The Intel Xeon E5 v4 Review: Testing Broadwell-EP With Demanding Server Workloads
by Johan De Gelas on March 31, 2016 12:30 PM EST- Posted in
- CPUs
- Intel
- Xeon
- Enterprise
- Enterprise CPUs
- Broadwell
Spark Benchmarking
Spark is wonderful framework, but you need some decent input data and some good coding skills to really test it. Speeding up Big Data applications is the top priority project at the lab I work for (Sizing Servers Lab of the University College of West-Flanders), so I was able to turn to the coding skills of Wannes De Smet to produce a benchmark that uses many of the Spark features and is based upon real world usage.

The test is described in the graph above. We first start with 300 GB of compressed data gathered from the CommonCrawl. These compressed files are a large amount of web archives. We decompress the data on the fly to avoid a long wait that is mostly storage related. We then extract the meaningful text data out of the archives by using the Java library "BoilerPipe". Using the Stanford CoreNLP Natural Language Processing Toolkit, we extract entities ("words that mean something") out of the text, and then count which URLs have the highest occurrence of these entities. The Alternating Least Square algorithm is then used to recommend which URLs are the most interesting for a certain subject.
We tested with Apache Spark 1.5 in standalone mode (non-clustered) as it took us a long time to make sure that the results were repetitive.
Here are the results:
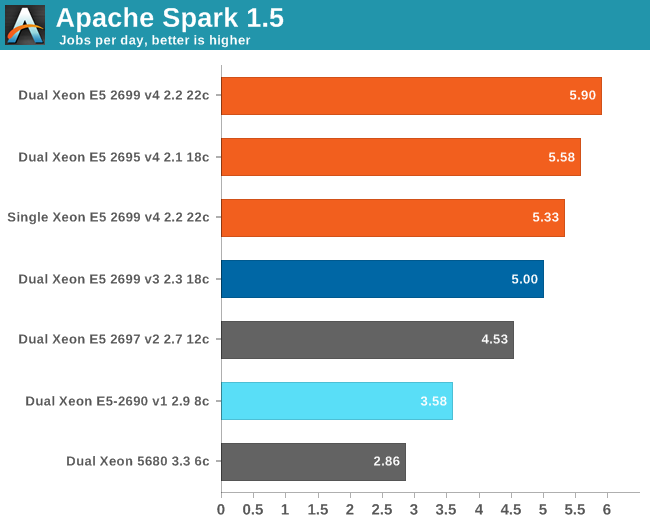
Spark threw us back into nineties, to the time that several workloads still took ages on high-end computers. It takes no less than six and half hours on a 16-core Xeon E5-2690 running at 2.9 GHz to crunch through 300 GB of web data and extract anything meaningful out of it. So we have to express our times in "jobs per day" instead of the usual "jobs per hour". Another data point: a Xeon D-1540 (8 Broadwell cores at 2.6 GHz) needs no less than 11 hours to do the same thing. Using DDR4 at 2400 MHz instead of 1600 MHz gives a boost of around 5 to 8%.
About 10% of the time is spent on splitting up the workload in slices, 30% of the time is spent in language processing, and 50% of the time is spent on aggregating and counting. Only 3% is spent waiting on disk I/O, which is pretty amazing as we handle 300 GB of data and perform up to 55 GB of (Shuffle) writes. The ALS phase scales badly, but takes only 3 to 5% of the time. But there is no escaping on Amdahl's law: throwing more cores gives diminishing returns. Meanwhile the use of remote memory seriously slows processing down: the dual Xeon increases performance only by 11% compared to the single CPU. Broadwell does well here: a Broadwell core at 2.2 GHz is 12% faster than a Haswell at 2.3 GHz.
We are still just starting to understand what really makes Spark fly and version 1.6 might still change quite a bit. But it is clear that this is one of the workloads that will make top SKUs popular: a real killer app for the most potent CPUs. You can replace a dual Xeon 5680 with one Xeon E5-2699 v4 and almost double your performance while halving the CPU power consumption.








112 Comments
View All Comments
isrv - Sunday, April 3, 2016 - link
i will belive that only after one by one comparison E5-1630v3 vs any of E5v4 composing wordpress front page for example.and so far, that's only a words about better caching etc...
simplyfabio - Monday, April 4, 2016 - link
Could I ask one thing here? For a Workstation 3D, both for rendering and graphic/cad, (like illustrator, photoshop, autocad, 3dsmax), could be better have more core like the E5 2690 (considering all the turbo clock speed for each core active) ore better frequency, like the 1680? Thanks a lot to everyone, I can't find a nice review on this side of this CPUs...grantdesrosiers - Monday, April 4, 2016 - link
Not sure if anyone has pointed it out yet, but I think there is an error on the "Multi-Threaded Integer Performance" page, first graph. The 2695v4 says 22 cores, I believe it should be 18.SanX - Monday, April 4, 2016 - link
Poor Moore's law for workstations... 10-20% gain per 2-years generation.Think about it: there is no reason to upgrade for the next *** 5-10 generations *** or the next 10-20 years (!!!) when the processors will be only e-fold (2.71x) faster.
dragonsqrrl - Monday, April 4, 2016 - link
The problem is your first assumption is already false.Khenglish - Monday, April 4, 2016 - link
I can't understand why the 4C and under turbo speeds are so slow on the v4 2699. A Broadwell with 55MB of cache being outperformed by a stock clocked Sandy Bridge is ridiculous. Why would this CPU not clock up to at least 4.2GHz with a 4 core workload, and say 4.4GHz for a 1 core workload? Hell it costs over $4000 and a massive TDP. You'd think Intel could take a minute to make the low core count speeds not terribly low.My workstation in my lab has a 1650 v3. My workloads peak between 4-8 cores. There is not a single CPU in the v4 lineup that would be an upgrade over the 1650 v3 despite the major power savings of 14nm and the cache size increase due to Intel's inability to set reasonable 8C and under frequencies.
Romulous - Monday, April 4, 2016 - link
People who are serious about recompiling the same software often would probably use ccache and maybe even distcc. So your Linux kernel compile test is really only there for to show potential cpu performance.LHL2500 - Tuesday, April 5, 2016 - link
"It finds a home in the same LGA 2011-3 socket."Not according to Intel's website.
http://ark.intel.com/compare/91754,81908
In this comparison between a v3 and a v4 version of a E5-2680, the socket support for the two chips are different. The older version using the the FCLGA2011-3 and the newer version using FCLGA2011.
So who is right? Anandtech or Intel?
And it not just this chip. It's all the v4s.
While I hope it's a typo on Intel's behalf, for now it doesn't look like the v4s are direct upgrades to the v3s. You will apparently need new motherboards.
xrror - Tuesday, April 5, 2016 - link
That... is a bit disconcerting. I also like how "VID Voltage Range" for the v4 parts is simply listed as "0" ...SeanJ76 - Tuesday, April 5, 2016 - link
My School had the 3rd Generation Xeon's in their Workstations, they were slow as fuck@3.3ghz!! The consumer i7 4790K/6700K would run laps around these Xeon crap cpus!