AMD Zen Microarchiture Part 2: Extracting Instruction-Level Parallelism
by Ian Cutress on August 23, 2016 8:45 PM EST- Posted in
- CPUs
- AMD
- x86
- Zen
- Microarchitecture
Fetch
For Zen, AMD has implemented a decoupled branch predictor. This allows support to speculate on incoming instruction pointers to fill a queue, as well as look for direct and indirect targets. The branch target buffer (BTB) for Zen is described as ‘large’ but with no numbers as of yet, however there is an L1/L2 hierarchical arrangement for the BTB. For comparison, Bulldozer afforded a 512-entry, 4-way L1 BTB with a single cycle latency, and a 5120 entry, 5-way L2 BTB with additional latency; AMD doesn’t state that Zen is larger, just that it is large and supports dual branches. The 32 entry return stack for indirect targets is also devoid of entry numbers at this point as well.
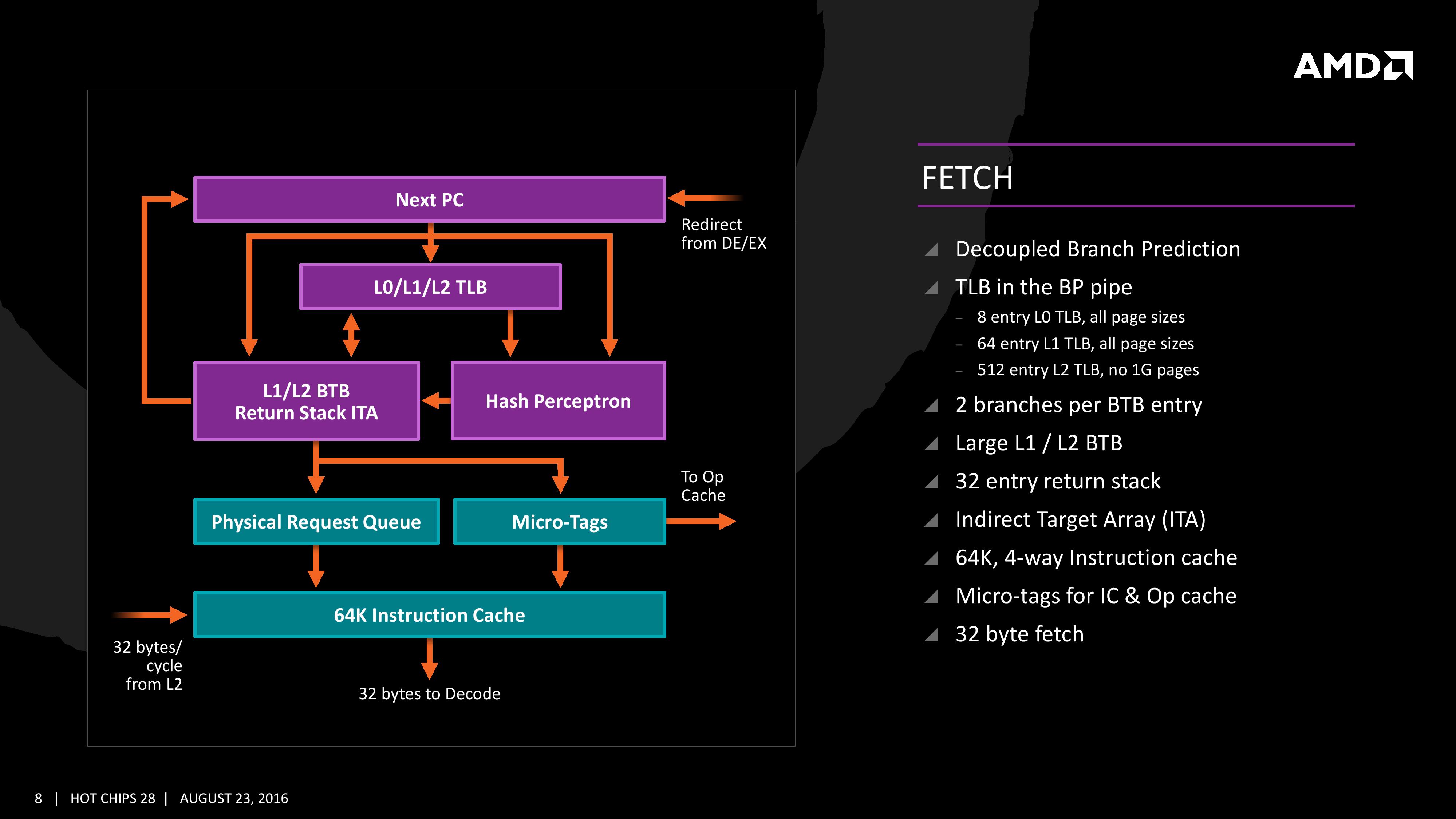
The decoupled branch predictor also allows it to run ahead of instruction fetches and fill the queues based on the internal algorithms. Going too far into a specific branch that fails will obviously incur a power penalty, but successes will help with latency and memory parallelism.
The Translation Lookaside Buffer (TLB) in the branch prediction looks for recent virtual memory translations of physical addresses to reduce load latency, and operates in three levels: L0 with 8 entries of any page size, L1 with 64 entries of any page size, and L2 with 512 entries and support for 4K and 256K pages only. The L2 won’t support 1G pages as the L1 can already support 64 of them, and implementing 1G support at the L2 level is a more complex addition (there may also be power/die area benefits).
When the instruction comes through as a recently used one, it acquires a micro-tag and is set via the op-cache, otherwise it is placed into the instruction cache for decode. The L1-Instruction Cache can also accept 32 Bytes/cycle from the L2 cache as other instructions are placed through the load/store unit for another cycle around for execution.
Decode
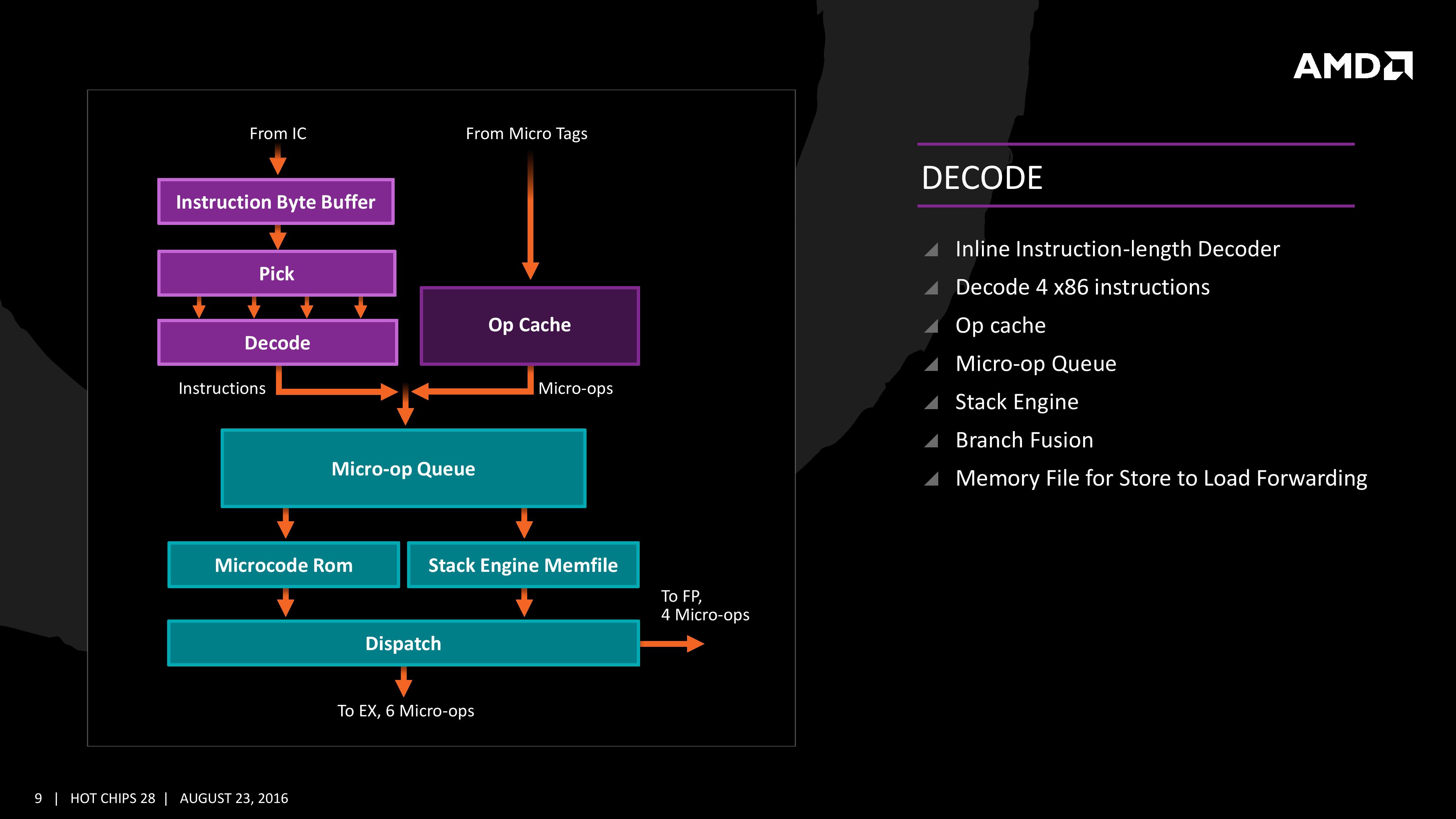
The instruction cache will then send the data through the decoder, which can decode four instructions per cycle. As mentioned previously, the decoder can fuse operations together in a fast-path, such that a single micro-op will go through to the micro-op queue but still represent two instructions, but these will be split when hitting the schedulers. The purpose of this allows the system to fit more into the micro-op queue and afford a higher throughput when possible.
The new Stack Engine comes into play between the queue and the dispatch, allowing for a low-power address generation when it is already known from previous cycles. This allows the system to save power from going through the AGU and cycling back around to the caches.
Finally, the dispatch can apply six instructions per cycle, at a maximum rate of 6/cycle to the INT scheduler or 4/cycle to the FP scheduler. We confirmed with AMD that the dispatch unit can simultaneously dispatch to both INT and FP inside the same cycle, which can maximize throughput (the alternative would be to alternate each cycle, which reduces efficiency). We are told that the operations used in Zen for the uOp cache are ‘pretty dense’, and equivalent to x86 operations in most cases.








106 Comments
View All Comments
atlantico - Friday, August 26, 2016 - link
Wow looncraz!! Really cool effort you made :)Spunjji - Saturday, August 27, 2016 - link
You numbers are different to everyone else's. Given that you don't cite any of your sources I believe everyone else.Krysto - Wednesday, August 24, 2016 - link
I would hope they try to double the cores of Intel for notebooks.Dual-core Zen without SMT will DESTROY Intel's Atom-based Celerons and Pentiums at the low-end. There will be absolutely ZERO reason to get a Celeron or Pentium notebooks once Zen appears on the market at that price range.
But at the Core i3 and Core i5 levels, I was hoping AMD would price a quad-core Zen with no SMT against dual-core Core i3 and Core i5, and a quad-core Zen with SMT against Intel's quad-core (no HT) Core i5, and finally 8-core with and without SMT variants against Intel's quad-core Core i7 chips (with HT).
If they can basically double the cores compared to what Intel has to offer at around the same price level, and maybe with only slightly worse single-thread performance and slightly worse power consumption, AMD's chips should be a NO-BRAINER. The value would be incredible, and it would push the market towards having powerful quad-core chips by default for most PCs. Intel is going to HATE that, because it would seriously cut into their profits. So AMD could use that strategy to both offer great value products and hurt Intel significantly.
looncraz - Wednesday, August 24, 2016 - link
AMD is not seeking the low end, they are trying to redefine AMD as the top-tier CPU company they once were. They are aiming for the top and the bulk of the market.Zen+'s 15% IPC improvement over Zen might just give them the performance crown, but I'm sure Intel has taken note and planned accordingly.
zaza - Wednesday, August 24, 2016 - link
but the AMD CCX module is a quad core module. i am not sure if it is easy for AMD to just remove two.looncraz - Wednesday, August 24, 2016 - link
Very easy, you just fuse off the defective core, that's the beauty of independent cores. The core complex just shares a common data bus and third level cache. Disabling a core in the complex will simply have it not ask for data on the common data bus. The L3 cache may or may not be cut down (probably will be).H2323 - Wednesday, August 24, 2016 - link
"While Zen is initially a high-performance x86 core at heart, it is designed to scale all the way from notebooks to supercomputers, or from where the Cat cores (such as Jaguar and Puma) were all the way up to the old Opterons and beyond, all with at least +40% IPC."https://www.youtube.com/watch?v=eUSJfGehKDQ
In the video its more than 40% across all of internal texting.
Vigilant007 - Saturday, August 27, 2016 - link
I don't know if AMD will ever have a major win as far as the PC industry again. Realistically they'll end up focusing on building custom x86 for consoles, and server chips. I can also see them exploiting their ability to do x86 to design custom chips for Apple.AMD could end up being a fantastic acquisition target as well.
Tuna-Fish - Tuesday, August 23, 2016 - link
From page 3:> and L2 with 512 entries and support for 4K and 256K pages only.
Surely you meant 4k and 2MB pages only?
deltaFx2 - Tuesday, August 23, 2016 - link
Ian, an error here: "It also states that the L3 is mostly inclusive of the L2 cache, which stems from the L3 cache as a victim cache for L2 data." A victim L3 is by definition an exclusive cache (as you note elsewhere). Also I don't understand why you have the impression that a victim cache is less efficient than an inclusive cache. As you note, an inclusive cache has to keep duplicate copies of data in L2 and L3 whereas an exclusive cache stores exactly 1 copy (either L2 or L3 but never both). In an exclusive cache hierarchy, a cache block is inserted into the L2, and when evicted, is put into the L3. In an inclusive cache hierarchy, a cache block is inserted both into the L2 and L3. Doesn't the exclusive hierarchy make better use of space? Incidentally, AMD has done exclusive caches since K8 at least. This isn't new.