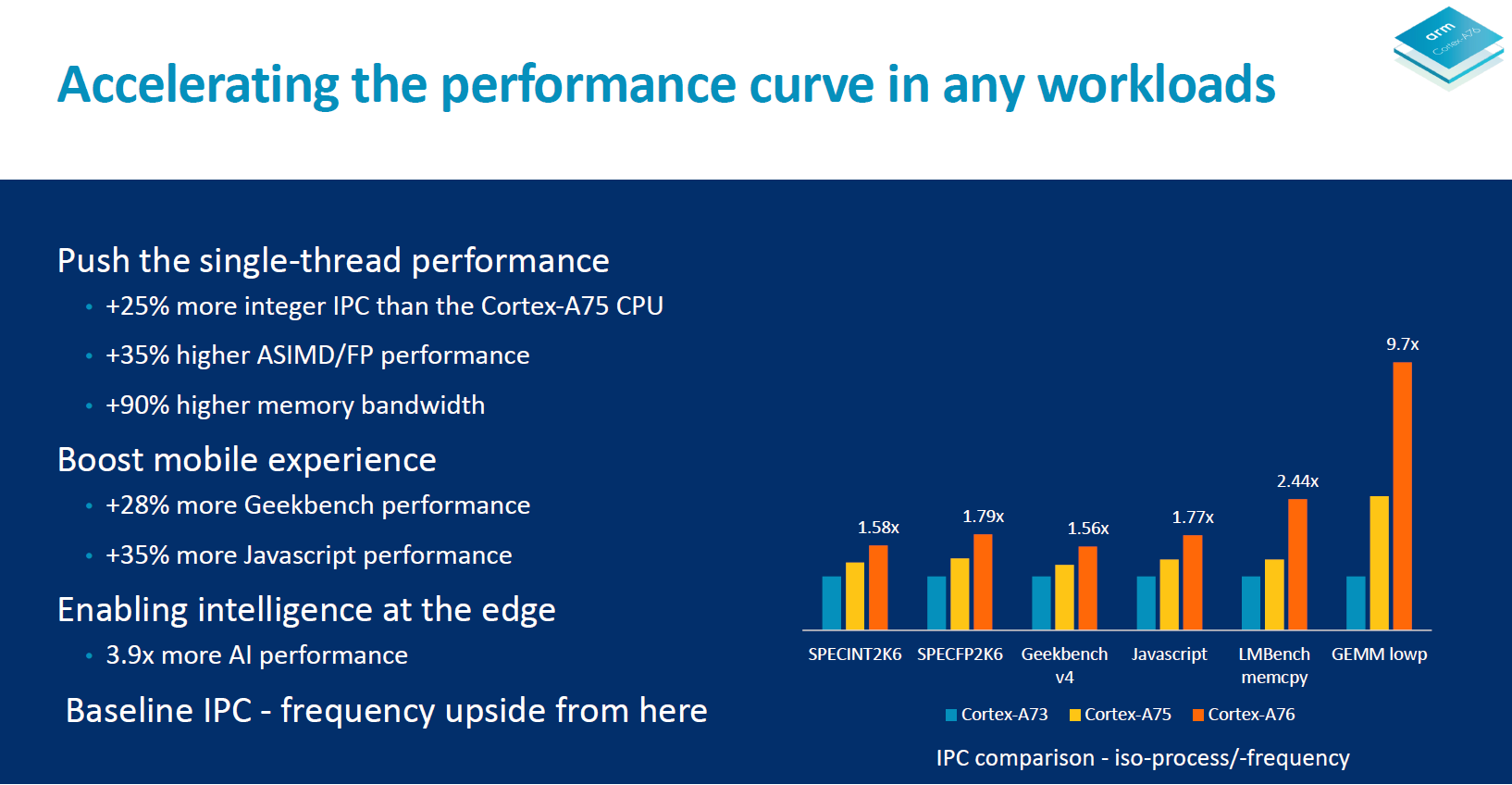
In terms of general IPC Arm promises a ~25% increase in integer workloads and a ~35% increase in ASIMD/floating point workloads. Together with up to 90% higher memory bandwidth figures compared to the A75 the A76 is then meant to provide around a 28% increase in GeekBench4 and 35% more JavaScript performance (Octane, JetStream). In AI inferencing workloads the doubled ASIMD 128-bit capabilities of the A76 serves to quadruple the general matrix multiply performance in half precision formats.
These performance figures are respectable but not quite earth-shattering considering the tone of the improvements of the µarch. However it’s to note that we’re expecting the A76 to come first be deployed in flagship SoCs on TSMC’s 7nm process which allows for increased clocks.

Here Arm’s projections is that we’ll be seeing the A76 clocked at up to 3GHz on 7nm, which in turn will result in higher improvements. Quoted figures are 1.9x in integer and 2.5x in floating point subscores of GeekBench4 while we should be expecting total score increases of 35%.
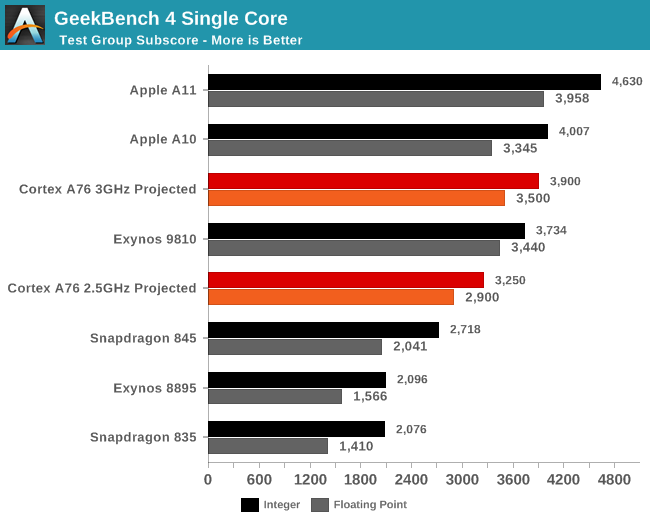
What this means in terms of absolute numbers is projected in the above graph. Baselining on the performance of the Snapdragon 835 and Snapdragon 845 a future SoC with an A76, 512KB L2’s and 2MB L3 would fall in around the GeekBench4 performance of the Exynos 9810 depending if the target 3GHz is reached.
In the past Arm has been overly optimistic when releasing frequency targets – for example the A73 was first projected at up to 2.8GHz and the Cortex A75 projected at up to 3GHz. In the end both ended up at no higher than 2.45GHz and 2.8GHz.
I’ve talked to a vendor about this and it seems Arm doesn’t take into consideration all corners when doing timing signoff, and in particular vendors have to take into consideration process variations which result in differently binned units, some of which might not reach the target frequencies. As mobile chips generally aren’t performance binned but rather power binned, vendors need to lower the target clock to get sufficient volume for commercialisation which results in slightly reduced clocks compared to what Arm usually talks about.
For the first A76 implementations in mobile devices I’m adamant that we won’t be seeing 3GHz SKUs but rather frequencies around 2.5GHz. Arm is still confident that we’ll see 3GHz SoCs but I’m going to be rather on the conservative side and be talking about 2.5GHz and 3GHz projections alongside each other, with the latter more of a projection of future higher TDP platforms.
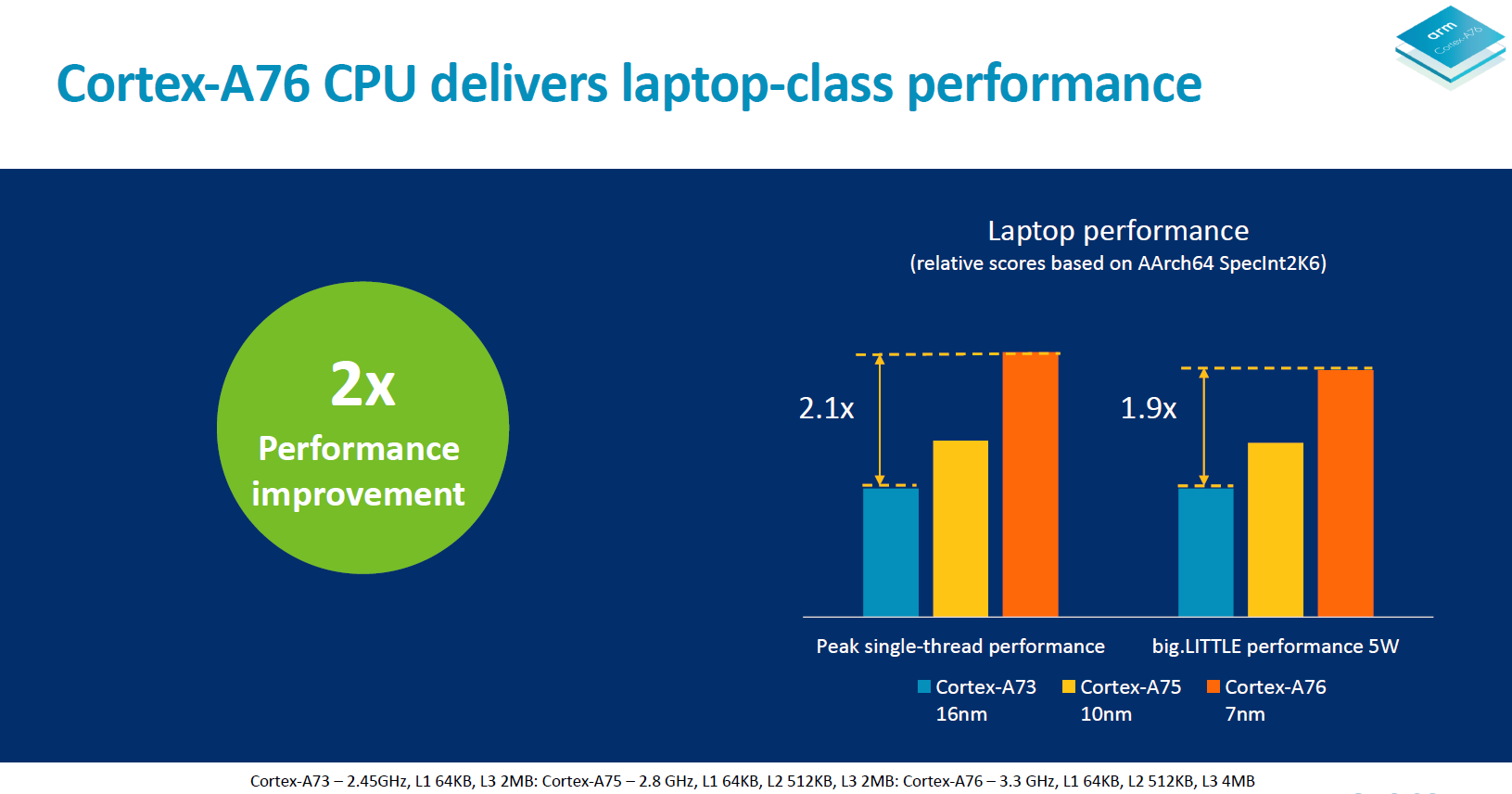
Arm also had a slide demonstrating absolute peak performance at frequencies of 3.3GHz. The important thing to note here was that this scenario exceeded 5W and the performance would be reduced to get under that TDP target. It wasn’t clear if this was SoC power or solely CPU power – I’ll follow up with a clarification after I reach out to Arm.

Obviously the most important metric here alongside the performance improvements is the power and efficiency targets. In target products comparing Cortex A75 on a 10nm process versus a Cortex A76 on a 7nm process under the same 750mW/core power budget, the Cortex A76 delivers 40% more performance.
In terms of energy efficiency, a 7nm A76 at a performance target of 20 SPECint2006 of an A75 on 10nm (meaning maximum performance at 2.8GHz) is said to use half the amount of energy.
What is important in all these metrics again is that we weren’t presented an ISO-process comparison or a comparison at maximum performance of the A76 at 3GHz, so we’re left with quite a bit of guesswork in terms of projecting the end energy efficiency difference in products. TSMC promises a 40% drop in power versus 10FF. We haven’t seen an A75 implemented on a TSMC process to date so the best baseline we have is Qualcomm’s Snapdragon 845 on Samsung 10LPP which should slightly outperform 10FF.
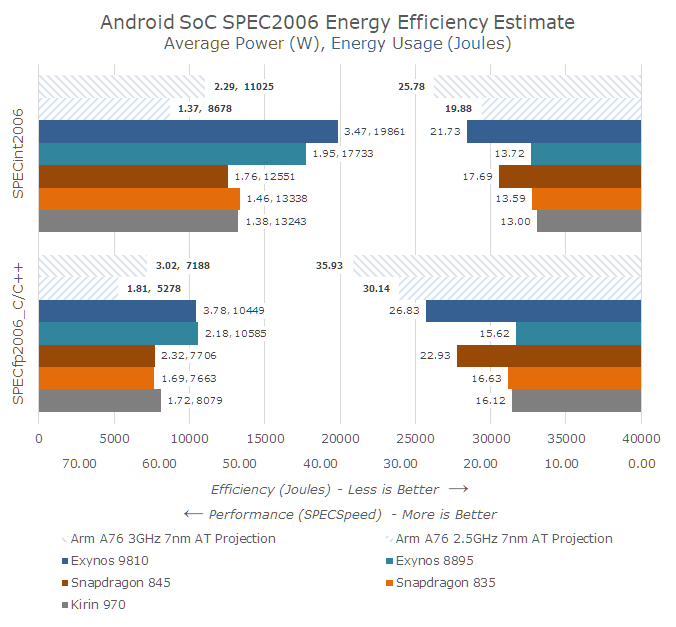
Going through my projected data on one side we have performance on the right side: I baselined the SPECspeed scores on the average of the Snapdragon 835 and Kirin 970 measured results and applied Arm’s projected IPC claims and scaled the scores for frequency. For the 3GHz A76 projection this gets us the near 2x performance improvements in SPECint2006 vs the A73 generation of cores.
In terms of power efficiency, there’s more guesswork as the only real figure we have is as earlier stated the process scaled efficiency figures. Arm quoted a performance target of 20 SPECint2006 which I suspect is a 2.8GHz A75 run with GCC compiled benchmark binaries which have an advantage over my LLVM figures. If Arm wanted to compare against the Snapdragon 845 this matches roughly a 2.4GHz A76. Accounting for the process power improvement this roughly leaves a ~15% microarchitectural advantage for the A76. However as the A76 is targeted to perform 35% higher, and as we’ve seen in the past performance increases through clock don’t scale linearly with power, the power and efficiency advantages would very quickly degrade at peak performance.
Taking all factor into account as best as I could, we should be seeing 7nm A76 based SoCs beat slightly beat the energy efficiency of current Arm SoCs in terms of absolute energy usage at peak performance, a metric which is important as it is directly proportional to a device’s battery life. At a more conservative 2.5GHz clock this energy efficiency advantage would be greater and around 30% less energy than current generation A73 and A75 SoCs.
So on one hand the A76 would be extremely energy efficient, but also it could very well be a thermally constrained design as its peak performance we’d be seeing quite higher TDP figures. Arm states that the A76 is meant to run at full frequency in quad-core mode, however that claim is limited to larger form-factors, as for mobile devices, based on what I’m hearing vendors, will need to tone it down to lower clocks in order to fit smartphone designs.
Again the projection here contain a lot of variables and I’m erring towards the more conservative side in terms of performance and efficiency- however it’s clear that the jump will be significant in whichever way vendors will decide to push the A76 in (Performance or efficiency).














123 Comments
View All Comments
techconc - Tuesday, June 5, 2018 - link
" A11 is no match in speed and performance versus SD845 and Exynos powered Android phones today"Huh? Benchmarks do not support your claim.
name99 - Friday, June 1, 2018 - link
This assumption makes two mistakes.The first is to assume that ONE metric (in this case 4-wide front end) is the PRIMARY determinant of performance. Even Apple's (A11) IPC (over a wide range of code) is about maybe 2.7. This means on average less than 3 of those 6 execution units are being used per cycle. IF other parts of the core uncache could be PERFECTED on a 4 wide design so that EVERY cycle 4 instructions executed, it would clearly surpass the A11 in IPC.
The problem, of course, is just how hard it is to prevent cycles where NOTHING executes and cycles where only a few (one or two) instructions execute. Reducing these are where most of the magic is --- and you won't see details of that it in an article like this; rather it's in that painstaking rooting out hundreds of small inefficiencies that the article talked about.
To give just one example -- no-one is talking about the clustered page tables. This is a very cool idea which relies on the fact that most of the time the OS page allocator allocates a number of pages contiguously in virtual AND physical space, and with the same permissions. If that is so, the same page entry can correspond to multiple contiguous pages (in the academic literature, usually up to 8). This gives you a substantial increase in TLB reach at a very minor increase in TLB bits.
(I can find no info as to whether Intel does this. I SUSPECT Apple used to do this in their earlier [and probably even A11] cores. There are very recent even better ideas in the academic literature that might, perhaps, have made it to the A12 core.)
Second mistake you make is to ignore frequency. A9 ran at 1.85 GHz, A10 at 2.35 GHz. The A76 will likely run at 3GHz.
tipoo - Tuesday, September 4, 2018 - link
And yet, here we are with single core results at around 60% that of the A11. Taking their own numbers at face value, a 56% increase over the A73 in GB4 results in 2800.Yes, I used a very simplistic one dimensional comparison, and there's a whole lot more to it. However, core complexity does go up almost exponentially with width, and so it does point to what ballpark they were aiming at. A76 was never going to beat the A11 per core because it was never aimed at it.
colinisation - Thursday, May 31, 2018 - link
Hi Andrei,Is this core the one referred to as Ares on roadmaps?
Been waiting years for this one if it is.
Andrei Frumusanu - Thursday, May 31, 2018 - link
Yes in practical terms - no in actual terms. You'll likely hear more about this in the future.tuxRoller - Friday, June 1, 2018 - link
Ok, now you've incepted the idea that ARM is going to announce a dedicated server-class chip (maybe even a tease of SVE.....)name99 - Friday, June 1, 2018 - link
I agree with your point (ARM will release a server chip, essentially based on this core).Remember that GB4 is scaled to 4000 represents an i7-6600U (Skylake, 3.4GHz, 4MiB L3, 15W).
So A76 is essentially at that level (slightly worse FP, but many server tasks will not care).
To the extent that that Skylake at 3.4GHz is an acceptable Server class core, ARM could dump some large number of A76 on a die and be in the same sort of space as dearly-departed Centriq and ThunderX2.
They likely would have to beef up their NoC one way or another, and tweak the caching and memory systems, the usual server additions.
But I assume they didn't put all that effort into "lowest possible latency for hypervisor activity" on the theory that hypervisor performance on smartphones is THE next big thing...
joe_85 - Thursday, May 31, 2018 - link
I am sure people will disagree with me because people love to argue. Andrei, I like your writing and overall thoroughness but a few critiques here. The charts you make are extremely unpleasant to look at and do not lend themselves to a quick assessment of the data.First of all the color coded stripes in the legend for the A76 projections is not even decipherable, and the actual bars are on the chart are difficult to see. Secondly, why are you color coding them at all? Just put processor names to the left of the bars and the benchmark name above the bars.
Additionally are the bars in any particular order? If they are I certainly can't tell, they should be relative to the performance OR the efficiency.
Other constructive criticism would be that adding some additional subheadings within your articles would make it feel like a more solid piece.
Keep up the good work.
jospoortvliet - Wednesday, June 6, 2018 - link
Loving to argue or not, the performance vs efficiency graphs are rather unique and very clever, I have not seen any design that so clearly shows how different SOC's compare at both. Yes it takes a few mins before you can read them I am sorry that the world is so complicated. But they work very well if you just use that gray matter a bit.syxbit - Thursday, May 31, 2018 - link
As an Android user, I continue to be disappointed with QCOMM, Arm (and Nvidia for dropping out) at how far ahead Apple in single threaded perf.