AMD's Hammer Architecture - Making Sense of it All
by Anand Lal Shimpi on October 23, 2001 2:57 AM EST- Posted in
- CPUs
Vastly Improved Branch Predictor
Don't be fooled; just because the Hammer's pipeline is only 12 stages long doesn't mean that AMD won't need an improved branch prediction unit to prevent the 20% longer pipeline from reducing IPC in situations where conditional branches are not easily predictable. Remember that a mispredicted branch in the Hammer faces a 20% longer penalty than the K7 making it very important for the Hammer to receive an improved branch prediction unit; and that it does.
You'll remember that one of the more elegant ways Intel had of dealing with branch mis-predict penalties is by the introduction of an execution Trace Cache. This cache stores instructions in their decoded form, in the order of execution so that a branch mis-predict won't result in another set of time consuming decoding steps. The trace cache actually works very well for the Pentium 4's target market: the single processor mainstream and performance desktop markets. However AMD is quick to point out that when it comes to what they call "large workloads," the trace cache isn't as efficient. AMD's definition of large workloads include programs with large datasets such as scientific calculations or a series of smaller programs that together act as a large workload for the processor. Examples of this would be a system running many concurrent operations such as a power user's desktop or workstation computer or even something like a SQL database server where many smaller transactions are taking place at once.
Before we go any further we have to see if there are indeed any merits to AMD's claims of inefficiencies of the trace cache when it comes to large workloads. In our original 760MP review we ran three different iterations of CSA Research's Office Bench 2001; each subsequent iteration had a significantly increased workload that was mainly governed by the number of processes being run. For example, the baseline performance tests had no background tasks running while the loading level 2 tests had multiple instances of windows media player and many concurrent DB accesses among other loading tools. All theoretical indications would put the Intel Xeon 1.7GHz processor on top of the Athlon MP 1.2GHz processor (both 1P systems) in terms of how well they can handle the additional load. The Xeon (like the Pentium 4), has much more FSB and memory bandwidth which will easily be stressed by this test.
With the second iteration of the test, the loading level was set to 1 or a medium application load. In comparison to the baseline test, both the Athlon MP 1.2 and the Xeon 1.7 were 39% slower with the newly added load. Cranking up the notch yet again however revealed that the Xeon was 3.1x slower than the unloaded Xeon while the Athlon MP was only 2.7x slower than its unloaded counterpart. It would be silly for us to assume that this discrepancy is due to the inability of the trace cache to perform well in heavily loaded scenarios but it does present a possible support for the argument.
Unlike the Pentium 4, AMD's Hammer must be a one size fits all solution to AMD's entire product line going forward. It will go up against the Itanium in 4 and 8 processor servers while at the same time a version will eventually be used in the mobile and entry-level desktop markets. AMD is first going to introduce Hammer to the high end workstation and server markets where the laws of large workloads apply and they make it a point to state that a trace cache isn't a solution for them.
Instead AMD has vastly improved the arguably crippled branch prediction unit of the Athlon in the Hammer. The branch target array has the same 2K entry limit and 12-entry return stack as the Athlon, but the unit itself has been improved tremendously. For starters, the Hammer has these branch selectors which are bits stored in the L1 cache that contain information about where branches in the code exist and what type of branches they are. These branch selectors also have an additional bit that can flag the branch as static thus allowing the processor to predict it statically. A static branch is one whose outcome is almost always known, such as a branch to error codes in a program and thus it makes little sense to do any guesswork in predicting whether that branch will be taken or not. This helps prevent the global history counter, a collection of the history of branches to aid in prediction, from becoming cluttered with unnecessary information since when the processor branched to a particular error code will not help predict any non-static branches in the code later on.
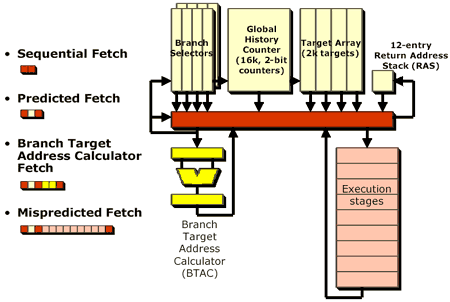
The final feature of the Hammer's branch prediction unit is a bit of logic called the Branch Target Address Calculator (BTAC). Before we explain this it's important to note what the Itanium does when faced with multiple conditional branches; the Itanium is a very powerful monster and has the power to evaluate various chunks of code simultaneously, including both conditions of a branch, and at the end of it all choose the "correct" data and discard what is useless instead of predicting where the branch will take the CPU. For example, let's assume that these instructions are sent to an Itanium optimized compiler:
…
3*4
Load Data from Memory Address A into Register 5
If Register 5 is negative then branch to Case 1, else branch to Case 2
Case 1:
12*6
Case 2:
1+1
…
The above snippet wasn't meant to be complex code at all but it can be used to show you how the Itanium would work. Intel's Itanium would execute both Case 1 and Case 2, determine the value in R5 and discard whichever case would not be used. The Hammer isn't engineered in an entirely different manner; while it won't even attempt to extract the level of parallelism in the code that the Itanium does, what it will do is attempt to better predict the outcome of branches. In this case, the Hammer would calculate the direction a branch appears to be taking and use its Branch Target Address Calculator to actually calculate the branch. This little distraction only eats up around 5 clock cycles and dramatically improves the efficiency of the processor's ability to predict branches by removing some of the guesswork and actually calculating the direction and path of a branch. As you might be able to guess, this is another source of increased IPC with the Hammer.








1 Comments
View All Comments
chowmanga - Tuesday, February 2, 2010 - link
Anand, the link on page 2 leading to the discussion on the 64bit extension of the x86 is broken. Is there any way to read it?