The Intel Xeon E5 v4 Review: Testing Broadwell-EP With Demanding Server Workloads
by Johan De Gelas on March 31, 2016 12:30 PM EST- Posted in
- CPUs
- Intel
- Xeon
- Enterprise
- Enterprise CPUs
- Broadwell
A Modest Tick
As Broadwell is a tick - a die shrink of an existing architecture, rather than a new architecture - so you should expect modest IPC improvements. Most Xeon E5 v4 SKUs have slightly lower clockspeeds compared to their Haswell v3 brethren, so overall the single threaded performance has hardly improved. Clock for clock, Intel tells us that their simulation tools show that Broadwell delivers about 5% better performance per clock in non-AVX2 traces.
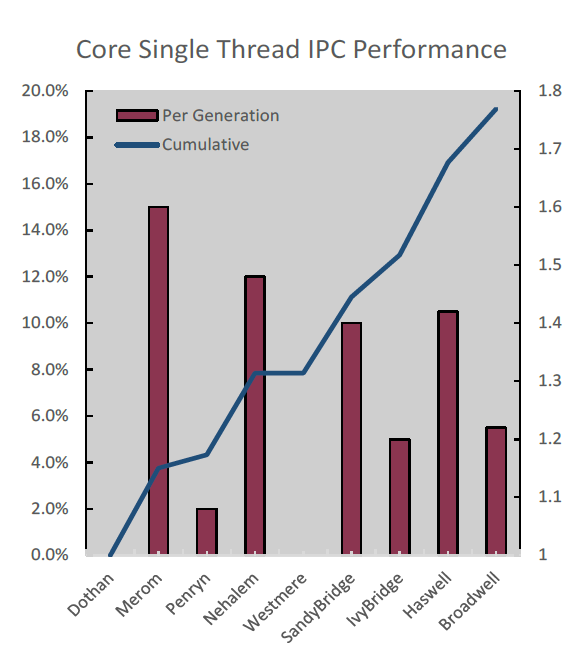
First Y-axis + bars: simulated single threaded performance improvement. Blue line + second Y-axis is the cumulative improvement.
In that sense, Broadwell is basically a Haswell made on Intel's 14nm second generation tri-gate transistor process. Intel did make a few subtle improvements to the micro-architecture:
- Faster divider: lower latency & higher throughput
- AVX multiply latency has decreased from 5 to 3
- Bigger TLB (1.5k vs 1k entries)
- Slightly improved branch prediction (as always)
- Larger scheduler (64 vs 60)
None of these improvements will yield large performance improvements. The larger improvements must come from other features.
New Features
Compared to Haswell-EP, Broadwell-EP also includes some new features. The first one is the improved power control unit.
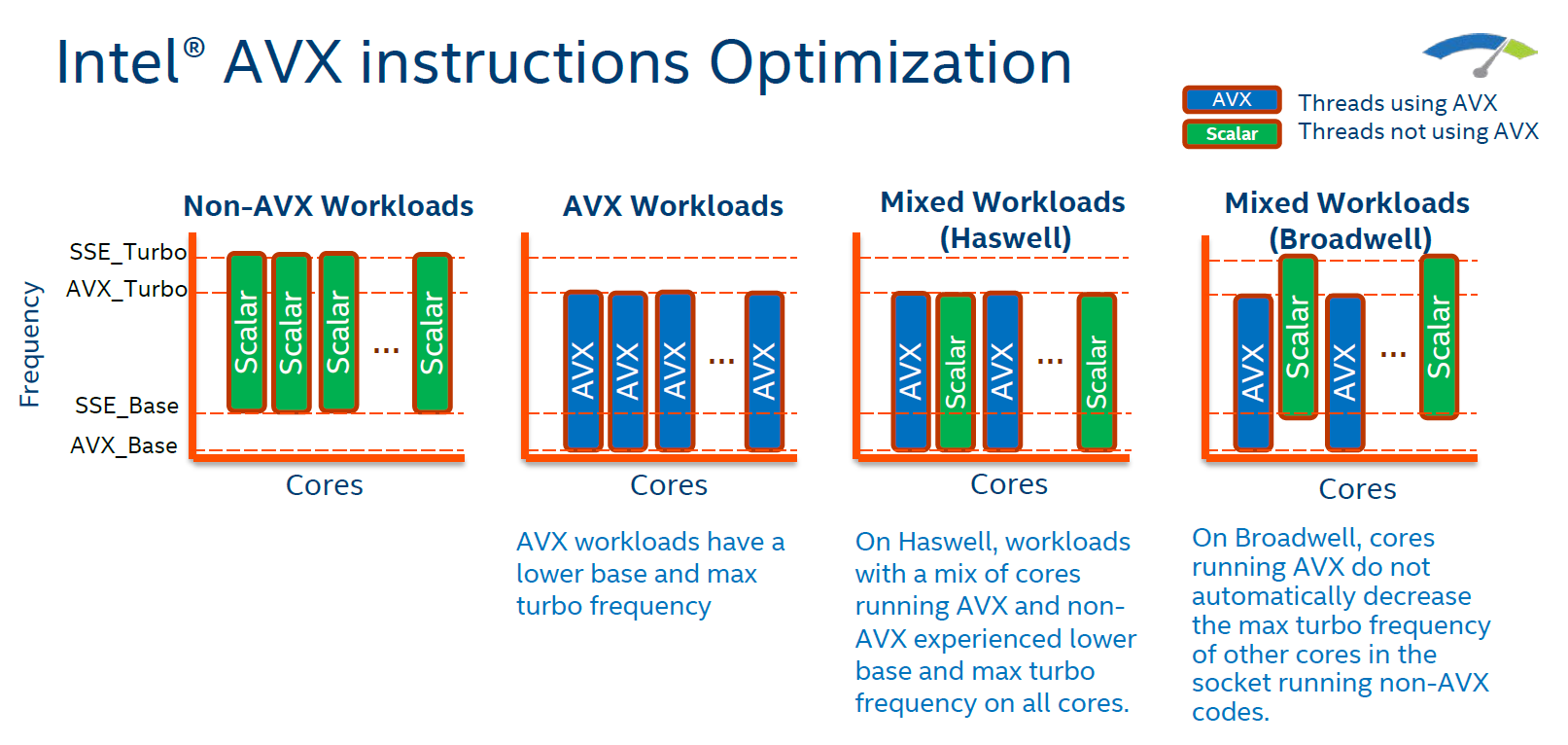
On Haswell, one AVX instruction on one core forced all cores on the same socket to slow down their clockspeed by around 2 to 4 speed bins (-200,-400 MHz) for at least 1 ms, as AVX has a higher power requirement that reduces how much a CPU can turbo. On Broadwell, only the cores that run AVX code will be reducing their clockspeed, allowing the other cores to run at higher speeds.
The other performance feature is the vastly improved PCLMULQDQ (carry-less multiplication) instruction: throughput has been doubled, and latency reduced from 7 cycles to 5.

This increases AES (symmetric) encryption performance by 20-25%, and CRCs (Cyclic Redundancy check) are up to 90% faster. Broadwell also has some new ADCX/ADOX instructions to speed up asymmetric encryption algorithms such as the popular RSA. These improvements are implemented in OpenSSL 1.0.2-beta3. But don't expect too much from it.. The compute intensive asymetric encryption is mostly used to initiate a secure connection. Most modern web applications keep their sessions "alive", and as a result, events that require asymmetric encryption happen a lot less frequentely . Symmetric encryption (like AES) which is used to send encrypted data is a lot lighter, so even on a fully encrypted website with long encrypted data streams, encryption is only a small percentage (<5%) of the total computing load.








112 Comments
View All Comments
SkipPerk - Friday, April 8, 2016 - link
"Anyone putting Microsoft on bare hardware these days is nuts"This brother is speakin the truth!
warreo - Thursday, March 31, 2016 - link
Can someone clarify this line for me?"The average performance increase versus the Xeon E5-2690 is 3%, and the Broadwell cores get a boost of no less than 19%."
Does that mean IPC increase is 19% for Broadwell, offset by ~16% decline in clockspeed to get to 3% average performance increase? But that doesn't make sense to me as a 3.8ghz (E5-2690) to 3.6ghz (E5-2699 v4) is only 5% decline in max clockspeed?
ShieTar - Thursday, March 31, 2016 - link
I understood it as "the -Ofast setting boosts Broadwell by 19%", so with the -O2 setting it was actually 16% slower than the 2690.And I think the AT-Theory based on the original measurements is that the 3.6GHz boost are not even held for a significant amount of time, so that Broadwell in reality comes with an even worse decline in clock speed.
warreo - Thursday, March 31, 2016 - link
Your interpretation makes much more sense than mine, but still doesn't quite add up. The improvement from using -Ofast vs. -O2 is 13% on average, and the lowest improvement is 4% on the xalancbmk, well below the "no less than 19%" quoted by Johan.Perhaps the rest of the disparity is normalizing for sustained clock speeds as you suspect? Johan is that correct?
Ryan Smith - Thursday, March 31, 2016 - link
I've reworded that passage to make it clearer. But ShieTar's interpretation was basically correct."Switching from -O2 to -Ofast improves Broadwell-EP's absolute performance by over 19%. Meanwhile the relative performance advantage versus the Xeon E5-2690 averages 3%. "
JohanAnandtech - Thursday, March 31, 2016 - link
That means that the -ofast has much more effect on the Broadwell. I mean by that that -ofast is 19% faster than -o2 on Broadwell, while it is 3% faster on Sandy Bridge. I assume that the older the architecture, the better the compiler is able to optimize it without special tricks.warreo - Friday, April 1, 2016 - link
Thanks for the clarification. Loved the review, great work Johan!Pinn - Thursday, March 31, 2016 - link
I'm still happy I went with the 6 core x99 over the 8 core. Massive core count is nice to see available, but I don't see the true value. Looks like you have to do the same rough math to see if the clock speed reduction is worth the core count.Oxford Guy - Tuesday, April 5, 2016 - link
Why would there be "true value" for six and not for eight?Pinn - Wednesday, April 6, 2016 - link
Single threaded workloads.