The Intel Xeon E5 v4 Review: Testing Broadwell-EP With Demanding Server Workloads
by Johan De Gelas on March 31, 2016 12:30 PM EST- Posted in
- CPUs
- Intel
- Xeon
- Enterprise
- Enterprise CPUs
- Broadwell
Spark Benchmarking
Spark is wonderful framework, but you need some decent input data and some good coding skills to really test it. Speeding up Big Data applications is the top priority project at the lab I work for (Sizing Servers Lab of the University College of West-Flanders), so I was able to turn to the coding skills of Wannes De Smet to produce a benchmark that uses many of the Spark features and is based upon real world usage.

The test is described in the graph above. We first start with 300 GB of compressed data gathered from the CommonCrawl. These compressed files are a large amount of web archives. We decompress the data on the fly to avoid a long wait that is mostly storage related. We then extract the meaningful text data out of the archives by using the Java library "BoilerPipe". Using the Stanford CoreNLP Natural Language Processing Toolkit, we extract entities ("words that mean something") out of the text, and then count which URLs have the highest occurrence of these entities. The Alternating Least Square algorithm is then used to recommend which URLs are the most interesting for a certain subject.
We tested with Apache Spark 1.5 in standalone mode (non-clustered) as it took us a long time to make sure that the results were repetitive.
Here are the results:
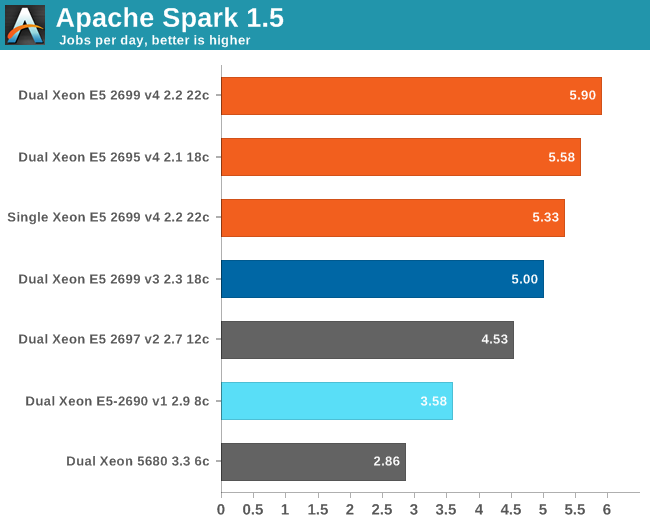
Spark threw us back into nineties, to the time that several workloads still took ages on high-end computers. It takes no less than six and half hours on a 16-core Xeon E5-2690 running at 2.9 GHz to crunch through 300 GB of web data and extract anything meaningful out of it. So we have to express our times in "jobs per day" instead of the usual "jobs per hour". Another data point: a Xeon D-1540 (8 Broadwell cores at 2.6 GHz) needs no less than 11 hours to do the same thing. Using DDR4 at 2400 MHz instead of 1600 MHz gives a boost of around 5 to 8%.
About 10% of the time is spent on splitting up the workload in slices, 30% of the time is spent in language processing, and 50% of the time is spent on aggregating and counting. Only 3% is spent waiting on disk I/O, which is pretty amazing as we handle 300 GB of data and perform up to 55 GB of (Shuffle) writes. The ALS phase scales badly, but takes only 3 to 5% of the time. But there is no escaping on Amdahl's law: throwing more cores gives diminishing returns. Meanwhile the use of remote memory seriously slows processing down: the dual Xeon increases performance only by 11% compared to the single CPU. Broadwell does well here: a Broadwell core at 2.2 GHz is 12% faster than a Haswell at 2.3 GHz.
We are still just starting to understand what really makes Spark fly and version 1.6 might still change quite a bit. But it is clear that this is one of the workloads that will make top SKUs popular: a real killer app for the most potent CPUs. You can replace a dual Xeon 5680 with one Xeon E5-2699 v4 and almost double your performance while halving the CPU power consumption.








112 Comments
View All Comments
Kevin G - Thursday, March 31, 2016 - link
Much like how Apple skipped Haswell-EP, they also skipped a generation of cards from AMD and nVidia. So even if Apple doesn't wait for new GPUs, their is certainly an update on the GPU side.The more interesting possibility would be if Apple were to go with Xeon D in the Mac Pro instead of Broadwell-EP. Apple would need a big PLX chip considering the number of lanes they's want to use but it is possible.
bill.rookard - Thursday, March 31, 2016 - link
Another issue is that they're not under any pressure from any competition to really innovate. I don't even remember the last time I read anything about Opteron servers... let alone something about any NEW Opterons.ComputerGuy2006 - Thursday, March 31, 2016 - link
A sign of things to come for Broadwell-e?Seems like a tricky situation. Because skylake-e will come with a new platform in 2017, while broadwell-e isn't the fastest IPC and there are crazy rumors it will might cost $1500 (lol Intel). We also have Zen later this year that might give good performance with good cost/perf ratio.
extide - Thursday, March 31, 2016 - link
Yeah so Intel only gives us the LCC part for the -E platform, so we will see the 10-core SKU as the top, It will either be $1000, or $1500 ... so yeah not sure how that will end up. Although there will be 8 and 6 core options that should be pretty affordable.Hopefully they do an 8 core part with 28 lanes for under $500, as THAT would be a great deal!
dragonsqrrl - Sunday, April 3, 2016 - link
I'm hoping the 8 core SKU is around $600, the position the x930K traditionally occupies. What makes me a little worried is that there will be 4 SKUs instead of 3 this time (one 10 core, one 8 core, and two 6 core), and I'm not sure there's enough room under the $600 price point for two 6 core processors.jasonelmore - Thursday, March 31, 2016 - link
Can it run Star Citizen?theduckofdeath - Thursday, March 31, 2016 - link
A question we'll never get an answer to? :DJohanAnandtech - Friday, April 1, 2016 - link
It probably runs mostly on Xeons. Well, the back end that is :-)extide - Thursday, March 31, 2016 - link
BOOM, 454mm^2 on the worlds best process. The "other" 14/16nm processes use bigger geometry than Intel's 14nm process.Now we just need those other guys to catch up so we can see 450+mm GPU's!
Kevin G - Thursday, March 31, 2016 - link
Intel still has plenty of room to increase die size. The largest chip they've produced was the Tukwila Itanium 2 at 699 mm^2. Granted that was a 65 nm design but Haswell-EX is a juggarnaught at 662 mm^2 on Intel's more recent 22 nm process. Seems reasonable that SkyLake-EX could go to 32 cores as Intel has >200 mm^2 of rectal limit left.As for GPU's, they're also huge. nVidia's GM200 is 601 mm^2 and AMD's Fiji is 'only' 596 mm^2 both on 28 nm process. TSMC's 20 nm process was skipped so even using the looser 16 nm FinFET, GPU's will see a significant shrink compared to the those high end chips.