The Intel Xeon E5 v4 Review: Testing Broadwell-EP With Demanding Server Workloads
by Johan De Gelas on March 31, 2016 12:30 PM EST- Posted in
- CPUs
- Intel
- Xeon
- Enterprise
- Enterprise CPUs
- Broadwell
Spark Benchmarking
Spark is wonderful framework, but you need some decent input data and some good coding skills to really test it. Speeding up Big Data applications is the top priority project at the lab I work for (Sizing Servers Lab of the University College of West-Flanders), so I was able to turn to the coding skills of Wannes De Smet to produce a benchmark that uses many of the Spark features and is based upon real world usage.

The test is described in the graph above. We first start with 300 GB of compressed data gathered from the CommonCrawl. These compressed files are a large amount of web archives. We decompress the data on the fly to avoid a long wait that is mostly storage related. We then extract the meaningful text data out of the archives by using the Java library "BoilerPipe". Using the Stanford CoreNLP Natural Language Processing Toolkit, we extract entities ("words that mean something") out of the text, and then count which URLs have the highest occurrence of these entities. The Alternating Least Square algorithm is then used to recommend which URLs are the most interesting for a certain subject.
We tested with Apache Spark 1.5 in standalone mode (non-clustered) as it took us a long time to make sure that the results were repetitive.
Here are the results:
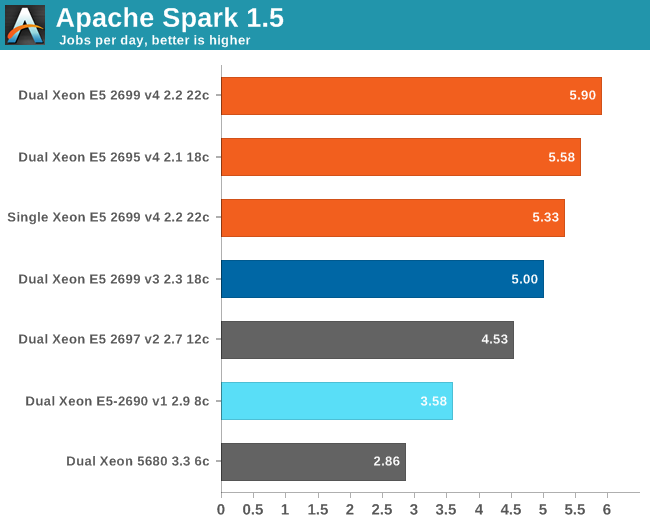
Spark threw us back into nineties, to the time that several workloads still took ages on high-end computers. It takes no less than six and half hours on a 16-core Xeon E5-2690 running at 2.9 GHz to crunch through 300 GB of web data and extract anything meaningful out of it. So we have to express our times in "jobs per day" instead of the usual "jobs per hour". Another data point: a Xeon D-1540 (8 Broadwell cores at 2.6 GHz) needs no less than 11 hours to do the same thing. Using DDR4 at 2400 MHz instead of 1600 MHz gives a boost of around 5 to 8%.
About 10% of the time is spent on splitting up the workload in slices, 30% of the time is spent in language processing, and 50% of the time is spent on aggregating and counting. Only 3% is spent waiting on disk I/O, which is pretty amazing as we handle 300 GB of data and perform up to 55 GB of (Shuffle) writes. The ALS phase scales badly, but takes only 3 to 5% of the time. But there is no escaping on Amdahl's law: throwing more cores gives diminishing returns. Meanwhile the use of remote memory seriously slows processing down: the dual Xeon increases performance only by 11% compared to the single CPU. Broadwell does well here: a Broadwell core at 2.2 GHz is 12% faster than a Haswell at 2.3 GHz.
We are still just starting to understand what really makes Spark fly and version 1.6 might still change quite a bit. But it is clear that this is one of the workloads that will make top SKUs popular: a real killer app for the most potent CPUs. You can replace a dual Xeon 5680 with one Xeon E5-2699 v4 and almost double your performance while halving the CPU power consumption.








112 Comments
View All Comments
patrickjp93 - Friday, April 1, 2016 - link
Knight's Landing: 730 mm^2, also on the 14nm platformextide - Friday, April 1, 2016 - link
Is it really that big..? Wow, I knew it was big, but didn't know it was that big. Got a source on that?Kevin G - Friday, April 8, 2016 - link
I'll second a link for a source. I knew it'd be big but that big?extide - Friday, April 1, 2016 - link
I know you meant Reticle, but that was a pretty funny typo, heh.Kevin G - Friday, April 8, 2016 - link
Autocorrect has gotten the best of me yet again.extide - Friday, April 1, 2016 - link
And, I know how big GM200 and Fiji are, but I am talking about big GPU's on 14/16nm. All signs are currently pointing to <300mm^2 for the first round of 14/16nm GPU's.lorribot - Thursday, March 31, 2016 - link
Given the way Microsoft and others are now licensing by the core and in large non splitable packages (Windows 2016 Datacenter is in blocks of 16 cores, a dual socket server with 44 cores would need 48 core licences) the increasing core count has limited appeal over small numbers of faster cores when looking at virtualised environments.Those still in the physical world will still have to pay per core but may have to buy 4 std Windows licenses.
when it comes to doing your testing, it should reflect these costs and compare total bang per buck when dealing with performance.
Red Hat still licences per socket but don't be surprised if they go per core too.
JohanAnandtech - Friday, April 1, 2016 - link
Back in 2008, I had a sales person explaining the license models of Microsoft to me in our lab. From that point on, we have invested most of our time and resources in linux server software. :-Dextide - Friday, April 1, 2016 - link
Enterprise linux isn't free, either ya knowrahvin - Friday, April 1, 2016 - link
Support isn't free on the FOSS side but the software is. Redhat is never going to charge more per "cores" for support, that's ridiculous and would result in rivals stealing their support contracts. If licensing costs are that bad that you are dumping hardware you really should be looking at moving services to Linux and Visualizing the windows servers so you can limit the core count and provide more horsepower.Anyone putting Microsoft on bare hardware these days is nuts. Although the consolation is that they get to pay MS's exorbitant tax on software. Linux should be the core component of any IT services and virtualized servers where you need proprietary server software.