The Intel Xeon E5 v4 Review: Testing Broadwell-EP With Demanding Server Workloads
by Johan De Gelas on March 31, 2016 12:30 PM EST- Posted in
- CPUs
- Intel
- Xeon
- Enterprise
- Enterprise CPUs
- Broadwell
Spark Benchmarking
Spark is wonderful framework, but you need some decent input data and some good coding skills to really test it. Speeding up Big Data applications is the top priority project at the lab I work for (Sizing Servers Lab of the University College of West-Flanders), so I was able to turn to the coding skills of Wannes De Smet to produce a benchmark that uses many of the Spark features and is based upon real world usage.

The test is described in the graph above. We first start with 300 GB of compressed data gathered from the CommonCrawl. These compressed files are a large amount of web archives. We decompress the data on the fly to avoid a long wait that is mostly storage related. We then extract the meaningful text data out of the archives by using the Java library "BoilerPipe". Using the Stanford CoreNLP Natural Language Processing Toolkit, we extract entities ("words that mean something") out of the text, and then count which URLs have the highest occurrence of these entities. The Alternating Least Square algorithm is then used to recommend which URLs are the most interesting for a certain subject.
We tested with Apache Spark 1.5 in standalone mode (non-clustered) as it took us a long time to make sure that the results were repetitive.
Here are the results:
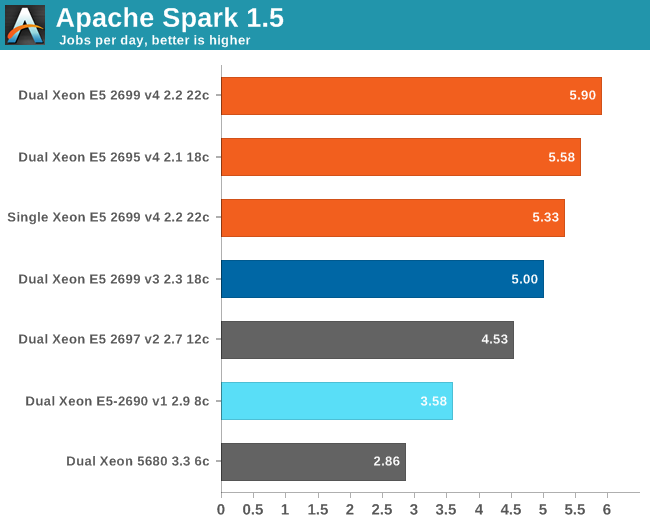
Spark threw us back into nineties, to the time that several workloads still took ages on high-end computers. It takes no less than six and half hours on a 16-core Xeon E5-2690 running at 2.9 GHz to crunch through 300 GB of web data and extract anything meaningful out of it. So we have to express our times in "jobs per day" instead of the usual "jobs per hour". Another data point: a Xeon D-1540 (8 Broadwell cores at 2.6 GHz) needs no less than 11 hours to do the same thing. Using DDR4 at 2400 MHz instead of 1600 MHz gives a boost of around 5 to 8%.
About 10% of the time is spent on splitting up the workload in slices, 30% of the time is spent in language processing, and 50% of the time is spent on aggregating and counting. Only 3% is spent waiting on disk I/O, which is pretty amazing as we handle 300 GB of data and perform up to 55 GB of (Shuffle) writes. The ALS phase scales badly, but takes only 3 to 5% of the time. But there is no escaping on Amdahl's law: throwing more cores gives diminishing returns. Meanwhile the use of remote memory seriously slows processing down: the dual Xeon increases performance only by 11% compared to the single CPU. Broadwell does well here: a Broadwell core at 2.2 GHz is 12% faster than a Haswell at 2.3 GHz.
We are still just starting to understand what really makes Spark fly and version 1.6 might still change quite a bit. But it is clear that this is one of the workloads that will make top SKUs popular: a real killer app for the most potent CPUs. You can replace a dual Xeon 5680 with one Xeon E5-2699 v4 and almost double your performance while halving the CPU power consumption.








112 Comments
View All Comments
PowerOfFacts - Thursday, June 23, 2016 - link
And now Oracle marketing speaks. Their HammerDB results are bogus. Oracle continues to site socket results when the majority of the world has moved on to per core results. They cite the results from a 32 core HammerDB then compare it to a 1 chip (1/2 of 1 socket) POWER8 because Phil has a hard-on for how "HE" believes IBM has packaged the processor and similarly chooses an Intel configuration to ensure "THEY" get the result they want. Phil & Oracle (appear) to always speak with forked tongue.patrickjp93 - Sunday, April 3, 2016 - link
"Best" only at specific scale-up workloads. There's a reason Sparc is not particularly popular for clusters and supercomputing (and it's NOT software compatibility). It sucks at a lot of workloads when compared to x86. As for the SAP benchmarks, that's to be expected since x86 doesn't yet support transactional memories. That changes with Skylake Purley though.Brutalizer - Wednesday, April 6, 2016 - link
In these 25ish benchmarks, the SPARC M7 is 2-3x faster on all kinds of workloads, not just some specific scale up workloads. The reason SPARC M7 is not popular for clusters (supercomputers are clusters) is not because of low raw compute performance, it is because of cost and wattage. The M7 is much more expensive than x86, and draws much more power. I guess somewhere 250 watt or so? M7 are in big enterprise servers, some have water cooling, etc. Whereas clusters have many cheap nodes, with no water cooling.Clusters can have x86 because the highest wattage x86 cpu, uses 140 watt or so. Not more. So it would be feasible to use 140 watt cpus in clusters. But not 250 watt cpus, they draw too much power.
For instance, the IBM Blue Gene supercomputer that hold spot nr 5 in top500 for a couple of years, used 850 MHz powerpc cpus, when everyone else used 2.4 GHz x86 or so. The 850 MHz cpu dont use lot of power, so that is the reason it was used in Blue Gene, not because it was faster (it wasnt). A large supercomputer can draw 10 MegaWatt, and that costs very much. Power is a huge issue in super computers. SPARC M7 draws too much power to be useful in a large cluster, and costs too much.
If we talk about raw compute power for SPARC M7, it reaches 1200 SPECint2006, whereas E5-2699v3 reaches 715 SPECint2006. Not really 2-3x faster, but still much faster.
In SPECfp2006, the M7 reaches 832, whereas the E5-2699v3 reach 474.
https://blogs.oracle.com/BestPerf/entry/201510_spe...
So, as you can see yourself, the SPARC M7 is faster on scale-up business workloads (it was designed for that type of workloads) and also faster on raw compute power. And faster in everything in between. Just look at the wide diversity among these 25 ish benchmarks.
Brutalizer - Wednesday, April 6, 2016 - link
BTW, do you really expect a 150 watt x86 cpu, to outperform a 250 watt SPARC M7 cpu? Have you seen benchmarks where they compare 250 watt graphics card vs a 150 watt graphics card? Which GPU do you think is faster? Do you expect a 150 watt GPU to outperform a 250 watt gpu?The SPARC M7 has 50% more cores, twice the cpu cache, twice the GHz, twice the Wattage, twice the RAM bandwidth, twice the nr of transistors (10 billions) - and you are surprised it is 2-3x faster than x86?
BTW, the SPARC M7 has stronger cores than x86. If you look at all these benchmarks, typically one M7 with 32 cores, is faster than two E5-2699v3 with 2x18 = 36 cores. This must mean that one SPARC M7 core, packs more punch than a E5-2699v3 core, because 32 SPARC cores are faster than 36 x86 cores in all benchmarks.
adamod - Friday, June 3, 2016 - link
i know this is an old post but i am confused (this isnt something i have learned much about yet) i am hoping you can help some...if the sparc has 2 to 3x performance and is 250w compared to 140w then wouldnt that make it MORE efficient? and if you need two 2699's to compare to a sparc m7 then wouldnt that be 280w, more than the 250w of the xeons? i realize there are other factors here but this doesnt make sense to me. also yea there are graphics cards that are a lower wattage and perform better...i am an AMD fan but nvidia has had some faster cards with better performance in the past...i have an R9 280X, a mid grade card rated at i believe 225w, kinda crazy when it can get beaten by 17w nvidia cardstqth - Sunday, April 3, 2016 - link
The SPARC and POWER servers are for people with unlimited pocket where compactness and reliability worth the premium it's spent on. If you have to ask how much it costs, you'd probably can't afford it.Xeons are commodity hardware where you could purchase the best bang for your buck.
They are not aiming at the same market. Most software wouldn't even work on both system.
Besides, benchmarks are worthless - unless the performance of the specific software is tested. And that's rare.
PowerOfFacts - Thursday, June 23, 2016 - link
Depends on which Xeon processors you are referring to. The latest Broadwell EP & EX chips can cost over $7K each. Well on par if not exceeding POWER8 chips and definitely more than OpenPOWER chips. Times are changing. Intel has milked their clients for a long time feeding them the marketing line of open, commodity & low cost. They are no longer open buying up ecosystem integrating into the silicone, what exactly does commodity mean anyway and as low cost goes ... as I just said, pretty salty.yuhong - Thursday, March 31, 2016 - link
64GB LR-DIMMs will probably not come out at reasonable prices until 8Gbit DDR4 is more mainstream.iwod - Thursday, March 31, 2016 - link
I thought Samsung announced a 128GB DIMM with some type of 3D / TSV RAM.Casper42 - Thursday, March 31, 2016 - link
Not shipping just yet though.Should be sometime this year though.