AMD Zen Microarchiture Part 2: Extracting Instruction-Level Parallelism
by Ian Cutress on August 23, 2016 8:45 PM EST- Posted in
- CPUs
- AMD
- x86
- Zen
- Microarchitecture
Fetch
For Zen, AMD has implemented a decoupled branch predictor. This allows support to speculate on incoming instruction pointers to fill a queue, as well as look for direct and indirect targets. The branch target buffer (BTB) for Zen is described as ‘large’ but with no numbers as of yet, however there is an L1/L2 hierarchical arrangement for the BTB. For comparison, Bulldozer afforded a 512-entry, 4-way L1 BTB with a single cycle latency, and a 5120 entry, 5-way L2 BTB with additional latency; AMD doesn’t state that Zen is larger, just that it is large and supports dual branches. The 32 entry return stack for indirect targets is also devoid of entry numbers at this point as well.
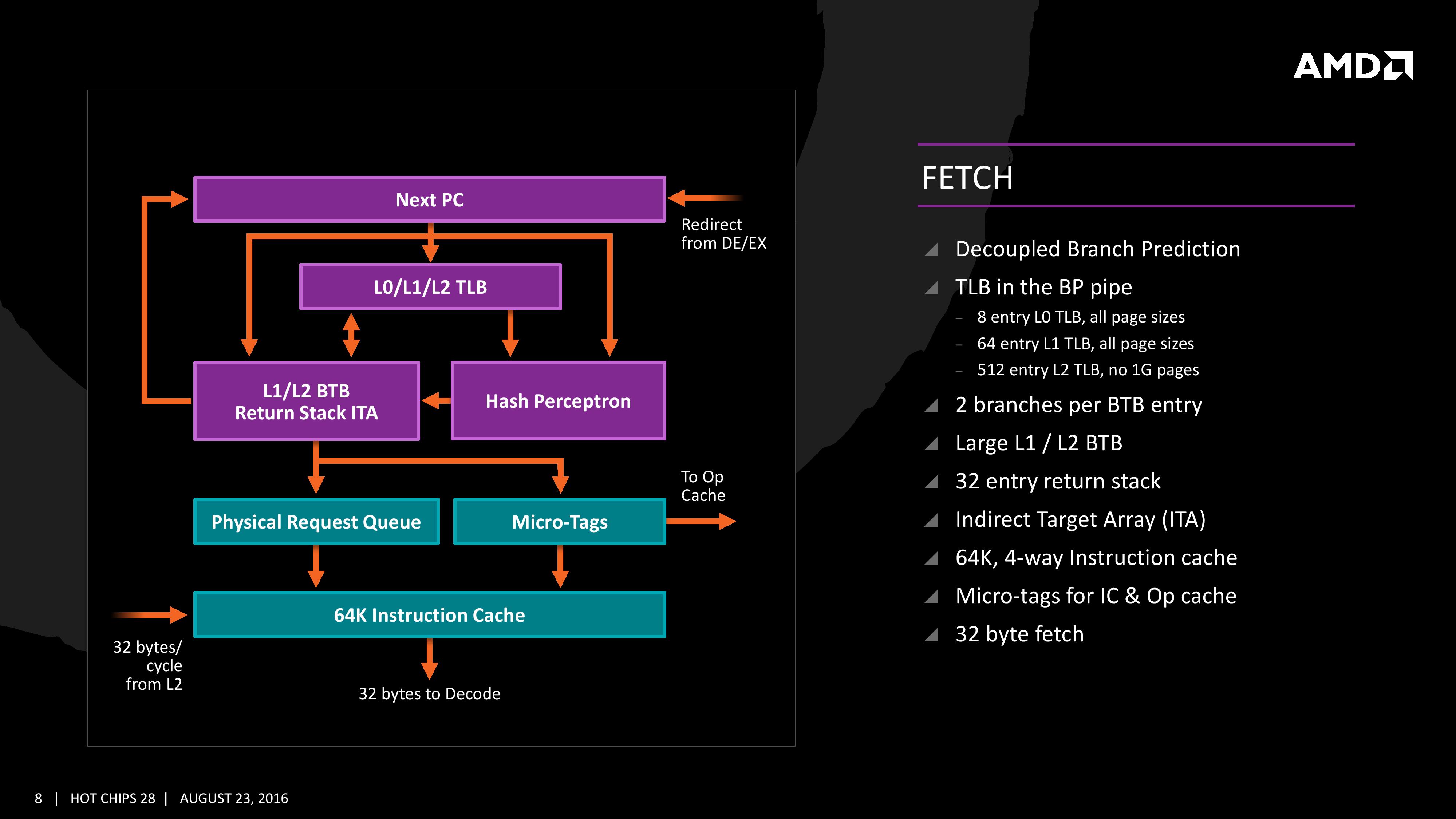
The decoupled branch predictor also allows it to run ahead of instruction fetches and fill the queues based on the internal algorithms. Going too far into a specific branch that fails will obviously incur a power penalty, but successes will help with latency and memory parallelism.
The Translation Lookaside Buffer (TLB) in the branch prediction looks for recent virtual memory translations of physical addresses to reduce load latency, and operates in three levels: L0 with 8 entries of any page size, L1 with 64 entries of any page size, and L2 with 512 entries and support for 4K and 256K pages only. The L2 won’t support 1G pages as the L1 can already support 64 of them, and implementing 1G support at the L2 level is a more complex addition (there may also be power/die area benefits).
When the instruction comes through as a recently used one, it acquires a micro-tag and is set via the op-cache, otherwise it is placed into the instruction cache for decode. The L1-Instruction Cache can also accept 32 Bytes/cycle from the L2 cache as other instructions are placed through the load/store unit for another cycle around for execution.
Decode
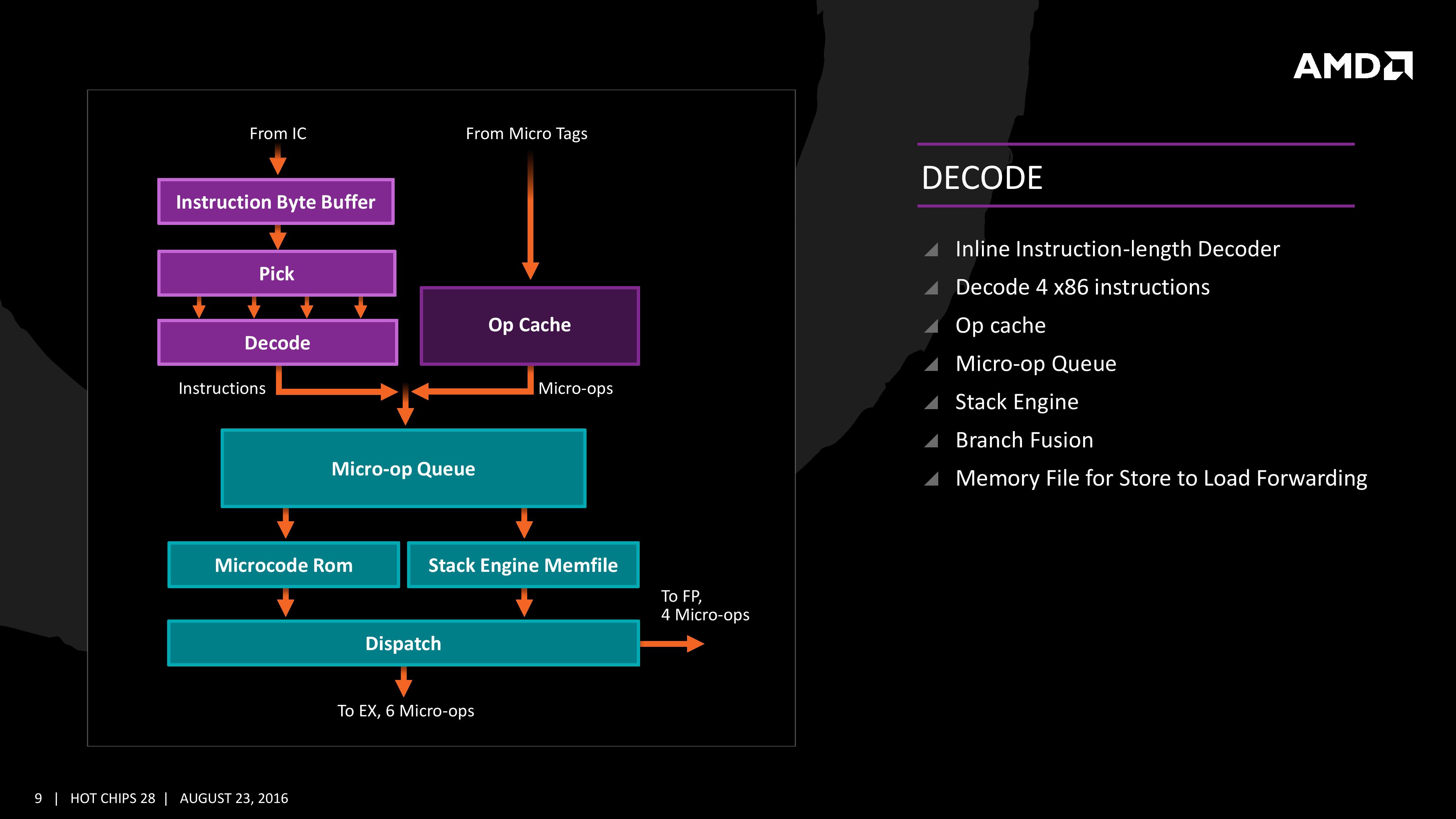
The instruction cache will then send the data through the decoder, which can decode four instructions per cycle. As mentioned previously, the decoder can fuse operations together in a fast-path, such that a single micro-op will go through to the micro-op queue but still represent two instructions, but these will be split when hitting the schedulers. The purpose of this allows the system to fit more into the micro-op queue and afford a higher throughput when possible.
The new Stack Engine comes into play between the queue and the dispatch, allowing for a low-power address generation when it is already known from previous cycles. This allows the system to save power from going through the AGU and cycling back around to the caches.
Finally, the dispatch can apply six instructions per cycle, at a maximum rate of 6/cycle to the INT scheduler or 4/cycle to the FP scheduler. We confirmed with AMD that the dispatch unit can simultaneously dispatch to both INT and FP inside the same cycle, which can maximize throughput (the alternative would be to alternate each cycle, which reduces efficiency). We are told that the operations used in Zen for the uOp cache are ‘pretty dense’, and equivalent to x86 operations in most cases.








106 Comments
View All Comments
Bulat Ziganshin - Wednesday, August 24, 2016 - link
I think it's obvious from number of ALUs that 40% improvement is for scalar single-thread code that greartly bemnefits from access to all 4 integer ALUs. Of course, it will get the same benefit fro any code running up to 8 threads (for 8-core Zen). But anyway it should be slower than KabyLake since Intel spent much more time optimizng their CPUsFor m/t execution, improvements will be much smaller, 10-20%, i think. Plus, 8-core CPU will probably run at smaller frequency than 4-core Buldozers or 4-core KabyLake. AFAIK, even Intel 8c-ore CPUs run at 3.2 GHz only, and it's after many years of power optimization. We also know that *selected* Zen cpus run at 3.2 GHz in benchamrks. So, i expect either < 3 GHz frequency, or 200 Wt power budget
atomsymbol - Wednesday, August 24, 2016 - link
"For m/t execution, improvements will be much smaller, 10-20%, i think."There are bottlenecks in Bulldozer-family when a module is running two threads. An improvement of 40% for m/t Zen execution in respect to Bulldozer m/t execution is possible. It is a question of what the baseline of measurement is.
Bulat Ziganshin - Wednesday, August 24, 2016 - link
M/t execution in Bulldozer already can use all 4 INT alus, so i think that 40% IPC improvement is impossible. In other words, if s/t IPC improved by 40% by moving from 2 alu to 4 alu arrangement, m/t performance that keeps the same 4 alu arrangement, hardly can be improved by more than 20%looncraz - Wednesday, August 24, 2016 - link
IPC is NOT MT, it is ST only.IPC is per-core, per-thread, per-clock, instruction retire rate... which generally equates to performance per clock per core per thread.
Bulat Ziganshin - Thursday, August 25, 2016 - link
you can measure instruction per cycles for a thread, 3 threads, core, cpu or anything else. what's a problem??My point is that s/t speed on Zen is improved much more than m/t speed, compared to last in Bulldozer family. So, they advertized improvement in s/t speed, that is 40%. And m/t improvement is much less since it still the same 4 alus (although many other parts become wider).
atomsymbol - Thursday, August 25, 2016 - link
AMD presentation was comparing Zen to Broadwell in a m/t workload with all CPU cores utilized.From
http://www.cpu-world.com/Compare/528/AMD_A10-Serie...
you can compute that the Blender-specific speedup of Zen over a previous AMD design is about 100/38.8=2.57
Bulat Ziganshin - Thursday, August 25, 2016 - link
Can you compute IPC improvement, that we are discussing here?looncraz - Thursday, August 25, 2016 - link
Except you're absolutely wrong, the performance increases will be much higher for MT than ST.Bulldozer was hindered by the module design, so you had poor MT scaling - not an issue with Zen. On top of that, Zen has SMT, which should add another 20% or so more MT performance for the same number of cores.
A 40% ST improvement for Zen could easily mean a 100% performance improvement for MT.
Bulat Ziganshin - Saturday, August 27, 2016 - link
It's not "on top of that". Zen is pretty simple Bulldozer modification that fianlly allowed to use all 4 scalar ALUs in the module for the single thread. It's why scalar s/t perfroamnce should be 40% faster. OTOH, two threads in the module still share those 4 scalar ALUs as before, so m/t perfromance cannot improve much. On top of that, module was renamed to core. So, there are 2x more cores now and of course m/t performance of entire CPU will be 2x higherNenad - Thursday, September 8, 2016 - link
It is possible that AMD already count SMT (hyperthreading) into those 40%.Their slide which states "40% IPC Performance Uplift" also lists all things that AMD used to achieve those 40%...and first among those listed things is "Two threads per core". So if AMD already counted that into their 40% IPC uplift, then 'real' IPC improvement (for single thread) would be much lower.