AMD Zen Microarchiture Part 2: Extracting Instruction-Level Parallelism
by Ian Cutress on August 23, 2016 8:45 PM EST- Posted in
- CPUs
- AMD
- x86
- Zen
- Microarchitecture
Fetch
For Zen, AMD has implemented a decoupled branch predictor. This allows support to speculate on incoming instruction pointers to fill a queue, as well as look for direct and indirect targets. The branch target buffer (BTB) for Zen is described as ‘large’ but with no numbers as of yet, however there is an L1/L2 hierarchical arrangement for the BTB. For comparison, Bulldozer afforded a 512-entry, 4-way L1 BTB with a single cycle latency, and a 5120 entry, 5-way L2 BTB with additional latency; AMD doesn’t state that Zen is larger, just that it is large and supports dual branches. The 32 entry return stack for indirect targets is also devoid of entry numbers at this point as well.
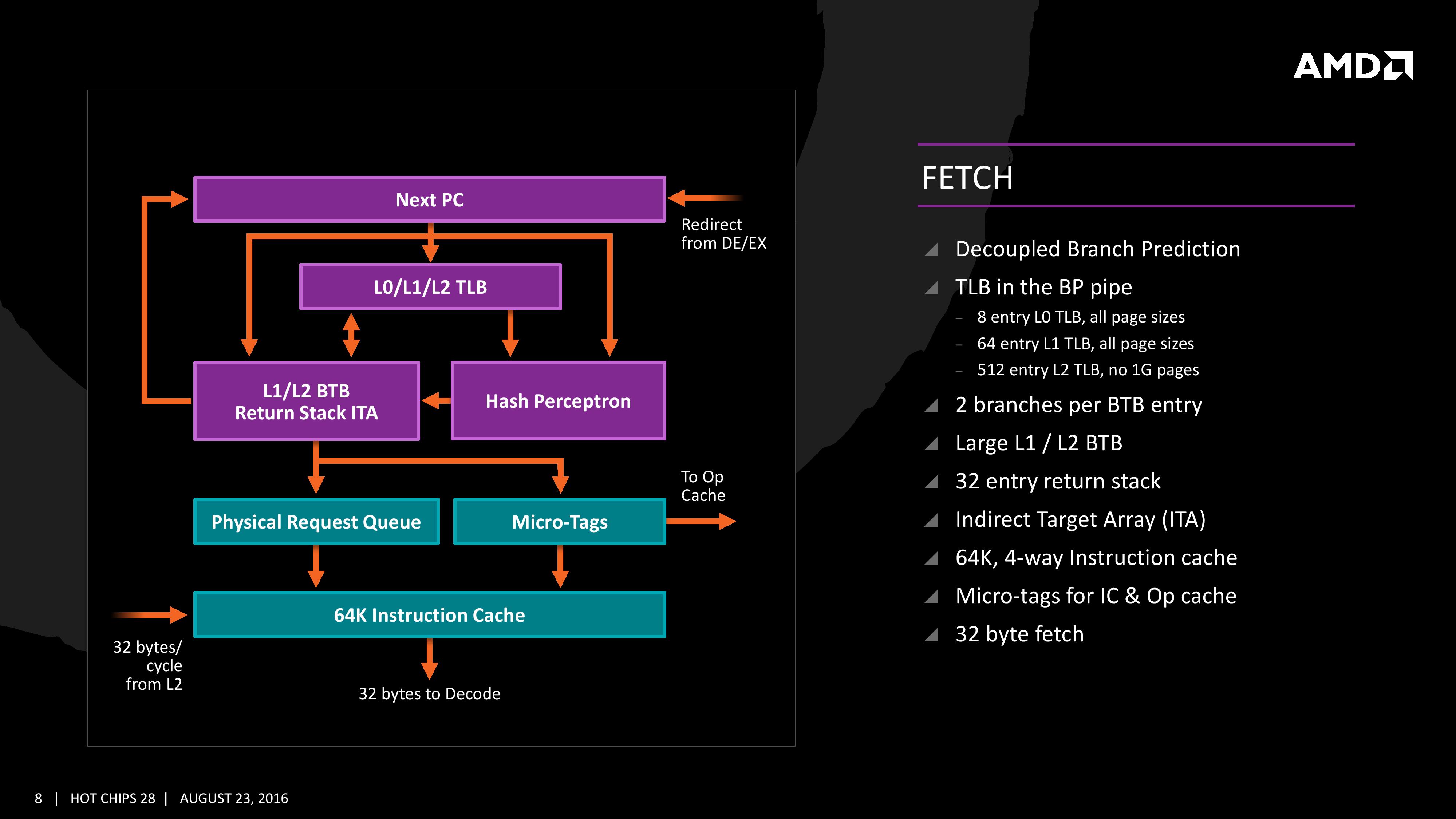
The decoupled branch predictor also allows it to run ahead of instruction fetches and fill the queues based on the internal algorithms. Going too far into a specific branch that fails will obviously incur a power penalty, but successes will help with latency and memory parallelism.
The Translation Lookaside Buffer (TLB) in the branch prediction looks for recent virtual memory translations of physical addresses to reduce load latency, and operates in three levels: L0 with 8 entries of any page size, L1 with 64 entries of any page size, and L2 with 512 entries and support for 4K and 256K pages only. The L2 won’t support 1G pages as the L1 can already support 64 of them, and implementing 1G support at the L2 level is a more complex addition (there may also be power/die area benefits).
When the instruction comes through as a recently used one, it acquires a micro-tag and is set via the op-cache, otherwise it is placed into the instruction cache for decode. The L1-Instruction Cache can also accept 32 Bytes/cycle from the L2 cache as other instructions are placed through the load/store unit for another cycle around for execution.
Decode
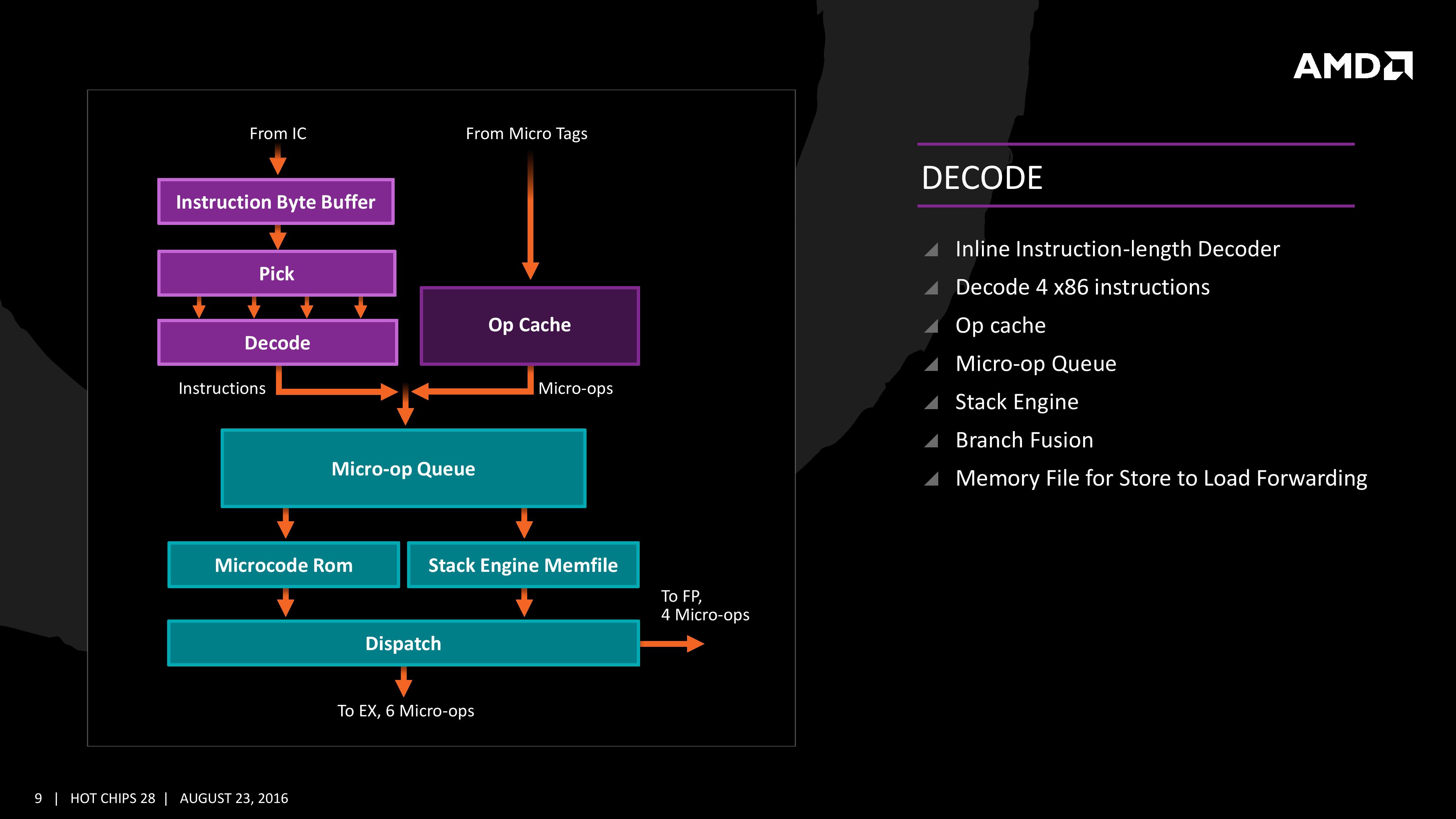
The instruction cache will then send the data through the decoder, which can decode four instructions per cycle. As mentioned previously, the decoder can fuse operations together in a fast-path, such that a single micro-op will go through to the micro-op queue but still represent two instructions, but these will be split when hitting the schedulers. The purpose of this allows the system to fit more into the micro-op queue and afford a higher throughput when possible.
The new Stack Engine comes into play between the queue and the dispatch, allowing for a low-power address generation when it is already known from previous cycles. This allows the system to save power from going through the AGU and cycling back around to the caches.
Finally, the dispatch can apply six instructions per cycle, at a maximum rate of 6/cycle to the INT scheduler or 4/cycle to the FP scheduler. We confirmed with AMD that the dispatch unit can simultaneously dispatch to both INT and FP inside the same cycle, which can maximize throughput (the alternative would be to alternate each cycle, which reduces efficiency). We are told that the operations used in Zen for the uOp cache are ‘pretty dense’, and equivalent to x86 operations in most cases.








106 Comments
View All Comments
Krysto - Wednesday, August 24, 2016 - link
I think PCs in general run better on four cores than on two, even if most apps themselves can't take advantage of them, although I think in the next 5 years most new games will take advantage of 8 threads. But otherwise, it's just good for multitasking.tarqsharq - Wednesday, August 24, 2016 - link
I had an argument with one fellow on the internet regarding i7 being plenty for whatever I was doing in terms of core count. But streaming a show on one monitor while playing Overwatch was hitting 70%+ CPU usage, with all logical cores being 60-70% utilized consistently, with spikes up to 90%+.That was on my i7-4770K to be specific, running 1080P on a 144hz monitor for Overwatch, and Crunchyroll for 1080P anime stream on the second monitor.
So some games combined with slight multitasking is already taxing the 4C/8T environment.
galta - Wednesday, August 24, 2016 - link
And how much multitasking are we really using? If I had to guess, I would say not much, on average.You might have some folks here and there using it, but regular users need something between two and four cores, just as you said.
You have the OS, the software you're using, be it a game or not, plus everything that's running behind the scenes, including Windows ineficiencies, and that's it. But for some weird guy that spends his day on 7zip, more than 4 cores brings no extra power.
This is the reason why, no matter how excited we might get with 10 cores (I would love one, even if for bragging rights only), our i5s are enough for what we do.
Maybe in 5 years from now games will be multithreaded, but I'm not holding my breath: something similar was said 5 years ago, and here we are.
At the end of the day, we still need improvement in per core performance.
looncraz - Wednesday, August 24, 2016 - link
Browsers are becoming better and better at using more cores... and we're all running tens of processes in the background, some of which fire interrupts on a CPU. More cores allows for more going on at the same time without interruptions. You can actually feel this moving to an eight-core FX-8350 from a quad core i5... those eight cores provide a somewhat smoother multi-tasking environment, despite each core being slower and the overall performance being lower.Humans are simply sensitive to changes in timing - more cores and more threads reduces the variability in timing, which improves perceived performance.
galta - Thursday, August 25, 2016 - link
Hum....I don't know many people who share your opinion about FX-8350 vs i5.
Anyway, we have been multitasking for a while, a least to some extent: OS, Word, anti-virus, browser. The question is: for this light multitasking, are we better off with several cores with poor performance/core, or with less cores but with great performance/core.
Reviews and actual people generally prefer the later.
As of browsers, great news that they are improving, but download/upload speed is by far the most important factor in users experience.
Alexvrb - Sunday, August 28, 2016 - link
Download speed is fine for web browsing if you've got something faster than DSL. How much data exactly do you think you're consuming while browsing the web? Outside of streaming videos you won't use up a ton of bandwidth.Cooe - Thursday, May 6, 2021 - link
I know this is ANCIENT, but how the hell did you not realize that multi-core optimization was so bad only because nobody could afford greater than >4 core CPU's pre-Zen??? Modern games run freaking TERRIBLE now on 4c/4t i5's.Notmyusualid - Wednesday, August 24, 2016 - link
No, nope, nej, and nein.I see (FEEL) tangible improvements in my computing ever since dropped 2 cores for 4.
And it looks like others below agree....
galta - Thursday, August 25, 2016 - link
I believe you do, for the sweet spot is now around 4 cores, as I said before.The question is: do you believe that your experience will improve significantly if you mo to 6 or 8 cores?
Probably not, unless you spend your day zipping files or rendering images.
Alexvrb - Sunday, August 28, 2016 - link
They said the same thing about quad cores, and dual cores before that. AMD has to get on top of the curve, not behind it. They'll offer quad cores for more mainstream systems, and 8 for performance rigs. More for servers, and potentially less for low-power and/or low-cost.