AMD Zen Microarchiture Part 2: Extracting Instruction-Level Parallelism
by Ian Cutress on August 23, 2016 8:45 PM EST- Posted in
- CPUs
- AMD
- x86
- Zen
- Microarchitecture
The Core Complex, Caches, and Fabric
Many core designs often start with an initial low-core-count building block that is repeated across a coherent fabric to generate a large number of cores and the large die. In this case, AMD is using a CPU Complex (CCX) as that building block which consists of four cores and the associated caches.
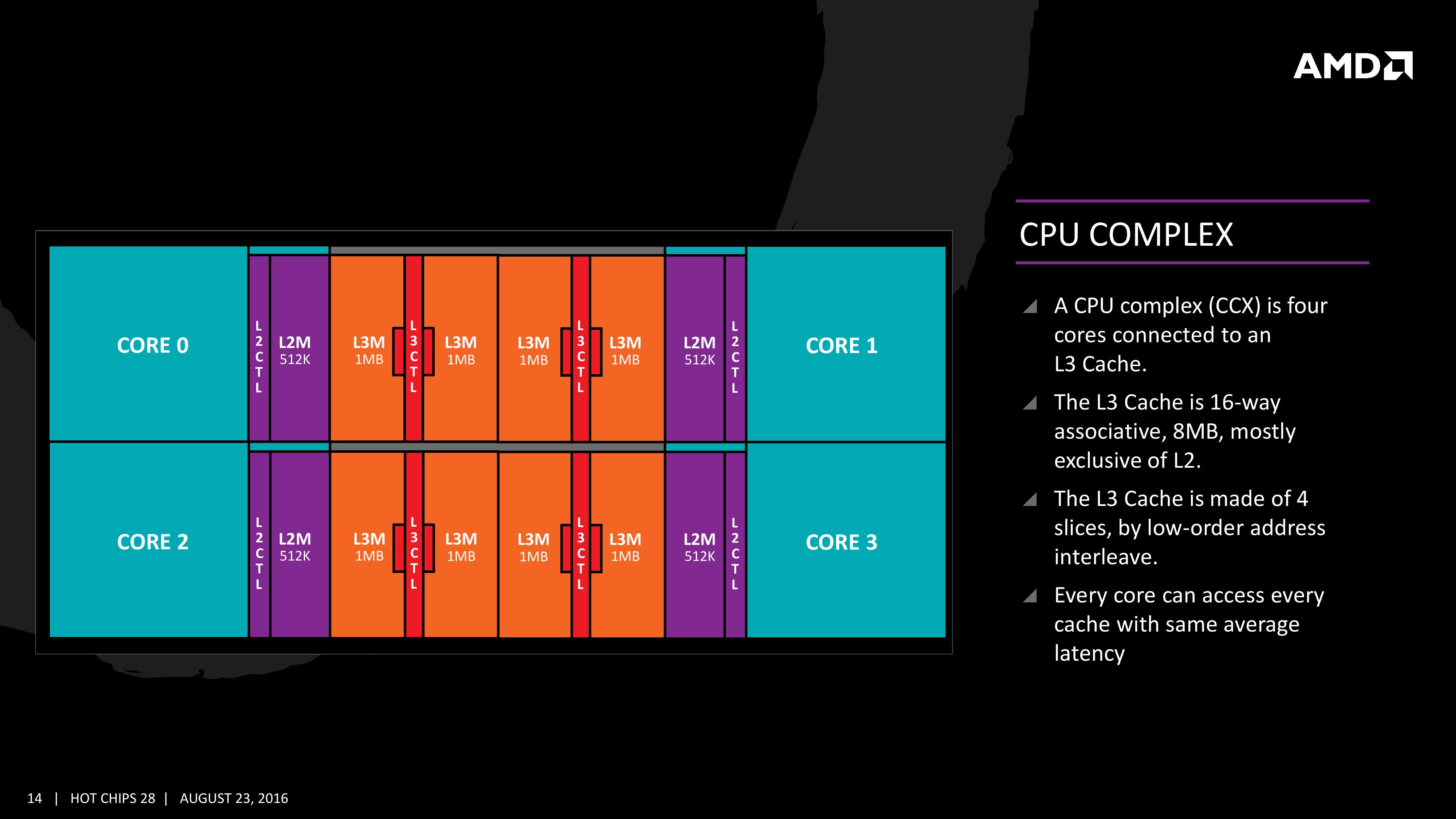
Each core will have direct access to its private L2 cache, and the 8 MB of L3 cache is, despite being split into blocks per core, accessible by every core on the CCX with ‘an average latency’ also L3 hits nearer to the core will have a lower latency due to the low-order address interleave method of address generation.
The L3 cache is actually a victim cache, taking data from L1 and L2 evictions rather than collecting data from prefetch/demand instructions. Victim caches tend to be less effective than inclusive caches, however Zen counters this by having a sufficiency large L2 to compensate. The use of a victim cache means that it does not have to hold L2 data inside, effectively increasing its potential capacity with less data redundancy.
It is worth noting that a single CCX has 8 MB of cache, and as a result the 8-core Zen being displayed by AMD at the current events involves two CPU Complexes. This affords a total of 16 MB of L3 cache, albeit in two distinct parts. This means that the true LLC for the entire chip is actually DRAM, although AMD states that the two CCXes can communicate with each other through the custom fabric which connects both the complexes, the memory controller, the IO, the PCIe lanes etc.
One interesting story is going to be how AMD’s coherent fabric works. For those that follow mobile phone SoCs, we know fabrics and interconnects such as CCI-400 or the CCN family are optimized to take advantage of core clusters along with the rest of the chip. A number of people have speculated that the fabric used in AMD’s new design is based on HyperTransport, however AMD has confirmed that they are not using HyperTransport here for Zen. More information on the fabric may come out as we nearer the launch, although this remains one of the more mysterious elements to the design at this stage.
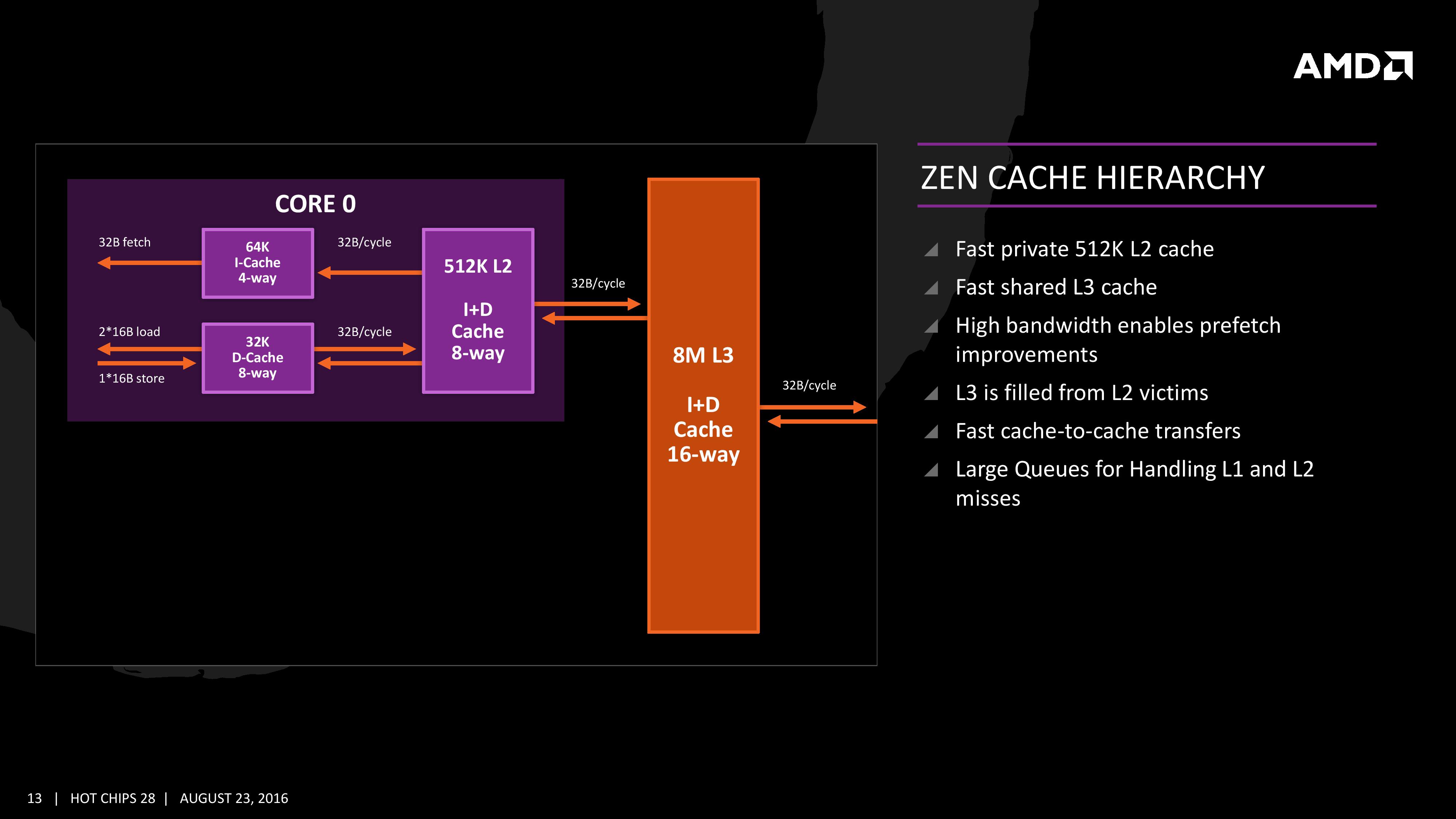
The cache representation in the new presentation at Hot Chips is almost identical to that in midweek, showing L1 and L2 in the core with 8MB of L3 split over several cores. AMD states that the L1 and L2 bandwidth is nearly double that of Excavator, with L3 now up to 5x for bandwidth, and that this bandwidth will help drive the improvements made on the prefetch side. AMD also states that there are large queues in play for L1/L2 cache misses.








106 Comments
View All Comments
tipoo - Wednesday, August 31, 2016 - link
Meanwhile Intel worked on shortening pipelines...Curious to see how this will go, hope for AMDs sake it's competitive.masouth - Friday, September 2, 2016 - link
I hope it works out for AMD as well but reading about long pipelines and higher freqs always reminds me of the P4 days/shudder
junky77 - Wednesday, August 24, 2016 - link
The problem is now having Intel/AMD provide fast enough CPUs to feed the new GPUs that don't seem to slow down..gamerk2 - Wednesday, August 24, 2016 - link
Pretty much anything from an i7 920 onward can keep GPUs fed these days. For gaming purposes, CPUs haven't been the bottleneck for over a decade. That's why you don't see significant improvement from generation to generation, since our favorite CPU tests happen to be with GPU sensitive benchmarks.Death666Angel - Thursday, August 25, 2016 - link
The story is much more complicated than you are making it seem:https://www.youtube.com/watch?v=frNjT5R5XI4
tipoo - Wednesday, August 31, 2016 - link
A Skylake i3 presents better frametimes than old i7s like the 920 or 2500Krhysiam - Wednesday, August 24, 2016 - link
40% over Excavator probably still puts it well behind even Haswell on IPC. If I'm looking at it right, Bench on this site has 4 single threaded tests (3 Cinebench versions and 3D Particle...). I crunched some numbers and found that if you add 40% to Excavator @ 4Ghz (X4 860 turbo), it still loses to Skylake @ 3.9Ghz (turbo) by between 32% & 39% across the four benchmarks. Haswell @ 3.9Ghz (turbo) would still be faster by 24% to 33%.If it really is 40% minimum, AND they can sustain decent clock speeds, then that's at least enough to be in the ballpark, but it's still well short of Intel in those few benchmarks at least. TBH I don't know how representative those benchmarks are of overall single-threaded performance.
It could well be a case of AMD offering significantly poorer lightly threaded performance, but a genuine 8 core CPU at an affordable (i.e. not $1000) price.
gamerk2 - Wednesday, August 24, 2016 - link
I except the following:~40% average IPC gain in FP workloads
~30% average IPC gain in INT workloads
~20% clock speed reduction.
Average performance increase: ~15-20%, or Ivy Bridge i7 level performance.
Michael Bay - Wednesday, August 24, 2016 - link
Well, nothing stops them from their own brand of tick-tock, especially considering largely stagnant intel IPC.looncraz - Wednesday, August 24, 2016 - link
40% over Excavator is almost exactly Haswell overall, particularly once you shape the performance to match what is known about Zen.http://excavator.looncraz.net/