Ten Year Anniversary of Core 2 Duo and Conroe: Moore’s Law is Dead, Long Live Moore’s Law
by Ian Cutress on July 27, 2016 10:30 AM EST- Posted in
- CPUs
- Intel
- Core 2 Duo
- Conroe
- ITRS
- Nostalgia
- Time To Upgrade
Core: It’s all in the Prefetch
In a simple CPU design, instructions are decoded in the core and data is fetched from the caches. In a perfect world, such as the Mill architecture, the data and instructions are ready to go in the lowest level cache at all times. This allows for the lowest latency and removes a potential bottleneck. Real life is not that rosy, and it all comes down to how the core can predict what data it needs and has enough time to drag it down to the lowest level of cache it can before it is needed. Ideally it needs to predict the correct data, and not interfere with memory sensitive programs. This is Prefetch.
The Core microarchitecture added multiple prefetchers in the design, as well as improving the prefetch algorithms, to something not seen before on a consumer core. For each core there are two data and one instruction prefetchers, plus another couple for the L2 cache. That’s a total of eight for a dual core CPU, with instructions not to interfere with ‘on-demand’ bandwidth from running software.
One other element to the prefetch is tag lookup for cache indexing. Data prefetchers do this, as well as running software, so in order to avoid a higher latency for the running program, the data prefetch uses the store port to do this. As a general rule (at least at the time), loads happen twice as often as stores, meaning that the store port is generally more ‘free’ to be used for tag lookup by the prefetchers. Stores aren’t critical for most performance metrics, unless the system can’t process stores quickly enough that it backs up the pipeline, but in most cases the rest of the core will be doing things regardless. The cache/memory sub-system is in control for committing the store through the caches, so as long as this happens eventually the process works out.
Core: More Cache Please
Without having access to a low latency data and instruction store, having a fast core is almost worthless. The most expensive SRAMs sit closest to the execution ports, but are also the smallest due to physical design limitations. As a result, we get a nested cache system where the data you need should be in the lowest level possible, and accesses to higher levels of cache are slightly further away. Any time spent waiting for data to complete a CPU instruction is time lost without an appropriate way of dealing with this, so large fast caches are ideal. The Core design, over the previous Netburst family but also over AMD’s K8 ‘Hammer’ microarchitecture, tried to swat a fly with a Buick.
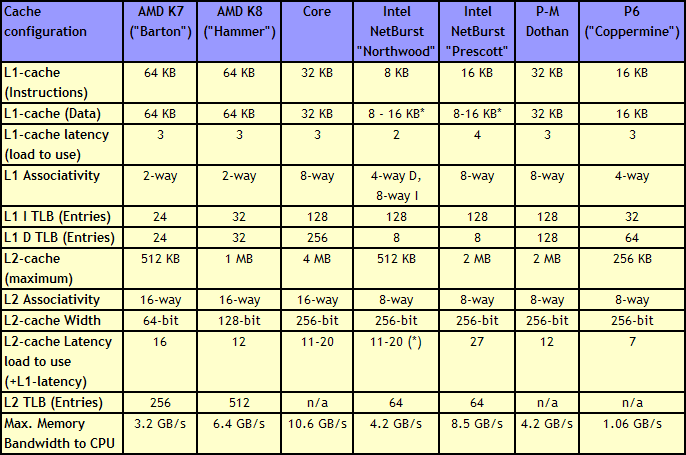
Core gave a 4 MB Level 2 cache between two cores, with a 12-14 cycle access time. This allows each core to use more than 2MB of L2 if needed, something Presler did not allow. Each core also has a 3-cycle 32KB instruction + 32KB data cache, compared to the super small Netburst, and also supports 256 entries in the L1 data TLB, compared to 8. Both the L1 and L2 are accessible by a 256-bit interface, giving good bandwidth to the core.
Note that AMD’s K8 still has a few advantages over Core. The 2-way 64KB L1 caches on AMD’s K8 have a slightly better hit rate to the 8-way 32KB L1 caches on Core, with a similar latency. AMD’s K8 also used an on-die memory controller, lowering memory latency significantly, despite the faster FSB of Intel Core (relative to Netburst) giving a lower latency to Core. As stated in our microarchitecture overview at the time, Athlon 64 X2s memory advantage had gotten smaller, but a key element to the story is that these advantages were negated by other memory sub-system metrics, such as prefetching. Measured by ScienceMark, the Core microarchitecture’s L1 cache delivers 2x bandwidth, and the L2 cache is about 2.5x faster, than the Athlon one.








158 Comments
View All Comments
bcronce - Wednesday, July 27, 2016 - link
My AMD 2500+XP lasted me until a Nahalem i7 2.66ghz. It was a slight.... upgradeartk2219 - Friday, July 29, 2016 - link
Very minor, im sure you barely noticed :).jjpcat@hotmail.com - Wednesday, July 27, 2016 - link
I have a Q6600 in my household and it's still running well.In term on performance, E6400 is about the same as the CPUs (e.g. z3735f/z3745f) used in nearly all cloudbook these days.
Michael Bay - Thursday, July 28, 2016 - link
Yep, I was surprised at that when looking through the benchmarks. Turns out Atom is not so slow after all.stardude82 - Wednesday, July 27, 2016 - link
I've just finished decommissioning all my Core 2 Duo parts, several of which have been upgraded with 2nd hand Sandy Bridge components.Yeah, CPU performance has been relatively stagnant. CPUs have come to where commercial jets are now in their technological development. Jets now fly slower than they did the 1960s, but have much better fuel economy per seat.
Not noted in the E6400 v. i5-6600 comparison is that they both have the same TDP which is pretty impressive. Also, you've got to take inflation into account which would bring the CPU price up to $256 or there about, enough for a i5-6600K.
ScottAD - Wednesday, July 27, 2016 - link
One could argue that while Core put Intel on top of the heap again, Sandy Bridge was a more important shift in design and as a result, many users went from Conroe to Sandy Bridge and have stayed there.That pretty much defines my PC currently. Haven't needed to upgrade. Crazy a decade like nothing.
ianmills - Wednesday, July 27, 2016 - link
When a website has trouble keeping up with current content and instead recycles decades old content.... things that make you go hmm...Ian Cutress - Wednesday, July 27, 2016 - link
I'm the CPU editor, we've been up to date for every major CPU launch for the last couple of years, sourcing units that Intel haven't sourced other websites and have done comprehensive and extensive reviews of every leading x86 development. We have had every Haswell-K (2), Haswell-E(3) Broadwell (2), Broadwell E3 Xeon (3), Broadwell-E (4) and Skylake-K (2) CPU tested and reviewed on each official day of launch. We have covered Kaveri and Carrizo in deep repeated detail over the last few years as well.This is an important chip and today marks in an important milestone.
Hmm...?
smilingcrow - Wednesday, July 27, 2016 - link
Ananand do CPUs very well, can't think of anyone better. Kudos and thanks to you 'guys'."This primarily leaves ARM (who was recently acquired by Softbank)"
They are under offer so not guaranteed to go through and ARM isn't a person. :)
ianmills - Wednesday, July 27, 2016 - link
I agree you do a good job with CPU's. Its some of the other topics that this site has been slowed down in when compared to previous years