The Intel Xeon E5 v4 Review: Testing Broadwell-EP With Demanding Server Workloads
by Johan De Gelas on March 31, 2016 12:30 PM EST- Posted in
- CPUs
- Intel
- Xeon
- Enterprise
- Enterprise CPUs
- Broadwell
Sharing Cache and Memory Resources
In a virtualized environment, the hosted VMs are sharing both the CPU caches and the overall DRAM memory bandwidth. One cache-hungry application can quickly hog most of the shared L3 caches, and a bandwidth intensive one can do the same with the available and shared memory bandwidth. These VMs create the "noisy neighbor" problem. That is bad news for anyone consolidating a lot of VMs on top of a Xeon server, but it is complete show stopper for telco and other scenarios where service providers want to guarantee "Quality-of-Service" (QoS) and thus predictable latency. For Intel this is a notable scenario to address, as the telco market is one of the few markets where the Xeons still have some room to grow. Many telco applications still run on proprietary boxes, which makes virtualization a tantalizing option if Intel can deliver the necessary latency.
Haswell had already some features to monitor cache usage, which in turn allowed you to identify the noisy neighbors. However the "Resource Director Technology" (RDT) of Broadwell can do a lot more.
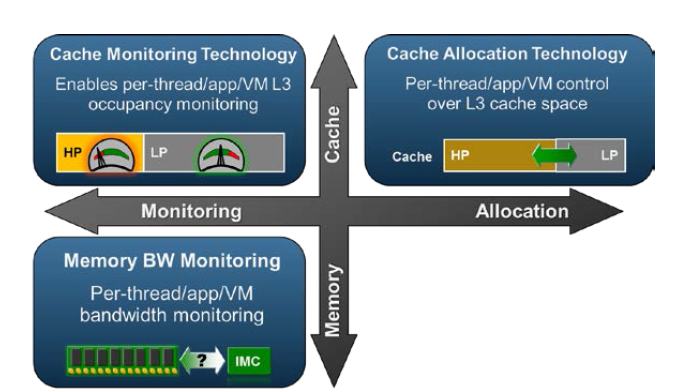
RDT can not only monitor L3 cache usage and memory bandwidth, but it can also allocate L3-cache space on a per thread/process/virtual machine basis. Threads are assigned a Resource Monitoring ID. Eight of these RMID are available per core/cache slice. Sixteen different classes of service can be assigned to an RMID: higher priority threads/applications can get a higher class, and thus a larger portion of the L3-cache.
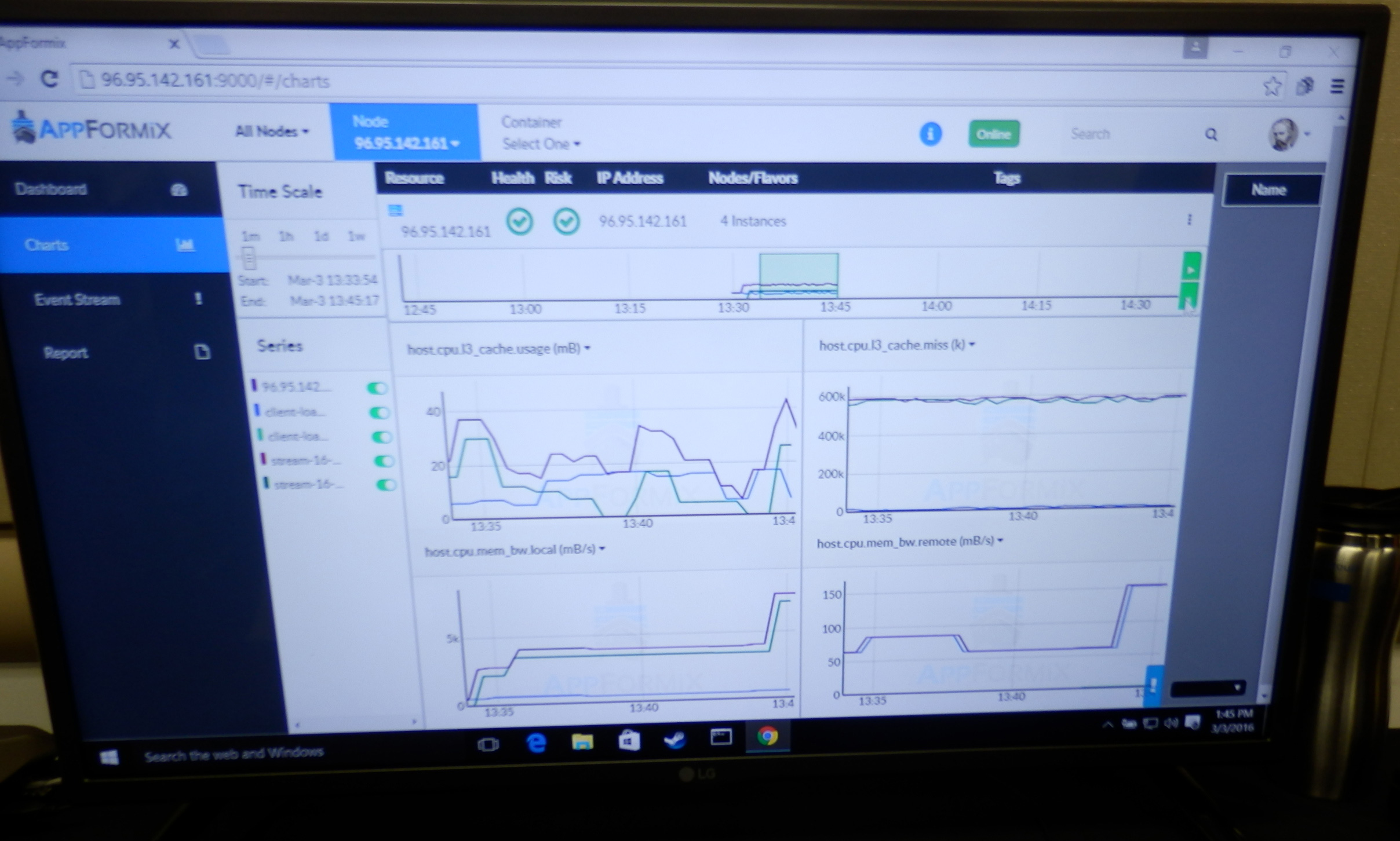
Intel has already demonstrated an application that made use of these new MSRs to read out memory bandwidth and L3 cache consumption on different levels.








112 Comments
View All Comments
Casper42 - Thursday, March 31, 2016 - link
HPE just dropped the 64GB LRDIMMs a week or two back.They are now exactly 2x the 32GB LRDIMM as far as List Price goes.
LRDIMMs across the board are 31% more expensive than RDIMMs.
wishgranter - Tuesday, April 5, 2016 - link
http://www.techpowerup.com/221459/samsung-starts-m...wishgranter - Tuesday, April 5, 2016 - link
While introducing a wide array of 10nm-class DDR4 modules with capacities ranging from 4GB for notebook PCs to 128GB for enterprise servers, Samsung will be extending its 20nm DRAM line-up with its new 10nm-class DRAM portfolio throughout the year.nathanddrews - Thursday, March 31, 2016 - link
Perf/W is obviously a very exciting metric for server farmers and it generally exciting from a basic technology perspective, but it's absolute performance isn't amazing. Anyway, it's not like I'll be buying one anyway. LOLasendra - Thursday, March 31, 2016 - link
This interest me in so far as this would be the updated processors in a supposedly-coming-this-year Mac Pro refresh. Not that I would personally fork that much cash, but I'm interested to see how much of a jump they will make.But things seam rather bleak. No wonder they decided to wait 3 years for a refresh.
MrSpadge - Thursday, March 31, 2016 - link
Not sure which years you're counting in, but for the majority of us it takes 1.5 years from 09/2014 to today.https://en.wikipedia.org/wiki/Haswell_%28microarch...
asendra - Thursday, March 31, 2016 - link
Apple didn't update the MacPros with Haswell-EP. They are still using Ivy Bridgetipoo - Thursday, March 31, 2016 - link
Wonder what they'll do on the GPU side though. Too early for next generation 14nm FF GPUs from anyone, if Nvidia was even a choice due to OpenCL politics. Another GCN 1.0 part in 2016 would be...A bag of hurt.
Still waiting on the high end 15" rMBP to have something better than GCN 1.0...The performance, shockingly, hasn't come all that far from even my Iris Pro model. Maybe double, which is something, but I'd like larger than that to upgrade from integrated...
extide - Thursday, March 31, 2016 - link
Nah, if they refresh it late this year, like in august or something like that, then 14/16nm FF GPU's will be available.At worst we would get GCN 1.2, but yeah it would suck to see 28nm GPU's put in there...
mdriftmeyer - Thursday, March 31, 2016 - link
On what planet do you not grasp FinFET 14nm end of June from AMD?